|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Gary Marchionini |
![]()
AbstractIn this article we describe the primary goals of the Open Video Digital Library (OVDL), its evolution and current status. We provide overviews of the OVDL user interface research and user studies we have conducted with it, and we outline our plans for future Open Video related activities. IntroductionDigital video presents important challenges to digital librarians. The challenges are due to file sizes, the temporal nature of the medium, and the lack of bibliographic methods that leverage non-textual features. There are increasing volumes of digital video available from traditional producers (e.g., news and entertainment media, educational and government institutions) and huge amounts created by individuals with access to inexpensive digital cameras and editing tools who collect and exchange video with family and friends. Librarians have traditionally indexed image and video collections with textual bibliographic data that mainly parallels text works, e.g., producer, date, run time. (See Rasmussen, and also Fidel, for discussions of image indexing [Rasmussen, 1997, Fidel, 1997].) Enser and Sandom have assessed video indexing in film archives and reinforce the usage of human-assigned bibliographic data while raising the limitations of automated context-based indexing [Enser & Sandom, 2002]. Nonetheless, there is considerable effort to find ways to automate indexing in video DLs. The increasing volumes of content and increasing number of users with growing expectations have stimulated the digital library community to take up the challenges of acquiring, storing, indexing, retrieving, preserving, and transferring video content. To date, the most prominent and comprehensive effort to build a digital library (DL) of digital video is the Informedia Project [Christel et al., 1997, 1998; Smith & Kanade, 1998; Wactlar et al., 1999; Witbrock & Hauptmann, 1998]. Informedia uses a variety of visual features (e.g., color, faces, text superimpositions) as well as textual features (e.g., speech to text transcripts) to make a large volume of digital video retrievable. The project has demonstrated the efficacy of many technical processes for organizing, searching, and scaling video DLs. While there has been substantial research on particular aspects of digital video retrieval, e.g., segmentation and feature detection (see Chang et al. for an overview [Chang et al., 1997]), Informedia addressed many of the integration challenges in incorporating different research products into a demonstration DL. Other important projects include IBM's CueVideo, which has been integrating a variety of segmentation, indexing, and user interface techniques developed in the Almaden and Watson labs [Ponceleon et al., 1999], and the Digital Video Multimedia Group at Columbia [1], which has been engaged in several streams of work including efforts to automate video summaries [Chang et al., 1997]. The Multimedia Information Retrieval Group at Dublin City University has been developing the Físchlár Project, which provides broadcast video for the university community. This group has developed innovative user interfaces for the video repository [Lee & Smeaton, 2002]. The European Union's ECHO Project [2] is developing archives of historical footage from different European countries and has focused on creating metadata schemes and cross-language access techniques. Each of these large-scale projects draws upon substantial efforts by the engineering communities devoted to finding effective signal-processing techniques for digital video. The Open Video Digital Library [3] aims to capitalize on advances in engineering as well as in library and information science to create usable services for the research and educational communities. In this article we describe the primary goals of the Open Video Digital Library, its evolution and current status. We provide overviews of the user interface research and user studies we have conducted with it and outline our plans for future Open Video related activities. Open Video GoalsThe Open Video Digital Library (OVDL) is motivated by several theoretical and practical goals. Theoretical GoalsThe first theoretical goal is to instantiate and evaluate the Sharium concept for digital libraries [Marchionini, 1999]. The idea is to directly leverage human time, effort, and resources—what libraries mostly have done indirectly (through government and non-government support) by inviting contributions and direct patron participation in digital libraries (DLs). The Internet makes it possible to get people directly involved, which is especially important in DLs where physical space, signage, and reference support are not available. The Sharium concept adds disintermediation to the many existing layers of intermediation, thus adding depth missing in many DLs and impractical to achieve in physical libraries. One example of this is what Jones calls "contributor-run" DLs [Jones, 2001] using the Linux archive as a case study. Open Video will provide an environment for studying ways to involve patrons more actively in DLs; the Open Video Special Collections page, which highlights and facilitates user access to significant contributions, is a first step in this direction [Geisler et al., 2002]. The second theoretical goal is to understand browsing and searching in electronic environments. Unlike physical libraries where the catalog and indexing aides are clearly distinct from the texts, tapes, and other primary media, DLs provide both pointer information and primary materials