|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Richard Anderson Hannah Frost Nancy Hoebelheinrich Keith Johnson Stanford University |
![]()
|
The Archive Ingest and Handling Test (AIHT) was a project devised and funded by the Library of Congress to generate data and knowledge from the practical experiences of four institutions whose evolving digital preservation infrastructures were used to handle a small real-world digital archive. Since the Library of Congress intends to make public the complete final report on the AIHT – including Stanford's full report – later this year, this article focuses on the subset of Stanford's experiences we believe to be of greatest interest to D-Lib readers. Specifically, it covers development and initial implementation of a methodology for automated preservation-risk assessment, results applying the methodology to the AIHT collection, and some general conclusions from our results and from the project as a whole. The ChallengeStanford's vision for an institutional digital repository is broad and inclusive. The Stanford Digital Repository (SDR), a set of services to provide stewardship of information in digital form and Stanford's nascent instantiation of its vision, will eventually be expected to preserve any digital content deemed institutionally significant or valuable. Early SDR process and workflow design was focused primarily on preserving a specialized subset of the potential content, i.e., large, well-defined, highly normative collections of digital objects being created in the Digital Library Program. The SDR team defined prescriptive profiles for instantiation of these objects so that they would reliably conform to SDR preservation policy. In addition, the SDR team established agreements with the content creators allowing the SDR to reject any objects not conforming to the agreed-upon profiles. While being an efficient way to handle internal projects, this is a luxury not possible in many other workflows. In fact, until it becomes common practice to integrate digital stewardship and preservation concerns into the entire digital content lifecycle – especially front-end content creation – most digital preservation workflows intended to be inclusive will be reactive instead of prescriptive. Being reactive – that is, attempting to preserve content after it has been created instead of creating efficiently preservable content in the first place – is inherently unpredictable and inefficient. Yet any viable digital stewardship organization must attempt to minimize unpredictability in its workflows and ensure efficiency, while providing services valuable enough to be in demand. If it must accept content not meeting preservation "requirements", how can a repository maintain sufficient control over its workflow while offering levels of service beyond simple bitstream preservation? Stanford saw this challenge as core to the AIHT, since the GMU 9/11 Archive (the AIHT test-set) is an excellent example of a heterogeneous collection of digital content objects created without consideration of a repository's recommendations or policies. Our StrategyThe practice of assessment, brought to bear in the digital environment, is key to Stanford's strategy for reactive workflows. Prior to the AIHT project, an internal group – the Technical Assessment Group (or TAG team) – performed significant research on methodologies for assessment of arbitrarily created digital objects. The team developed a questionnaire to embody its assessment methodology, one that provided a framework and mechanism for evaluating object classes for digital preservation services. The AIHT team decided to build on this work by attempting automation of the questionnaire's methodology for heterogeneous collections. We hoped this would begin addressing the central challenge effectively. Automation, we presumed, would enable the methodology to scale sufficiently, would provide more realistic and trustworthy data for technical assessment, and therefore would help us maintain more control over workflow. It would at the same time allow us to treat a heterogeneous collection as a more manageable set of object classes, enabling directed investment in preservation actions and the possibility of levels of service beyond bit preservation for select classes. In this article, we discuss the preservation assessment process Stanford conceptualized and then developed for ingestion workflow and how this process relates to digital repository services and policy. We describe the development of a tool that automates the assessment process, and we report the results from assessing the GMU 9/11 Archive using this tool. The treatment of associated preservation metadata for storage and transmission is also discussed. Finally, we report a number of observations and offer some conclusions that can be drawn from Stanford's experience in the AIHT project. The AIHT ProjectPrevious Work – Development of the TAG Team QuestionnaireWilliam G. LeFurgy's concept of optimal, enhanced, and minimal levels of service had inspired the Technical Assessment Group to focus their work on tiered levels of service for digital preservation. Tiered levels promised the flexibility to adapt to the change over time of technologies for managing and preserving digital materials and to the variation of "persistent" qualities existing in the construction, organization, and