|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Stephen Abrams, Digital Library Program Manager Stephen Chapman, Preservation Librarian for Digital Initiatives Dale Flecker, Associate Director for Planning and Systems Sue Kreigsman, Digital Projects Librarian Julian Marinus, Digital Library Software Engineer Gary McGath, Digital Library Software Engineer Robin Wendler, Metadata Analyst Harvard University Library |
![]()
IntroductionThe Harvard University Library (HUL) has operated a preservation repository, the Digital Repository Service (DRS), for the past five years, with over 3.2 million digital objects (12 TB) currently under managed storage [1]. By both policy and design, the DRS is intended for highly "curated" digital assets; that is, those that are owned and submitted by known users, created according to well-known workflows and meeting well-known technical specifications, and in a small set of approved formats. In the future, however, we feel that most, if not all, of these restrictions will be gradually eliminated, thus positioning the DRS much more as an institutional repository. In view of this, the Archive and Ingest Handling Test (AIHT), organized by the Library of Congress, and requiring the import, export, and manipulation of a sizeable test corpus of unknown provenance, was an excellent opportunity for us to investigate a number of issues we can expect to face in the future. The most significant of these issues include:
The AIHT project team drew upon the expertise of HUL staff in the following areas:
The AIHT project was successful on two levels. On a large scale, the project validated the supposition that significant bodies of digital material can be transferred easily between preservation institutions making use of radically different technological infrastructures. More parochially, the project uncovered a number of areas of DRS design, practice, and policy that will require some level of enhancement as HUL expands the services and scope of the repository to better serve the needs of the university for reliable long-term access to its manifold digital assets. Phase I: Ingest
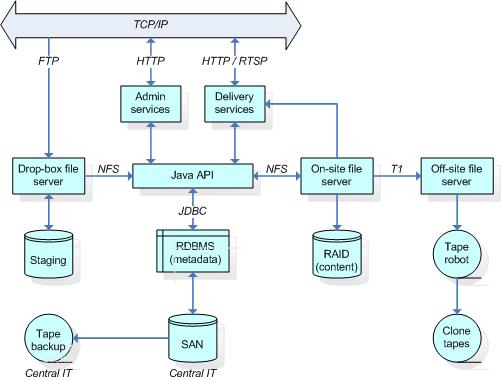
During the ingest phase a number of scaling issues arose almost immediately. The test corpus was delivered as a single 9 GB compressed archive file ( The DRS draws a fundamental distinction between primary content and metadata about that content. Content is stored in a RAID-based file system, with automatic replication to an off-site robotic tape library; administrative, technical, and structural metadata are stored in an Oracle 9i relational database. (In the HUL infrastructure, descriptive metadata is stored in public access catalogs external to the repository. As issues of access were out of scope for the AIHT project, no descriptive metadata was generated or stored.) Access to metadata stored in the repository is mediated through a Java API.
DRS SIPs take the form of an arbitrary number of individual content files along with a single XML-formatted control file containing loader directives and administrative and technical metadata about the content files. Minimum standards for required DRS technical metadata have been established for text, image, and audio content types and are enforced through a variety of mechanisms, including the SIP schema, database table-level constraints, and the repository API. (Image metadata is consistent with the NISO Z39.87 data dictionary [2]; audio metadata is consistent with the evolving AES-X098B schema [3].) Thus, the main technical challenge of Phase I was to generate the necessary control file and populate it with appropriate metadata. This was accomplished using an extension to the standard JHOVE Audit output handler [4]. The default high-level behavior of the Audit handler can be summarized as follows:
audit(directory)
{ for (all files in directory) { if (file is directory) { audit(file); } else { validate and characterize file; output summary file information; } } } A new output handler, known as DSIP (DRS SIP handler), was created by extending the Audit class such that the output format conforms to the schema for the DRS SIP control file [5]. At the time that the project began, JHOVE modules were available for the following formats: ASCII, GIF, JPEG, PDF, TIFF, UTF-8, and XML. As part of the project, new modules were developed for the AIFF, HTML, JPEG 2000, and WAVE formats. (All of these modules were subsequently included in the May 26, 2005, production release of JHOVE.) This module set was sufficient to support over 93% of the files in the AIHT corpus. The distribution of the remaining 7% showed a very long and shallow tail, with more than 90 additional formats suggested by unique file extensions. It should be further noted that the format of the files as determined by JHOVE differed, in some cases significantly, from the MIME types supplied in the original transfer manifest from the Library of Congress and from the formats implied by the file extensions.