in the same interface. This is convenient for users but also challenging because the lack of clear demarcations in pointer and primary information can be confusing or overwhelming. In electronic environments, analytical searching, browsing, and reading/viewing are tightly coupled and lead to new information-seeking strategies and behaviors [Marchionini, 1995]. Video provides particularly interesting opportunities to study the tightly coupled, interactive information-seeking process in multiple channels. The third theoretical goal is to instantiate and evaluate a framework for DL interfaces. User interfaces are the analogs to library space and librarian services such as reference in physical libraries. Thus, user interfaces are crucial to the success of all DLs. We have been developing a framework for interactive user interfaces that gives people multiple views of information spaces and allows them to quickly and easily change these views to search, browse, view and reflect on the process. The OVDL provides a test bed for developing and evaluating an interaction framework we call "AgileViews" [Marchionini et al, 2000; Geisler, in press]. AgileViews builds upon dynamic query [Shneiderman, 1994] and other interactive, graphical interfaces [Card et al., 1991]. At present, we are creating and evaluating previews, overviews, reviews (or history views), peripheral views, and shared views. Practical GoalsAn important practical goal of the OVDL is to build an open source digital video test bed for DL research and development. Currently, each video research team must acquire and manage its own video content. Because content characteristics are important to test results (e.g., visual quality can influence feature detection algorithms), an open source test bed will be useful for video retrieval researchers in two ways—first to provide easy access to content and allow users to focus on their research goals, and second, to make it possible to compare results with other approaches using the same content. In our case, the corpus provides us with the content for our user interface studies related to the theoretical goals above. The educational community will benefit from an open source DL available to instructors and students for in-class, at-a-distance, group, and individual uses. The corpus also provides opportunities for educational researchers to study teaching and learning with video content. Another practical goal is to provide a training ground for information and library science students to gain skill in using and operating DLs. Just as students may intern in physical libraries or corporate information centers to gain practical experience, students can intern in the OVDL or incorporate the resources in their coursework and independent studies. For example, Stachowicz used the repository to compare results of manual indexing of video, based on either viewing the full video or viewing surrogates only [Stachowicz, 2002]. Other students have worked to build, assemble, and evaluate user interfaces; develop project tools for managing digital video and extracting keyframes; create metadata, markup, and database schemes; write middleware software; and develop programs for surrogate generation. Finally, the OVDL can serve the practical needs of the public for an open source repository of digital video. Evolution and Current StatusWith these theoretical and practical goals in mind, the project has been evolving since 1996 when we worked with Discovery Channel video to provide multimedia materials to middle school science and social studies teachers in the Baltimore Learning Community Project [Marchionini et al., 1997]. In that work, we indexed short segments of documentaries and integrated them with images, texts, and educational WWW sites in a dynamic query user interface that provided slide show and storyboard previews for the video as well as provided a lesson-plan construction tool. A number of user studies were conducted to assess the effectiveness of different implementations of the video surrogates [Ding et al., 1997; Komlodi & Marchionini, 1998; Tse et al., 1998]. In 1999, the task of creating a publicly accessible digital video repository and test bed began in earnest. A framework for creating a digital video repository was developed [Slaughter et al., 2000], and the usefulness of the repository was discussed at both the SIGIR workshop on video retrieval in Berkeley in August and at a video retrieval symposium hosted in Chapel Hill in October. With support from the UNC-CH Provost and the School of Information and Library Science, the Open Video Project was formally launched in the late fall of 1999. The initial public version of the OVDL consisted of 120 files in MPEG-1 format. These files were segments from 8 different video programs obtained from U.S. government agencies such as the National Archives and NASA, representing about 12 hours of content. By Spring 2000, contributions from Carnegie Mellon's Informedia Project, the Howard Hughes Medical Institute, and the Prelinger Archives helped grow the collection to 225 files and more than 40 hours of content. Additional contributions in 2001 from Informedia, the Internet Archive, and other sources increased the collection to about 1500 files and broadened the range of available file formats to include MPEG-2 and MPEG-4 in addition to MPEG-1. At the time of writing this article (Fall 2002), the OVDL provides 1800 video files (more than .5 terabytes of content), representing 460 hours of video footage. Table 1 describes the basic characteristics of the video in the current collection.
