| ||
D-Lib Magazine
|
|
|
G. Sayeed Choudhury
Michael Droettboom |
![]()
Introduction
The Lester S. Levy Collection of Sheet Music represents one of the largest collections of sheet music available online.1 The Collection, part of the Special Collections2 of the Milton S. Eisenhower Library (MSEL) at Johns Hopkins University, comprises nearly 30,000 pieces of music which correspond to nearly 130,000 sheets of music and associated cover art. It provides a rich, multi-faceted view of life in late 19th and early 20th century America, featuring famous songs such as "The Star-Spangled Banner", "Hail Columbia", and "Yankee Doodle Dandy" along with engravings, lithographs, and many forms of early photo reproduction on song covers. Scholars from various disciplines have used the Collection for both research and teaching; the online collection, described below, has proven popular with the general public as well. In the early 1990s, the MSEL considered the need for preservation of the Collection, while respecting the need for continued access. Accordingly, the MSEL evaluated two ideas to meet the dual goals of enhancing access while reducing the handling of the physical collection-microfilming and digitization. With funding from the National Endowment for the Humanities (NEH)3 in 1994, the Milton S. Eisenhower Library began the process of digitizing the Levy Collection. While there is now a reasonable amount of experience with digitization of library collections, this was not the case in 1994. Not only is the Levy Collection a relatively large online collection, it is also one of the first major digitization efforts by an academic research library. The Levy (Phase I) Project team initially hired a subcontractor to implement and manage the digitization. Both the subcontractor and the Levy team realized some rather "painful" lessons regarding large-scale digitization projects. The workload associated with digitizing the Levy Collection, especially the process of inspecting, editing, and correcting images and attaching appropriate metadata, proved onerous and overwhelming. In fact, the subcontractor declared bankruptcy, leaving the responsibility for completing the digitization with the Levy team. In the final report to NEH, the Curator of Special Collections at the MSEL stated, "the most useful thing we learned from this project was that you can never overestimate the amount of time it will take to create a quality digital product" (Requardt 1998). The word "resources" might represent a more comprehensive choice than the word "time" in this previous statement. This "sink" of time and resources manifested itself by an increasing allocation of human labor and time to deal with workflow issues related to large-scale digitization. The Levy Collection experience provides ample evidence that there will be mistakes during and after digitization and that unforeseen challenges or difficulties will arise, especially when dealing with rare or fragile materials. The current strategy of allocating additional human labor neither limits costs nor scales well. Consequently, the Digital Knowledge Center (DKC)4 of the Milton S. Eisenhower Library sought and secured funding for the development of a workflow management system through the National Science Foundations (NSF)5 Digital Libraries Initiative, Phase 2 and the Institute for Museum and Library Services (IMLS)6 National Leadership Grant Program. The Levy family and a technology entrepreneur in Maryland provided additional funding for other aspects of the project. The mission of this second phase of the Levy project ("Levy II") can be summarized as follows:
The cornerstones of the workflow management system include: optical music recognition (OMR) software to generate a logical representation of the score -- for sound generation, musical searching, and musicological research -- and an automated name authority control system to disambiguate names (e.g., the authors Mark Twain and Samuel Clemens are the same individual). The research tools focus upon enhanced searching capabilities through the development and application of a fast, disk-based search engine for lyrics and music, and the incorporation of an XML structure for metadata. Though this paper focuses on the OMR component of our work, a companion paper to be published in a future issue of D-Lib will describe more fully the other tools (e.g., the automated name authority control system and the disk-based search engine), the overall workflow management system, and the project management process. Optical Music RecognitionThe philosophy of the Levy II project comprises the reduction, not elimination, of human intervention in the workflow of a large-scale digitization project. Our optical music recognition (OMR) software exemplifies this philosophy. Compared to commercial OMR systems, it offers several advantages which are highly relevant in the context of the Levy II workflow management system. The OMR software is:
The entire OMR process begins with graphic images for its input and eventually produces both GUIDO (Hoos and Hamel 1997) and MIDI (MIDI 1986) files, along with a file of full-text lyrics. GUIDO and MIDI represent non-proprietary file formats. GUIDO allows the encoding of many different layers of detail in a musical score, including both its auditory and visual aspects. This allows for seamless interchange between music notation editing applications. MIDI provides low-bandwidth transmission of music over the Internet so users can listen to music with their web browsers (Choudhury, et al. 2000). Our optical music recognition (OMR) system consists of two components: Adaptive Optical Music Recognition (AOMR) System (Fujinaga 1996b). AOMR is responsible for recognizing and classifying musical symbols (e.g., staves, clefs, notes) from a page image. Optical Music Interpretation (OMI) System (Droettboom and Fujinaga 2001). OMI organizes and interprets the symbols from AOMR into their musical "meanings". For example, a half note on the third staff line, preceded by a bass clef with no key signature and a 4/4 time signature, "means" to play a D for two beats. Optical Music Recognition OverviewBefore providing the details of the OMR process, which may be difficult to understand without a background in music, it will be helpful to present a general summary. Before batch processing can begin, AOMR must be "trained" to recognize the various symbols. A human feeds pages from the training set to AOMR and makes corrections in the training interface when AOMR makes classification mistakes. Once this process is completed, the training data is fed into a genetic algorithm, which "tunes" the training data to improve accuracy. Once the initial training is completed, the system is ready to perform batch processing on a large scale. The AOMR process is performed for each music page image in the collection:
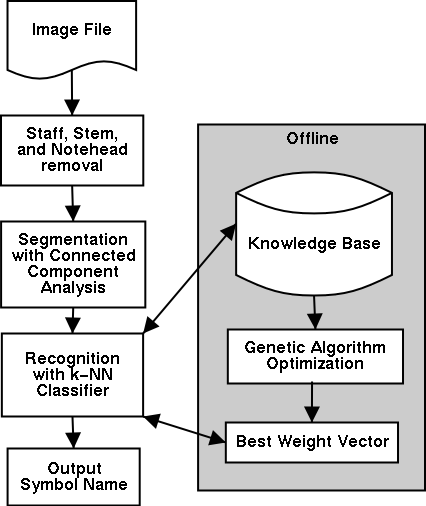
The overall architecture of the adaptive optical music recognition (AOMR) system is depicted in the figure below.
The OMI process is executed once for each complete musical score, which might comprise multiple pages. The Levy Collection, for example, averages about four music pages per piece.
An online guided tour of the AOMR/OMI process is available.7 Optical Music Recognition in DetailTraining PhaseAOMR is pre-configured with basic knowledge, but will perform better with a short period of supervised learning on a representative training set selected from the collection to be processed. In this interactive session, AOMR processes pages normally (as described in the next section), but is corrected by a human each time it makes a mistake. The list of matching features and the associated symbol classifications are saved for the exemplar-based symbol classifier and for later processing by a genetic algorithm (GA). Once all the pages from the training set have been processed, the GA can be applied to the training data. The role of the GA is to pick a near-optimal weight (or relative importance) for each of the features used in the k-nearest neighbor (k-NN) classifier. This data is stored for later use by AOMR. GA's are often used when an exhaustive search of appropriate weights is impossible or prohibitive (Fujinaga 1996a). After the training has been completed and weights have been assigned to each of the features, AOMR is ready to process all the pages in the collection. Adaptive Optical Music Recognition Process Because staff lines are pervasive, relatively easy to locate, and because they make it difficult to recognize other symbols, they are removed first. They are identified by organizing the image into lists of vertical "runs" of pixels with a technique known as run-length coding, and then using projection analysis to locate short vertical runs with long horizontal widths. If the staff lines do not project straight across the page, then the page is said to be skewed. Using the information gathered in this process, the image is de-skewed (or straightened) and the staff lines are removed. Stave coordinates and line spacing data is stored for later use. Figure 4 below has staff lines removed.
Text, including performance indications and lyrics, is removed using some heuristics (e.g., aspect ratio, minimum height and width, and side-by-side placement). Runs of text are removed and stored as bounding box coordinates so that the text tokens may be fed to an OCR process later. This will allow the capture of lyrics, multi-letter dynamic markings, and other performance information. Text has been removed from the image in Figure 5 below..
Using run-length coding and connected component analysis (Fujinaga 1996b), stems, barlines, and solid (black) noteheads are detected and removed. Tall narrow elements indicate stems and barlines, while "square-ish" components with a preponderance of black represent solid noteheads. The remaining symbols (Figure 6) will be handled by the k-NN classifier.