description of digital materials. LeFurgy anticipated that the factors he described "will play a huge role in determining preservation and access possibilities – even when advanced systems, technologies, and techniques are available to repositories" [1]. The concept of "persistence" [2] helps to characterize the degree to which digital materials can be managed over time independently from the technologies "currently" used to manage them. In the creation of digital materials, factors that affect persistence include the use of consistent and transparent rules for description and structure, and the use of commonly known and supported file formats. The TAG Team developed a framework for categorizing digital materials submitted for preservation. It was intended to help inform and guide the development of preservation services, e.g., metadata encoding, pre-ingestion transformation, long-term format migration and delivery, as well as simple bit preservation. In approaching this task, the following questions immediately arose:
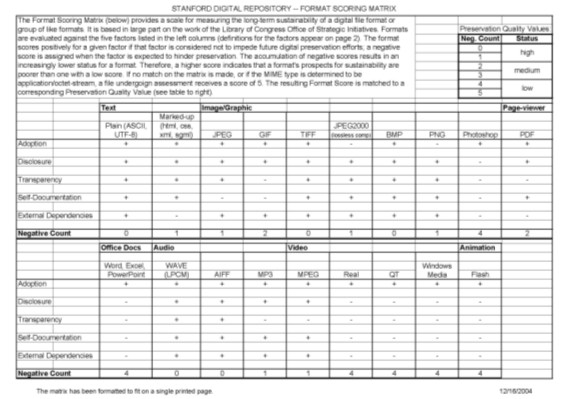
The team saw the need for a mechanism to raise questions and to record answers, a tool to gather vital information about an object (or groups of like objects) and to explicitly express the intent or will of the "content owner" – the person who best knows the information resource, the context of its creation, and its currently perceived value. The tool should also help contextualize the answers within the current limitations of digital preservation and policy. Use of such a tool would help set reasonable expectations – for both content owners and repository managers – about the prognosis for maintaining accessibility over time to the information encoded in the digital objects. The TAG Team addressed the need for such a tool by designing a questionnaire. It is organized into general non-technical and technical factors for all formats, and specific technical factors for three media types: still image, PDF, and text [3]. The team intended it to be used when negotiating a stewardship agreement between SDR staff and potential digital content submitters. It gathers vital information (metadata) about an object class from the "content owner", and attempts to assess "preservability" of the object class by scoring reported technical characteristics against SDR preservation policy. Initial Research-Generalizing Format AssessmentOnce the AIHT began, our team saw clearly that a purely human-mediated interrogative tool would not scale sufficiently for efficient application to a heterogeneous collection, nor was it the most appropriate method for obtaining technical metadata; we needed to automate as much of these processes as possible. The questionnaire's questions split roughly into two groups: those that focused on contextual metadata such as provenance, perceived value, and intended use; and those that focused on technical metadata, i.e., characteristics of the content's digital encoding. The contextual metadata appeared challenging to create automatically; they describe human constructs in the social realm. But the technical metadata seemed easier and more appropriate to create automatically; they describe machine constructs in the computing realm, and clearly would be created more accurately, predictably, and comprehensively by an automated process. We also realized that the mechanism (of assigning values to responses) used to apply policy to technical metadata in the questionnaire lent itself well to automation, providing we could devise a method to encode our preservation policy into machine-actionable form. Ultimately, we decided to attempt development of an automated method for both of these functions: creating technical metadata and assessing it against repository policy. We began this task by researching and adopting work from other organizations. For automating technical analysis and metadata creation, we turned to JHOVE [4], an increasingly well-known and respected utility from Harvard providing format identification, validation, and technical metadata creation on a file-by-file basis. For development of repository format risk policy and the foundations of an automated assessment methodology, we built upon the work of Carl Fleischauer and Carolyn Arms from the Library of Congress Office of Strategic Initiatives [5]. A key intention of the Arms and Fleischauer work was to support the development of practices for handling incoming digital content by determining "preferred" formats. They identified two types of factors, sustainability and quality & functionality as the primary forces making any format "preferred," i.e., more predictable and efficient for a repository to support with services beyond bit-preservation. They devised a table in which the factors making up the anticipated sustainability of a file format – disclosure, adoption, transparency, self-documentation, external dependencies, patents, and technology protection measures – are analyzed and gauged against a handful of related formats. This approach related well to Stanford's previous work, as it generalized and categorized much of the spirit and some of the substance of the TAG Questionnaire. We created a matrix of our own for analysis of predominant formats, and used that as the foundation for our automated risk assessment methodology and for developing repository policies.