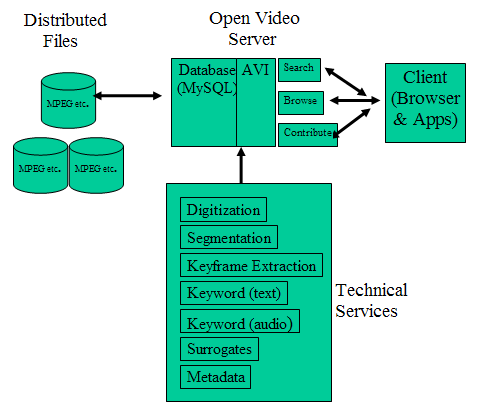
At present, the OVDL includes MPEG-1, MPEG-2, MPEG-4, and QuickTime files. We believe providing digital files rather than streaming video is important to the goals of the project and better serves the research and education communities. Our partnerships with contributors have been substantial and are expanding. The Informedia Project has contributed about 30 hours of its government documentary video, including extensive metadata and transcripts. The University of Maryland's Human-Computer Interaction Laboratory has contributed its files of videos from 20 years of annual symposia. Rick Prelinger contributed several of his ephemeral films early on in the project, and today we point to most of his entire archive, which is available in the Internet Archive [4]. We have a cooperative agreement with NASA for 16 additional programs and are working with professors around the world to add selected videos they can use in their classes. For the past year, the OVDL Web site has averaged at least 2000 unique visitors each month. Visitors come in nearly equal numbers from the .edu, .com, and .net domains, with a substantial percentage of visitors accessing the collection from outside the U.S. System ArchitectureAs shown in Figure 1, the heart of the OVDL is the MySQL database of metadata and an AgileViews interface module currently implemented as PHP middleware between the database and browse, search, and contribution services. The database schema has been revised over time, from the initial schema of one table with a dozen attributes to the current schema that includes about 15 tables and 100 attributes (including all primary and foreign keys) [5]. The current schema being used is Dublin Core compliant, and OVDL is an Open Archives Initiative Data Provider [6].
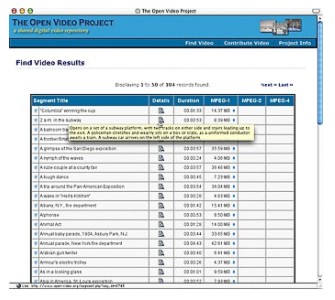
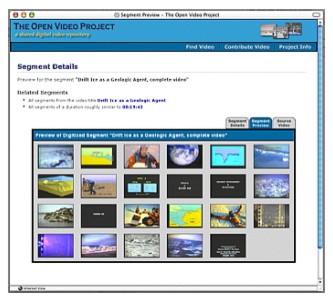
The browse interface presents access clusters by genres (documentaries, educational, lectures, ephemerals, historical), duration (less than a minute, 1-2 minutes, 2-5 minutes, 5-10 minutes, and more than 10 minutes), color (color or black and white), sound (with sound or silent), and contributing organization (e.g., CMU, Internet Archive, etc.). For each category, posting data is given for the number of segments in that category. This layout provides an overview of the entire collection as well as browse access. Browse facilities are available at all levels of the interface. The search interface supports three kinds of search. Attribute search provides pull-down menus or radio buttons for key attributes such as genre or producer. This offers a quick way to partition the database into videos with specific characteristics of interest. Two types of text-based search options are also available. An input field is provided for user-entered queries matched on the full text search of bibliographic records as well as transcripts for those videos with transcripts available. A pull-down menu of keywords that can be used as search criteria is also available. Once the user has partitioned the database through top-level search or browse tools, increasingly detailed overviews for partitions and previews for specific segments become available. Techniques for "looking ahead" before moving to a more detailed level or beginning to download a video file are an important part of the AgileViews interface framework. These "look aheads" are particularly crucial to practical work with video libraries containing many very large files. Figure 2, for example, shows the results page displayed when a user selects the "historical" genre from the browse page. When the user "hovers" (places the mouse) over the details icon for a video, a brief description of that video appears in a pop-up box. Clicking on the details icon yields the full bibliographic record including a tab option for the bibliographic record for the full video to which the segment belongs and a tab to a visual preview for the segment (shown in Figure 3). At any of these points in the interaction, the user can begin to download the complete segment.