The HTML format appears to be particularly problematic: over 78% of the files putatively identified as HTML in the transfer manifest were determined to be malformed by JHOVE. These files were ingested into the DRS as plain text files. Files whose format could not be determined by JHOVE were ingested as opaque objects of type "application/octet-stream". Note the discrepancy in the total number of files: 57,492 documented in the transfer manifest vs. 57,450 found on the file system. In fact, the manifest recorded information about 49 files not found on the file system and the file system contained 7 files not recorded in the manifest. The majority of these discrepancies can be traced to file system incompatibilities between NTFS and UFS with regard to pathname length, case, and character set. As mentioned previously, the DRS is currently implemented to enforce a number of constraints based on the assumption that all depositors will follow DRS technical specifications for object creation. In the context of the AIHT project these constraints had to be relaxed to permit the ingestion of the test data. The more significant of these changes included:
Phase II: Export and Re-importPrior to the AIHT project, the DRS API did not include export functionality: sets of files could be requested by name (or other uniquely identifying properties) but there was no facility for bulk export. A simple Dissemination Information Package (DIP) format was established in the form of a compressed archive file (harvard.tar.gz) consisting of the 57,450 individual content files and a single METS file [6] containing administrative and technical metadata. The administrative metadata included the original pathname of the file, its size, MIME type, and MD5 checksum. Technical metadata for images was formatted in the MIX schema [7]; for audio, the AES-X098B schema was used; and for text, the NYU text METS extension schema (textmd.xsd). For the re-import step of Phase II, the DIPs from the other three participating institutions were evaluated for consistency with the DRS architecture. The Johns Hopkins DIP did not include technical metadata while the Old Dominion DIP was based on MPEG-21 DIDL (Digital Item Description Language) [8], an unfamiliar technology; therefore we decided to import the Stanford DIP. This consisted of a METS file and two parallel directory trees: one for the content files and one for the technical metadata about those files. The technical metadata for each content file was stored in its own separate file. Due to this distributed organization, we were not able to use a simple XSL stylesheet transformation, but rather had to create a Perl script to generate the DRS SIP; the process would have been simpler if the DIP METS file directly contained all of the metadata. Stanford also used JHOVE to generate much of its technical metadata. Unfortunately, however, they were working with an older version of the code, pre-release 1.0 (beta 2) of 2004-07-19. HUL used the then current internal development version, pre-release 1.0 (beta 3) of 2005-02-04, which corrected a number of known errors in the previous version as well as providing several new format modules. This version disparity led to some inconsistencies in the reporting of the technical metadata between the initial ingest and the re-import of the Stanford DIP.
Post-mortem investigation disclosed the following reasons for these discrepancies:
These discrepancies point out the importance of standardizing on processing tools and criteria for format well-formedness and validity. They also highlight an unfortunate feature of the current DRS, which only permits deposit of objects accompanied by minimally required metadata. Objects without this minimal metadata can be ingested only by being downgraded to opaque objects of type "application/octet-stream". Future enhancements to the repository will relax this restriction. Phase III: Format MigrationHUL chose to perform a migration of various image files to the JPEG 2000 format [10]. There is great local interest at Harvard in the retrospective conversion of substantial numbers of existing TIFF images to enhance their utility by permitting the dynamic image manipulation facilitated by the JPEG 2000 format. The three goals that guided the design of the migration were:
The source population of 15,452 GIF, JPEG, and TIFF files was subdivided into 25 classes based on format, color space, compression, bits/sample, and image size. Each class had a corresponding set of unique codec parameters. In keeping with our established goals of preserving integrity and maximizing usability, the codec configuration used the following specifications:
These ensured lossless compression and fast decoding and permitted the dynamic manipulation (pan and zoom) of the resulting images. Since none of the advanced color management features of the JPEG 2000 JPX profile was required – none of the JPEG files included embedded color profiles and none of the TIFF files made use of the WhitePoint or PrimaryChromaticities colorimetry tags – the JP2 profile was used instead. As the codec did not accept GIF as a source format, the 1,339 GIF files were first transformed to equivalent uncompressed RGB TIFFs. The initial attempt at transformation failed for a significant proportion of the source images (5,031 out of 15,452, or 32.5%):
Post-mortem investigation revealed the following limitations and errors in the codec, all of which were quickly addressed by the codec vendor in a subsequent release.
The total file size of the resulting JPEG 2000 files increased 1.4 GB over that of the original source files, a 28% increase. In general, the resulting file sizes for images derived from GIF and JPEG sources increased by a factor of three, while those derived from TIFF sources decreased by a factor of three.