The matrix reproduced above represents the state of our thinking towards the end of the AIHT project, and we offer it as illustrative of a methodology rather than a guide to policy. We believe that this approach is flexible not only because it can accommodate frequent changes in scoring as the community's and our format knowledge increases, but also because the separation of scoring from "status" allows us to incorporate score weighting and changes in granularity over time. Stanford chose not to adopt all of the factors identified by the Arms and Fleischauer for our matrix. Specifically, we left out two sustainability factors: "impact of patents" and "technology protection mechanisms." As Arms and Fleischauer acknowledged, patent impact is problematic and needs further exploration; even among some "standard" formats patent impact can already be felt. For the time being, Stanford incorporates a format's patent encumbrance, or similar commercial IP claim, into its assessment of the other sustainability factor, "external dependencies." "Technology Protection Mechanisms" are considered a factor if, and only if, they are employed in a specific file. We decided that this factor is more appropriately analyzed on a file-by-file basis than applied to a format as a class, so we moved its assessment from the Format Scoring Matrix into the supplemental analysis rules (described in "Supplemental Analysis" below). From Quality to PolicyTo support the concept of tiered levels of preservation service, Stanford developed a Policy Status list with five status levels: preferred, approved, acceptable, minimal, and unknown. With the exception of "preferred status", the policy levels correspond to the Format Scoring Matrix as follows:
Table 2 We also settled on the concept of a "preferred" status to focus our commitment to (and our depositors' expectations of) the most thorough preservation services on a small number of formats. We hope this will result in more predictability in our workflow and increased efficiency of our preservation activities. Not all formats with a Format Score of zero automatically earn the "preferred" status; here we apply Fleischauer and