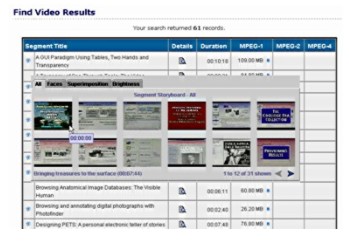
Backend "technical services" operations are depicted in Figure 1. We aim to use as many open source tools developed by others as we can in order to focus on video curation and user interface development and evaluation. Digitization is done in our Interaction Design Lab working from NTSC or BetaSP tapes. Some of the newer content is arriving on digital tapes. At present we manually segment the tapes, either before digitizing or in real time. Although excellent segmentation algorithms exist, manual segmentation gives our students first-hand experience with the content. In some cases, instructors provide segmentation parameters specific to class plans for tapes they want to digitize. Once digitized, segments are saved with systematic names on a disk array. Segmentation and digitization have been done on Wintel systems, but we are shifting some of this to a Macintosh platform. We have used a variety of techniques for keyframe extraction. In most cases, we used the University of Maryland's MERIT software suite to extract keyframes [Kobla et al., 1998]. This software extracts keyframes without decompressing the MPEG-1 files. We have also ported MERIT to both the Linux OS and Mac OS X [7] to increase our flexibility in using it to extract keyframes. In other cases, we use our own scripts and Java programs [8] to extract keyframes from video files using nth-frame algorithms. We have also done a small amount of manual keyframe extraction. After keyframes have been extracted, we manually prune the keyframes and identify representative poster frames using our own Web-based applications. At present, keyword identification and implementation as text or audio is mainly a manual process. For videos that have keywords as part of the metadata record, we use those terms. In other cases, we have been manually assigning keywords with a two-person team, one to identify and one to validate. Once assigned, keywords are automatically added to the pull-down menu in the keyword search facility on the Web site. To produce audio implementations of keywords, a speech synthesizer is used to insure audio consistency (although some terms must be rerecorded or adjusted to improve accuracy). The OVDL video files themselves are distributed on various servers in the Internet2 Distributed Storage Initiative network [9], the SILS Interaction Design Laboratory [10], and other sites such as the Internet Archive and the Library of Congress. Files can either be contributed directly for storage and management in the OVDL or providers can maintain their own files while OVDL simply maintains the metadata and hyperlinks to the files. In addition to the production system available at <http://www.open-video.org>, we have developed several prototype interfaces that incorporate more extensive "agile views", and we are continuing to develop new interfaces based upon our research and user studies. User Interface ResearchThe NSF Interactive Systems Program supported a grant to conduct user interface studies for the 2001-2004 period. Our primary effort is devoted to the creation and evaluation of highly interactive user interfaces that allow people to select representations and control them quickly and easily to achieve their information-seeking needs. The design framework guiding this effort is the concept of AgileViews. We aim to give people several classes of views: overviews of collections of video segments; previews of specific video objects; reviews or history views of past searches or community activities; peripheral views of related objects; and shared views instantiated by others active in the sharium environment [Marchionini, et al., 2000; Geisler, in press]. See Figure 4 and Figure 5 for examples of this research direction.