Since approximately 19% of the original images were in the RGB color space, an additional codec option to perform an RGB-to-YUV color space transformation could have been specified. Since this would have the effect of removing correlations between the color channels, we would have expected to see somewhat better compression ratios. Automated and manual quality assurance testing was performed subsequent to the migration. JHOVE was used to verify that all of the resulting JPEG 2000 images met the established specifications. Manual side-by-side viewing of before and after images was performed on a small, through representative, sample under ISO 3664 calibrated viewing conditions [11]. A commercial image processing application was used to perform pixel-by-pixel comparisons of source and target images. For all TIFF-to-JPEG 2000 migrations, which did not require a color space transform, the comparison showed exact numerical equivalence; for all JPEG-to-JPEG 2000 migrations, which did involve a YCbCr-to-sRGB color space transform, the comparison revealed small errors (on the order of σ= 0.02), presumably the result of numerical round-off. In all cases, however, the JPEG 2000 images were considered to be visually lossless by trained observers of the Harvard College Library Digital Imaging Group (HCL-DIG). Thus, at best the transformation process can be considered mathematically lossless and at worst, perceptually lossless. The current DRS data model does not provide a mechanism to capture arbitrary provenance metadata. Based on our Phase III investigation, the HUL team recommended the use of the PREMIS event model for this purpose [12]. Unfortunately, the project schedule did not allow sufficient time for HUL to attempt to implement any changes to the DRS. (In addition to the necessary table model and API changes, this would have required significant alteration of existing work flows.) Provenance metadata for the derived JPEG 2000 images were maintained in the DRS in the form of discursive text inserted into an existing administrative note field. ConclusionsIn general, the test proceeded smoothly along the lines defined in the project proposal. There were no major difficulties that necessitated significant changes to the original HUL project plan. The test provided HUL with important information regarding potential changes to its Digital Repository Service that will increase its ability to accept a wider range of digital resources generated by agents and processes beyond HUL's control or influence. JHOVE proved to be a fundamentally important infrastructure component, used by all project participants for the automated validation of content files, extraction of technical metadata, and generation of repository-compliant SIPs. The format migration process was fully automated once the appropriate codec specifications were developed. Our results suggest that for images, effective post-transformation QA testing can be performed in an automated manner. All AIHT participants successfully completed all required project phases, thus, the project was successful in validating a key assumption of the evolving National Digital Information Infrastructure Preservation Program (NDIIPP) infrastructure [13]: namely, that significant bodies of digital content can be transferred without loss between institutions utilizing radically different preservation architectures and technologies. However, the scaling problems uncovered during the project underscore the importance of identifying and deploying robust tools and protocols in preservation workflows. In general, the limiting factor in large-scale data transfer appears to be the number of objects, rather than their individual or total size. This suggests that appropriate SIPs and DIPs for such transfers should be arbitrarily nestable container objects. The design of such objects would be a fruitful area for collaborative standardization within the digital library and preservation communities. References[1] Harvard University Library, Overview: Digital Repository Service (DRS), August 11, 2004 <http://hul.harvard.edu/ois/systems/drs/>. [2] NISO Z39.87 / AIIM 20-2002, Data Dictionary-Technical Metadata for Digital Still Images, Draft Standard for Trial Use, June 1, 2002-December 31, 2003 <http://www.niso.org/standards/standard_detail.cfm?std_id=731>. [3] AES-X098B, Administrative and structural metadata for audio objects (work in progress by the Audio Engineering Society SC-03-06 Working Group on Digital Library and Archive Systems). [4] Harvard University Library, JHOVE - JSTOR/Harvard Object Validation Environment, May 26, 2005 <http://hul.harvard.edu/jhove/>. [5] Harvard University Library, DRS User Manual for Data Loading, October 4, 2005 <http://hul.harvard.edu/ois/systems/drs/load_manual/wwhelp/wwhimpl/js/html/wwhelp.htm>. [6] Library of Congress, METS: Metadata Encoding and Transmission Standard Official Web Site, January 25, 2005 <http://www.loc.gov/standards/mets/>. [7] Library of Congress, MIX: NISO Metadata for Images in XML Schema Official Web Site, August 30, 2004 <http://www.loc.gov/standards/mix/>. [8] ISO/IEC 21000-2:2005, Information technology - Multimedia framework (MPEG-21) - Part 2: Digital Item Declaration, October 6, 2005. [9] Adobe Systems Incorporated, PDF Reference: Adobe Portable Document Format Version 1.6 (5th ed.; Berkeley: Peachpit Press, 2005) <http://partners.adobe.com/public/developer/en/pdf/PDFReference16.pdf>. [10] ISO/IEC 15444-1, Information technology - JPEG 2000 image coding system: Core coding system, September 23, 2004. [11] ISO 3664:2000, Viewing conditions - Graphic technology and photography, August 15, 2005. [12] OCLC/RLG, Data Dictionary for Preservation Metadata: Final Report of the PREMIS Working Group, May 2005 <http://www.oclc.org/research/projects/pmwg/premis-final.pdf>. [13] Library of Congress, Preserving Our Digital Heritage: Plan for the National Digital Information Infrastructure Preservation Program, October 2002 <http://www.digitalpreservation.gov/repor/ndiipp_plan.pdf>. Copyright © 2005 Stephen Abrams, Stephen Chapman, Dale Flecker, Sue Kreigsman,
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/december2005-abrams
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||