After the easier symbols have been removed, connected component analysis is performed on the new intermediate image to segment the remaining symbols and marks. Each of the symbols is classified by the k-NN algorithm. The k-NN algorithm is used to implement the exemplar-based classifier that makes AOMR adaptive. k-NN works by calculating the distance between the feature vector of the unclassified symbol and the feature vector of each of the symbols manually classified during the training phase. The class indicated by most of the closest neighbors is assigned to the symbol being tested. After the remaining symbols have been processed, all of the symbols collected by AOMR (staves, text, noteheads, clefs, etc.) are stored for later interpretation by OMI. This process is repeated for each page in a musical score. Optical Music Interpretation ProcessNow that AOMR has processed all the pages of a score, all the symbols from that score are available for interpretation. OMI begins by reading the text and symbol classification information provided by AOMR. OMI refers to these text and symbol objects as glyphs. The content of each of the text tokens is extracted from the original image. We plan to implement an interface to send these tokens' images to an external OCR program. Once that interface is completed, both the text image and OCR results will be attached to the corresponding text glyph. Next, the glyphs need to be sorted into temporal, or time, order. In order to do this, and to establish relationships with other glyphs, each glyph must be associated with a staff. The glyphs are sorted in time order, by part, voice, and staff. Glyphs that occur at the same vertical position on the same staff (as in a chord) are ordered from top to bottom. Doing so makes melodic searching easier, since the melody is more likely to follow the highest pitches. With the glyphs organized in temporal order by staff, it is now possible to determine relationships between glyphs. These connections are important for inferring the musical meaning of related sets of symbols. To facilitate this, OMI implements an object-oriented class hierarchy in which the base classes are named by the abilities or properties that we wish to project onto the derived glyph classes. For example, all noteheads can have a stem, and thus are derived from the STEMMABLE class, which is in turn derived from several other classes, and so on. This scheme allows OMI to join a stem to an appropriate and properly adjoining object by asking that object if it can have a stem. A notehead object will indicate that it can, and the relationship will be established. Rests, however, are not derived from the STEMMABLE class, thus any rest in similar proximity would tell OMI that it cannot be stemmed. This technique allows the reference assignment code to work in a highly abstract way, on a wide variety of glyph classes. An example serves to illustrate the importance of the interaction between the various glyphs. A quarter note followed by a dot should be treated as a single logical entity. The dot augments the quarter notes duration by half, so clearly it is important to know the relationship of these two glyphs. However, we will not know the true time duration of this dotted quarter note until we determine time-related context information -- such as the tempo and time signature -- that is in effect when this glyph appears. Further, we will not know which pitch to voice until we determine the clef (e.g., treble, base, alto); the noteheads position relative to the staff; the last preceding accidental (e.g., sharp, flat, natural) for that note in the same measure; and, in the absence of any accidentals, the key signature. Armed with the full musical meaning of the collection of glyphs, OMI can apply rules to detect errors in the music and possibly correct them. For example, under most circumstances OMI can detect and sometimes correct errors that result in too few or too many beats occurring in a measure. A group of seven algorithms implements this functionality. In the future, new rules may be implemented to further improve (or at least measure) the accuracy of the process, and further reduce the amount of human intervention required. Finally, OMI produces a representation of the music as output. Furthermore, because OMI implements a plug-in architecture for output processing, the results can be tailored to the needs of the user. Output methods for each glyph class are merged from the backend into the core glyph classes. Since output formats differ in the ordering and encoding of musical objects, the output processor is first given the opportunity to reorder the glyph list before the output method is called for each glyph. We have chosen to use GUIDO in our project; consequently, an output plug-in has been developed for this format. However, other output processors are planned. GUIDO was chosen because of its representational completeness (auditory, visual, and logical aspects of the score), its non-proprietary definition, and its text-based, human-readable syntax. Optical Character RecognitionAs stated above, AOMR extracts the text tokens, when present, from the images of sheet music. This feature represents an advantage over commercial OMR systems and provides the possibility to incorporate automated tools for dealing with full-text lyrics. Our team considered and evaluated optical character recognition (OCR) software for this purpose, focusing on performance and integration into the open-source workflow management system. The OCR software was used to recognize and export text strings from the text