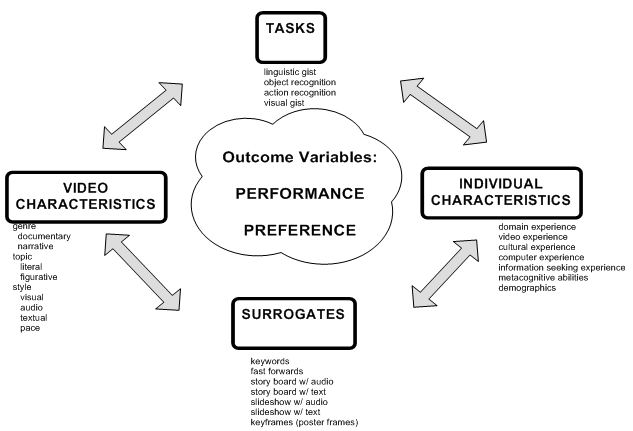
For the OVDL, we have focused on developing surrogates to help people quickly understand video gist (which includes perceptual and media-specific senses of the content) and thus gain quick overviews or previews allowing rapid decision making about whether to obtain more detailed surrogates or the full video segment. We have been working with three types of surrogates and variations within them: slide shows, storyboards, and fast forwards. Slide shows display keyframes at rapid intervals (e.g., 250 ms). They minimize screen real estate and thus avoid window management loads for users. Previous studies demonstrate that people are able to take advantage of slide shows at very high rates (less than 100 ms) but prefer the control provided by other types of surrogates [Ding et al, 1997; Komlodi & Marchionini, 1998]. Storyboards display an array of keyframes. They consume screen real estate and even though they tend to require more user time to perform tasks due to repeated visual scanning, most users have shown a preference for the storyboards. For both slide shows and storyboards, we have experimented with textual and audio keywords added to the keyframes. Fast forwards (implemented by choosing every nth frame) provide some sense of motion and may make it easier for people to detect narrative lines. Our studies suggest that people tend to like fast forwards [Wildemuth et al., 2002; Wildemuth et al., in review]. User StudiesTo address our theoretical research goals, we are guided by a user study agenda that includes performance and preference-dependent measures as well as four classes of independent variables influencing these measures (see Figure 6). One of our central contributions is developing and validating the variables and measures in this research agenda. The independent variables and facets of interest are:
In the next few years, we will continue to expand these user studies to determine tradeoffs for different types of surrogates and establish boundary conditions for human performance. The tradeoffs will ultimately lead to a cost-benefit tradeoff function guiding the kinds of alternative views we provide in the OVDL interface. Studies integrating different overview and preview surrogates are planned for 2003. The 2002 studies aimed to establish some of the boundary conditions that will help us determine default settings for display speeds and keyword supplements. A study currently underway uses eye-tracking to determine how people use displays of search results having visual (poster frame plus several keyframes) and textual cues in the results lists. A study is planned to compare inline and pop up displays of poster frames in results lists. Thus, the study goals are to both inform designs for the OVDL and other digital video interfaces and to develop metrics for assessing video retrieval behavior.