Arm's quality & functionality factors to help us choose. Similarly, assigning "preferred" status does not require a Format Score of zero; a format that is both highly suited to a specific purpose in our institutional context and free of risk factors does not always exist. For instance, despite PDF's external dependencies and lack of transparency – factors that give it a "medium", not "high" Preservation Quality score – PDF remains Stanford's preferred page-viewing format because it is currently the de facto standard with extremely wide market and user-community penetration.
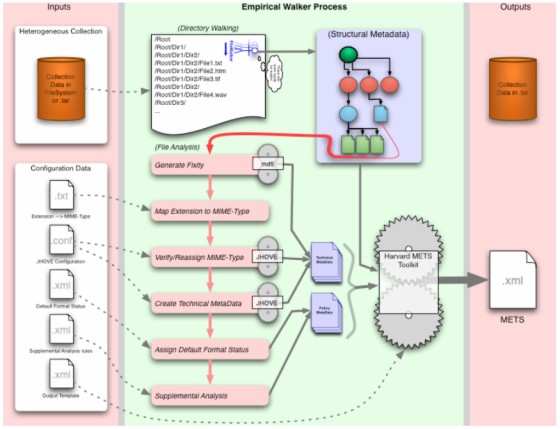
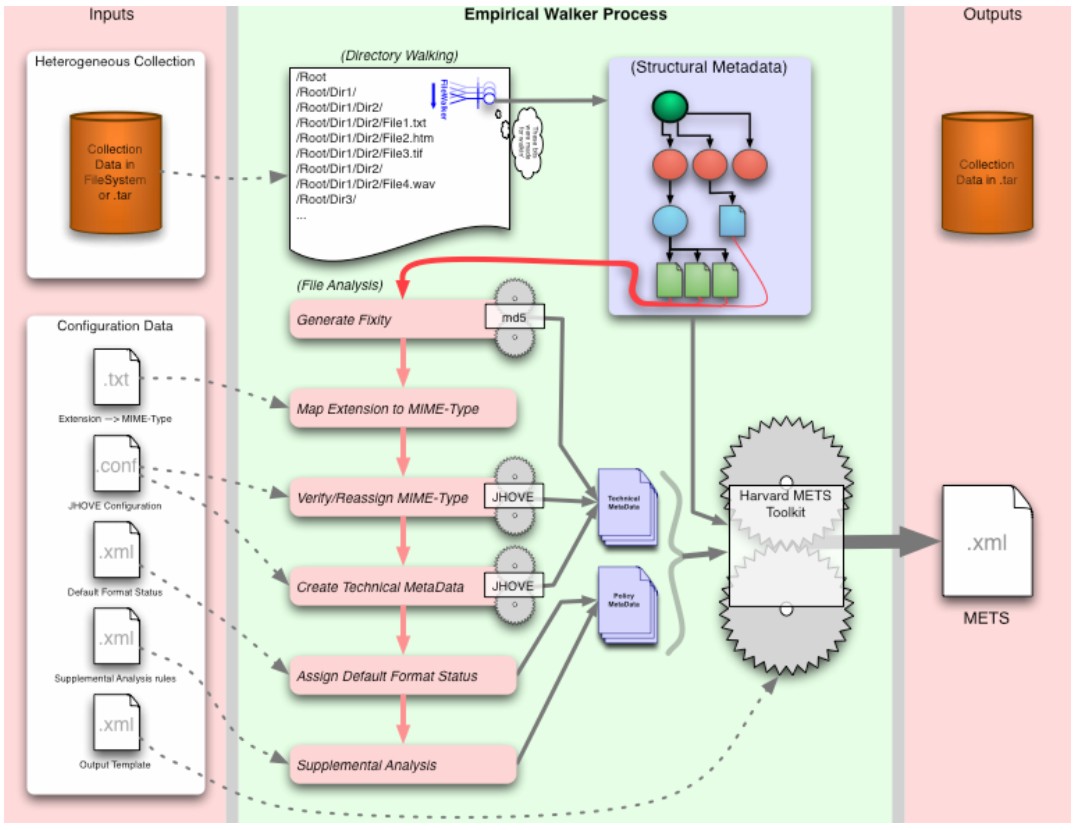
Table 3. Automating the SDR Preservation Assessment Process, v. 0.1 (AKA Birth of the Empirical Walker)With a version of our quality and policy mechanisms in hand, Stanford evolved an automated workflow to survey, describe, and assess the AIHT file collection (the GMU 9/11 Archive). We believe that this workflow is applicable to heterogeneous collections in general. Complete, detailed descriptions of the workflow are available in Stanford's full AIHT report [6]. Here we present its methodology and central building blocks in brief. Inspired by collection assessment methods in traditional preservation practice, we designed a software tool to survey a digital collection automatically. Dubbed the "Empirical Walker," this tool instantiates our automated assessment workflow; it is designed as a pluggable framework to drive external inspection and assessment tools such as JHOVE. The Empirical Walker recursively traverses a file tree, associates external metadata, calculates checksums, determines file format, analyzes file contents, and assigns Preservation Status and supplementary Risk Assessment values. The Empirical Walker's inputs consist of the collection to be surveyed (including extant metadata if desired), xml configuration files encoding Stanford's format assessment and preservation policies, and a template specifying output details. The output is a METS document including (or pointing to) all metadata processed and created during its execution, and a .tar file containing the original content.