tokens that were generated by AOMR from the sheet music images. We identified several open-source OCR systems, and felt two packages offered the most mature systems, SOCR8 and GOCR.9 We were unable to compile SOCR, but were able to compile and perform tests using GOCR. Commercial OCR software was also considered, based on a hypothesis that commercial software might offer superior performance (e.g., accuracy). The Perseus Project10 team has identified Prime Recognition11 as effective OCR software; however, it runs only on proprietary operating systems (Windows NT, version 4.0 or Windows 2000). Consequently, we evaluated OCR Shop12 and Pixel!OCR,13 two commercial OCR packages that run on Linux. OCR Shop had difficulty with the text tokens. Specifically, it performed well with test images with "standard" amounts of text (i.e., the typical number of words found on an average page), but locked up with the tokens. Pixel!OCR managed to recognize lyrics from the text tokens and performed better than GOCR. Though Pixel!OCR runs on Linux and outperformed GOCR, we still hoped that a fully open-source option would be possible. Given the nature of the text tokens, we speculated that standard OCR software faced problems with syllables and other "incomplete" words. OCR Shops good performance with standard images of text and poor performance with AOMR text tokens reinforced this idea. OCR Shop, like other OCR packages, seemed to search for words based on its recognition of individual letters. In the case of AOMR-generated text tokens, often featuring only a syllable of a word, the software seemed to lack the necessary context to recognize the characters. Realizing that AOMR recognizes individual symbols, we began to explore the possibility of using AOMR as an OCR system. Based on preliminary tests, the AOMR system has outperformed GOCR, the open-source OCR system. Further tests of AOMR, GOCR, and Pixel!OCR will be conducted. However, the initial tests provided enough encouragement to pursue the AOMR as an OCR system for the Levy II project. If AOMR performs well, it will be possible to retain the open-source nature of the workflow management system while ensuring a reasonable level of performance. OMR DeliverablesAfter the overall optical music recognition process (AOMR and OMI), the following are available:
ConclusionOptical music recognition is a critical component for building strong online collections that include musical scores. Without it, collection managers would have to either limit end-user searching to descriptive metadata or bear the expense of manually transcribing and encoding their collections to provide music searching, lyric searching, and online playback. Though critical, OMR is only one of the tools that will be integrated into the Levy II workflow management system. As was mentioned earlier, a companion paper will discuss our process for project planning, the automated name authority control tool, and the overall framework for the workflow management system itself. ReferencesChoudhury, S., T. DiLauro, M. Droettboom, I. Fujinaga, B. Harrington and K. MacMillan. 2000. Optical music recognition system within a large-scale digitization project. ISMIR 2000 Conference. <http://ciir.cs.umass.edu/music2000/papers/choudhury_paper.pdf> Droettboom, M. and I. Fujinaga. 2001. Interpreting the semantics of music notation using an extensible and object-oriented system. (To be published in Proceedings of the 9th Python Conference). Fujinaga, I. 1996a. Exemplar-based learning in adaptive optical music recognition system. Proceedings of the International Computer Music Conference: 55-6. Fujinaga, I. 1996b. Adaptive optical music recognition. Ph.D. thesis, McGill University. Hoos, H. H. and K. A. Hamel. 1997. The GUIDO music notation format version 1.0, Specification Part 1: Basic GUIDO. Technical Report TI 20/97, Technische Universität Darmstadt. <http://www.informatik.tu-darmstadt.de/AFS/GUIDO/docu/spec1.htm> Martin, L. and H. H. Hoos. 1997. gmn2midi, version 1.0. Computer Program (Microsoft Windows, Apple Macintosh OS, IBM OS/2, UNIX). <http://www.informatik.tu-darmstadt.de/AFS/GUIDO/>. MIDI. 1986. The complete MIDI 1.0 specification. MIDI Manufacturers Association, Inc. <http://www.midi.org/> Requardt, C. 1998. Preservation of and automated access to the Lester S. Levy Collection of Sheet Music. NEH Final Performance Report PS-20945-95 (March). Notes[1] The Lester S. Levy Collection of Sheet Music, <http://levysheetmusic.mse.jhu.edu/> [2] Special Collections, Milton S. Eisenhower Library, <http://archives.mse.jhu.edu:8000/> [3] National Endowment for the Humanities, <http://www.neh.gov/> [4] Digital Knowledge Center, Milton S. Eisenhower Library, <http://dkc.mse.jhu.edu/ [5] National Science Foundation, <http://www.nsf.gov/> [6] Institute of Museum and Library Services, <http://www.imls.gov/> [7] An online guided tour of the AOMR/OMI process is available. <http://mambo.peabody.jhu.edu/omr/demo/> [8] SOCR optical character recognition, <http://www.socr.org/> [9] GOCR optical character recognition, <http://jocr.sourceforge.net/> [10] The Perseus Project, <http://www.perseus.tufts.edu/> [11] Prime Recognition (PrimeOCR), <http://www.primerecognition.com/> [12] Vividata (OCR Shop) optical character recognition software, <http://www.vividata.com/> [13] Mentalix Pixel!OCR optical character recognition software, <http://www.mentalix.com/> Copyright© 2001 G. Sayeed Choudhury, Tim DiLauro, Michael Droettboom, Ichiro Fujinaga, and Karl MacMillan |
|||
|
Top
| Contents |
|||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/february2001-choudhury
|