Plans and Future DirectionsThere are several threads of work planned for the coming months. In addition to the ongoing user studies that inform the AgileViews framework and interfaces for DLs, we will be looking for ways to make patron contributions more automatic. At present, contributors must provide some minimal set of metadata, and we manually work with them to insure their contributions are appropriate and properly distributed. Automating the process will require more than simple forms. (Early on we had an upload form with a few required metadata fields but removed this as too simplistic an approach.) We are debating whether to use the Internet Archive and ibiblio collection development policy approach that allows anything to be harvested or contributed and only remove it if there are complaints; or to use a more traditional collection development policy that uses a review board or librarian filter to accept contributions. We are developing a number of specialized tools as we gain more experience with the OVDL. Eventually, these tools should be integrated into a digital librarian toolkit. We endeavor to use open source tools whenever possible, and the programs we develop are licensed under GPL licenses. One tool called the Interactive Shared Educational Environment (ISEE) provides users with facilities to collaboratively and synchronously study video over the Internet [Mu & Marchionini, 2002]. The environment provides a private or shared video window, a text chat window, a shared web browser window, and a multicast video window, as well as tools for managing the communication process. The environment is being tested in three classes at UNC-CH in the Fall 2002 semester. Xiangming Mu has also developed the VAST tool for selecting nth frames of video and converting the resulting "fast forwards" into QuickTime surrogates (see Wildemuth et al. for details and evaluation [Wildemuth et al., in review]). Richard Gruss has developed scripts to crawl digital video websites and extract metadata. Another tool is a peer-to-peer tool for librarians to view and exchange video segments as part of the contribution and collection development processes. This tool has been prototyped by Richard Gruss and will be developed for use by our regular contributors and partners. Meng Yang has begun work on a metadata viewer tool that aims to aid librarians with manual indexing or metadata editing. The ISEE tool is well along and has been demonstrated at meetings such as the Internet 2 conference in the summer of 2002. These and other tools continue to evolve and, over time, we hope to create an integrated toolkit that can be shared with other DLs. Finally, we are concerned with longitudinal evaluation of DLs. Our perspective is to use a multi-faceted evaluation approach [Marchionini, 2001] that integrates different sources of evidence from human (e.g., user studies, transaction log analysis), technical (e.g., performance, costs and design tradeoffs) and informational (e.g., indexing and metadata acceptance) facets. ConclusionThe OVDL is an ongoing project. We are learning by doing and aim in this article to share some of the practical experiences of building and maintaining a digital video library. We are driven by theoretical and practical goals and strive to leverage the synergy of working toward both ends. Our user interaction research goals have been well served by the efforts to build the production system, thus confirming the possibility of useful interactions between theory and practice. Finally, we hope others will use the library and contribute to it, and we hope the library will serve as a useful public resource and test bed for a variety of research questions. AcknowledgementsThis work received partial support from NSF Grant IIS 0099638. Thanks also are due to the other members of the The Open Video Project team: Richard Gruss, Anthony Hughes, Xiangming Mu, Curtis Webster, Barbara Wildemuth, Todd Wilkens, and Meng Yang. Notes[1] See the Digital Video Multimedia Group at Columbia University at <http://www.ctr.columbia.edu/dvmm>. [2] The home page for the European Union's ECHO Project