A more detailed, formal workflow diagram is available at <http://www.digitalpreservation.gov/reports/aiht>. As the Walker recursively traverses the collection, it discovers relationships between files and creates structural metadata for the whole collection, expressed in a METS <dmdSec> (using MODS relatedItem elements), and also in the METS <structMap>. For each file, it creates empirical metadata as follows:
Using the empirical metadata, the Walker then performs file assessment against SDR policy:
Using the Harvard METS Toolkit, the Walker compiles both collection-level and individual item-level metadata into a METS structure associated with a .tar file containing the collection's content data files. Supplemental analysisThe supplemental analysis phase enables our automated workflow to assess preservation risk against format-specific rules, again encoded in xml. The analysis has two primary goals. The first is to examine the metadata created in the file inspection and validation process to identify:
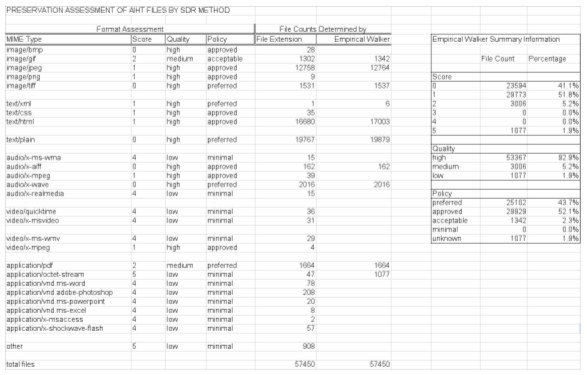
Identified files are "red-flagged" and/or their Policy Status is adjusted as necessary. The second goal of supplemental analysis is to identify files that are suitable candidates, according to SDR policy, for preservation or normalization services. For instance, though files in Adobe Photoshop format currently carry a low format score (4), those meeting certain technical profiles can be reformatted to PNG or TIFF with little or no loss, thereby creating equivalent derivatives with an improved Policy Status. Similarly, a file in MS Word can be reformatted to plain text, creating a highly preservable derivative of its textual content. The AIHT team explored this possibility of proactive reformatting in phase III of the AIHT, in which we developed a supplemental analysis rule specifically to identify html files in the 9/11 Archive suitable for reformatting to xhtml (and therefore, xml). We used a java implementation of HTMLTidy (http://jtidy.sourceforge.net) to perform the reformatting automatically, creating derivatives with a "preferred" policy status from originals with a lesser "acceptable" policy status. Encoding of Preservation Assessment ResultsThe outcomes from the format identification, status assignment, and preservation risk assessment procedures were recorded using an XML schema inspired by the efforts of the PREMIS Core Elements Group [7], whose schema definition work was still in progress at the time of the AIHT. We used a structure based on the event concept to record the results from each stage of file evaluation. The format assessment metadata for each file was pointed to from a <digiProv> section of the METS document. See Appendix D of the final Stanford-AIHT report for example <digiProv> sections [6]. Workflow ResultsRunning the GMU 9/11 Archive through our automated workflow yielded the following results:
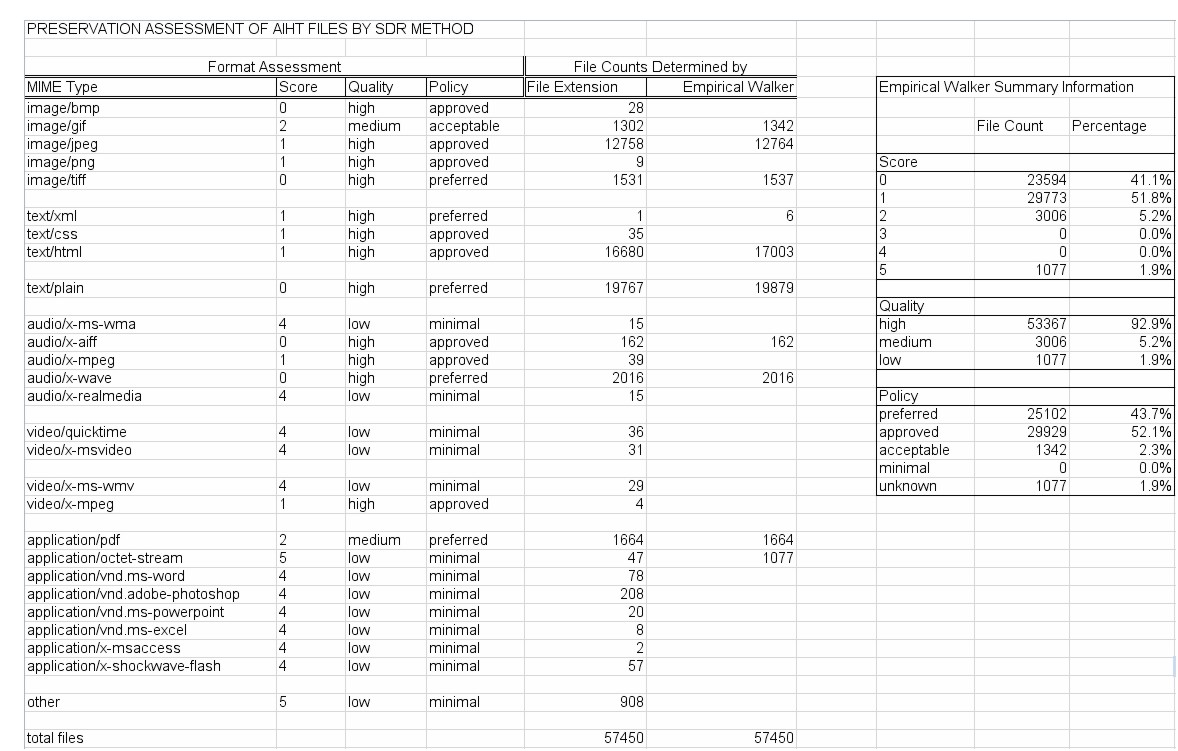
We compared the results output by the Empirical Walker with manually determined assessments. In the manual process, the files were assigned scores and associated policy statuses using only their file extensions as indicators of format. Summaries of the two sets of results are shown above. The differences between them can be explained in two ways. First, the version of JHOVE employed in the AIHT is not capable of interrogating all file formats present in the collection. In cases where a file is opaque, Empirical Walker (via JHOVE) categorizes it as unknown or BYTESTREAM format (with a MIME type of application/octet-stream). So while the manual process results in a