is at <http://pc-erato2.iei.pi.cnr.it/echo> [3] The Open Video Digital Library (OVDL) is at <http://www.open-video.org>. [4] The Internet Archive home page is at <http://www.archive.org>. [5] Susan Dennis and Christina Pattuelli developed the first Dublin Core compliant database scheme in the Spring 2000 semester, and Adam Smith extended the scheme to its current form in the fall of 2000. [6] Michael Nelson and Gary Geisler are responsible for making OVDL an OAI data provider. [7] Richard Gruss did these ports. [8] Xiangming Mu and Richard Gruss developed these programs. [9] See the Internet2 Distributed Storage Initiative network at <http://dsi.internet2.edu>. [10] See the SILS Interaction Design Laboratory at <http://www.ils.unc.edu/idl>. References[Card] Card, S. Robertson, G., & Mackinlay, J. (1991). The information visualize; an information workspace. Proceedings of SIGCHI Conference on Human Factors in Computing Systems, (New Orleans, April 27-May 2, 1991). 181-188. [Chang et al, 1997] Chang, S., Smith, J., Meng, H., Wang, H., & Zhong, D. (1997). Finding images/video in large archives. D-Lib Magazine 1997 (February): <http://www.dlib.org/dlib/february97/columbia/02chang.html>. [Christel, et al., 1998] Christel, M., Smith, M., Taylor, C.R., & Winkler, D. (1998). Evolving video skims into useful multimedia abstractions. Proceedings of CHI '98: Human Factors in Computing Systems (Los Angeles, April 18-23, 1998). 171-178. [Christel et al., 1997] Christel, M., Winkler, D. & Taylor, C.R. (1997). Improving Access to a Digital Video Library. Paper presented at the Human-Computer Interaction: INTERACT97, the 6th IFIP Conference on Human-Computer Interaction, Sydney, Australia, July 14-18, 1997. [Ding et al., 1997] Ding, W., Marchionini, G., & Tse, T. (1997). Previewing video data: Browsing key frames at high rates using a video slide show interface. Proceedings of the International Symposium on Research, Development, and Practice in Digital Libraries, (Tsukuba, Japan) p. 151-158. [Ding et al., 1999] Ding, W., Marchionini, G., & Soergel, D. (1999). Multimodal surrogates for video browsing. Proceedings of Digital Libraries '99. the fourth annual ACM conference on digital libraries (Berkeley, CA, August 11-14, 1999). 85-93. [Enser & Sandom] Enser, P. & Sandom, C. (2002). Retrieval of archival moving imagery: CBIR outside the frame? Proceedings of the International Conference on Image and Video Retrieval (London, July 18-19, 2002). Berlin: Springer (Lecture Notes in Computer Science 2383). 206-214. [Fidel] Fidel, R. (1997). The image retrieval task: Implications for design and evaluation of image databases. New Review of Hypermedia and Multimedia, Vol. 3. 181-199. [Geisler] Geisler, G. (in press). AgileViews: A Framework for Creating More Effective Information Seeking Interfaces. Unpublished doctoral dissertation, University of North Carolina at Chapel Hill. [Geisler et al., 2002] Geisler, G., Giersch, S., McArthur, D., & McClelland, M. (2002). Creating Virtual Collections in Digital Libraries: Benefits and Implementation Issues. Proceedings of the Joint Conference on Digital Libraries (JCDL 2002). pp. 210-218. [Jain & Vailaya] Jain, A. & Vailaya, A. (1996). Image retrieval using color and shape. Pattern Recognition, 29(8), 1233-1244. [Jones] Jones, P. (2001). Open(source)ing the doors for contributor-run digital libraries. CACM, 44(5), 45-6. [Kobla et al.] Kobla, V., Doermann, D. and Faloutsos, C. Developing High-Level Representations of Video Clips using VideoTrails. Proceedings of the SPIE Conference on Storage and Retrieval for Image and Video Databases VI, pages 81-92, 1998 . [Lee & Smeaton] Lee, H. & Smeaton, A. (2002). Designing the User-Interface for the Físchlár Digital Video Library. Journal of Digital Information, 2(4), Special Issue on Interactivity in Digital Libraries, May 2002. [Komlodi & Marchionini] Komlodi, A. & Marchionini, G. (1998). Key frame preview techniques for video browsing. Proceedings of ACM DL '98. (Pittsburgh, PA, June 24-26, 1998). [Marchionini, 1995] Marchionini, G. (1995). Information seeking in electronic environments. NY: Cambridge U. Press. [Marchionini, 1999] Marchionini, G. (1999). Augmenting library services: Toward the sharium. Proceedings of International Symposium on Digital Libraries 1999 (Tsukuba, Japan, September 28-29, 1999). 