fuller, more refined breakdown of file formats present in the collection, without the use of JHOVE or a similar tool the formats remain unchecked for accuracy, the files remain unchecked for validity, and the technical characteristics remain hidden. We expect that detailed analysis of the variances in the results would show that the Empirical Walker, due to JHOVE, determines MIME type more accurately than the manual process, because file extensions can be unreliable or missing. These differences aside, the comparison of the numbers suggests that the automated workflow in the Empirical Walker results in numbers quite close to that of the manual process, an indication that the Empirical Walker is a successful execution of the assessment methodology specification. The Preservation Policy summary results for the original file states were as follows:
Table 5 In our experiment creating higher-status derivatives for html files in phase III, we successfully transformed the vast majority of html files (16,591) to xhtml. Only 121 out of 17,003 html files had errors severe enough to prevent transform. Incorporating these experimental derivatives yields the following potential summary results:
Table 6 Note that the transformations moved 16,591 files from "approved" to "preferred", so that nearly three-quarters of the collection files were now considered to be in "preferred" formats. General ConclusionsAs Stanford entered the AIHT project, we identified a general challenge that we hoped to address. We asked: if accepting content not meeting preservation "requirements" is necessary, how can a repository maintain sufficient control over its workflow while offering levels of service beyond simple bitstream preservation? Looking forward, the question has become narrower and more actionable: Can an automated assessment methodology, prototyped in Stanford's Empirical Walker, help to maintain control over workflow and extend to the development of services beyond bit-preservation in the long-term? While the AIHT project provided Stanford with a only small taste of ingesting and handling "off-the-street" data in a preservation repository environment, we believe that current indications are net positive. The preservation assessment process creates new, additional metadata to manage. The value of that metadata depends on whether the efficiency it brings to the preservation process outweighs the cost of creating and managing it over time. The costs of managing the assessment metadata we generated are currently unknown. The quantity of assessment metadata is relatively small, so the cost of their physical storage is not an immediate concern. However, maintaining the infrastructure to support the methodology is more daunting; it requires a complex layer of management that includes ongoing technology watch, format research, policy maintenance and possibly deposit agreement re-negotiations. Perhaps a federated approach to some of this activity, as a service to a community of repositories and their users, would be most economical. In any case, the costs to be borne are not inconsequential. And yet there are a number of ways in which the assessment data can inform decisions to be made at different points in the preservation cycle, and it is conceivable that, if used effectively, the data's value in the decision-making process offsets or exceeds the cost to create and maintain it. An automated assessment process is clearly the only efficient means to collect technical information about large numbers of files. Once collected and analyzed, the resultant scores can be used as a repository negotiates a stewardship agreement with a depositor. They provide the repository with a means to objectively measure risk associated with digital content and make predictable, viable stewardship commitments beyond bit-preservation. Furthermore, the assessment metadata can be used to perform triage – to prioritize preservation actions in a repository with limited resources. Prioritization can happen at the time of ingest, or later as part of a cyclical auditing process. Perhaps most important, the assessment metadata can be used to inform decisions about when the most efficient time is to act. In the course of continuing discussions amongst the AIHT partners, a new type of preservation action surfaced: the "real option", that is, the explicit decision to wait on making a final decision or commitment. The preservation risk assessment metadata can be used to weigh the risks and costs of acting now, acting later, or delaying decision. Increasingly it is becoming clear that digital repositories – especially inclusive, institutional ones – will need to use a variety of strategies to keep their workflows efficient. Data that helps make decisions valuable, especially early in the preservation cycle, may be one of the most powerful levers a repository has access to. In our experience assessing the GMU 9/11 Archive, we found evidence of value generated in the process of collecting preservation risk data. When we initially informally inspected the collection, we assessed that it had a high preservation risk in aggregate, i.e., our prognosis was pessimistic. However, using the Empirical Walker we discovered that over 97% of the collection's files had at least "acceptable" preservation policy status or better. Even though that still left over one thousand files identified at high risk, and our process was (and remains) capable only of assessing individual files, as opposed to complex objects, the process undoubtedly enables more nuanced preservation decisions for the collection. More generally, the experience showed that practical tests are valuable. We obtained more benefit from this process than we had expected at the start. The freedom and encouragement to experiment with different approaches within the constraint of working with practical, real-world content enabled Stanford to generate results applicable both for its own efforts and, we hope, for the digital preservation community at large. Notes and References[1] William G. LeFurgy. "Levels of Service for Digital Repositories" D-Lib Magazine May 2002, Volume 8, Number 5, <http://www.dlib.org/dlib/may02/lefurgy/05lefurgy.html>. [2] Reagan Moore et al. "Collection-Based Persistent Digital Archives - Part 1," D-Lib Magazine, March 2000, Volume 6, Number 3, <http://www.dlib.org/dlib/march00/moore/03moore-pt1.html>. [3] The full questionnaire is available as part of Appendix B of Stanford's AIHT report - http://www.digitalpreservation.gov/reports/aiht [4] JHOVE, Harvard University Libraries, <http://hul.harvard.edu/jhove/>. [5] Originally presented at the Digital Library Federation Fall Forum 2003. This work has since been developed further and is now available at the NDIIPP site: <http://www.digitalpreservation.gov/formats/index.shtml>. [6] Archive Ingest and Handling Test (AIHT) Appendices, http://www.digitalpreservation.gov/reports/aiht. [7] PREMIS, <http://www.loc.gov/standards/premis>. Copyright © 2005 Richard Anderson, Hannah Frost, Nancy Hoebelheinrich, and Keith Johnson |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/december2005-johnson
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
{kind=link}
{kind=link}
{kind=link}