40-47. [Marchionini, 2001] Marchionini, G. (2001). Evaluating Digital Libraries: A Longitudinal and Multifaceted View. Library Trends. 49(2). 304-333. [Marchionini et al., 2000] Marchionini, G., Geisler, G., & Brunk, B. (2000). Agileviews: A Human-Centered Framework for Interfaces to Information Spaces. Proceedings of the Annual Meeting of the American Society for Information Science (Chicago, Nov. 12-16, 2000). p. 271-280. [Marchionini et al., 1998] Marchionini, G., Plaisant, C., & Komlodi, A. (1998). Interfaces and tools for the Library of Congress National Digital Library Program. Information Processing & Management, 34(5). 535-555. [Marchionini et al., 1997] Marchionini, G., Nolet, V., Williams, H., Ding, W., Beale, J., Rose, A., Gordon, A., Enomoto, E., Harbinson, L., (1997). Content + Connectivity => Community: Digital Resources for a Learning Community. Proceeding of ACM Digital Libraries 97 (Philadelphia, PA: July 23-26, 1997). 212-220. [Mu & Marchionini] Mu, X. & Marchionini, G. (2002). Interactive Shared Educational Environment (ISEE): Design, Architecture, and User Interface, April 2002. SILS Technical Report: TR-2002-09 < http://ils.unc.edu/idl/isee/ISEE_tech_report.pdf>, UNC-Chapel Hill. [Ponceleon] Ponceleon, D., Amir, A., Srinivasan, S., Syeda-Mahmood, T., & Petkovic, D. (1999). CueVideo: Automated multimedia indexing and retrieval. ACM Multimedia '99 (Orlando, FL, Oct. 1999). p. 199. [Rasmussen] Rasmussen, E. (1997). Indexing images. Annual Review of Information Science and Technology, Vol. 32. Medford, NJ: Information Today. 169-196. [Shneiderman] Shneiderman, B. (1994). Dynamic queries for visual information seeking, IEEE Software, 11(6). 70-77. [Slaughter] Slaughter, L., Marchionini, G. and Geisler, G. (2000). Open Video: A Framework for a Test Collection. Journal of Network and Computer Applications, Special Issue On Network-Based Storage Services. pp. 219-245. [Smith] Smith, M. & Kanade, T. (1998). Video skimming and characterization through the combination of image and language understanding. Proceedings of 1998 IEEE International Workshop on Content-based Access of Image and Video Database. (Bombay, India, January 3, 1998). Los Alimitos, CA: IEEE. 61-70. [Stachowicz] Stachowicz, Christine. The Effectiveness of Storyboard Surrogates in the Subject Indexing of Digital Video <http://www.open-video.org/admin/christinestachowicz.pdf>. A Master's paper for the M.S. in L.S. degree. April, 2002. [Tse et al.] Tse, T., Marchionini, G., Ding, W., Slaughter, L. & Komlodi, A. (1998). Dynamic key frame presentation techniques for augmenting video browsing. Proceedings of AVI '98: Advanced Visual Interfaces (L' Aquila, Italy, May 25-27). 185-194. [Waclar et al.] Wactlar, H., Christel, M., Gong, Y., & Hauptmann, A. (1999). Lessons learned from building a terabyte digital video library. Computer, 32(2). 66-73. [Wildemuth et al., 2002] Wildemuth, B. Marchionini, G., Wilkens, T., Yang, M., Geisler, G., Fowler, B., Hughes, A., & Mu, X. (2002). Alternative Surrogates for Video Objects in a Digital Library: Users' Perspectives on Their Relative Usability. Proceedings of the 6th European Conference ECDL 2002 on Research and Advanced Technology for Digital Libraries, Berlin: Springer. (Rome, September 16-18, 2002) 493-507. [Wildemuth et al., (in review)] Wildemuth, B. Marchionini, G., Wilkens, T., Yang, M., Geisler, G., Hughes, A., & Gruss, R. (in review). How fast is too fast? Evaluating fast forward surrogates for digital video. [Witbrock & Hauptmann] Witbrock, M. & Hauptmann, A. (1998). Artificial intelligence techniques in a digital video library. Journal of the American Society for Information Science, 49(7). 619-632. (Corrected link to the second reference in the References section 8/31/05.) Copyright © Gary Marchionini and Gary Geisler |
|||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/december2002-marchionini
|
|||||||||||||||||||||||||||||||||||||||||||||||||