|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Norman Paskin |
![]()
1. IntroductionTwo significant activities within ISO, the International Organisation for Standardization [1], are underway, each of which has potential implications for the management of content by digital libraries and their users. Moreover these two activities are complementary and have the potential to provide tools for significantly improved identifier interoperability. This article presents a report on these: the first activity investigates the practical implications of interoperability across the family of ISO TC46/SC9 identifiers (better known as the ISBN and related identifiers); the second activity is the implementation of an ontology-based data dictionary that could provide a mechanism for this, the ISO/IEC 21000-6 standard. ISO/TC 46 is the ISO Technical Committee responsible for standards of "Information and documentation". Subcommittee 9 (SC9) of that body is responsible for "Presentation, identification and description of documents": the standards that it manages [2] are identifiers familiar to the content and digital library communities, including the International Standard Book Number (ISBN); International Standard Serial Number (ISSN); International Standard Recording Code (ISRC); International Standard Music Number (ISMN); International Standard Audio-visual Number (ISAN) and the related Version identifier for Audio-visual Works (V-ISAN); and the International Standard Musical Work Code (ISWC). Most recently ISO has introduced the International Standard Text Code (ISTC), and is about to consider standardisation of the DOI system. The ISO identifier schemes provide numbering schemes as labels of entities of "content": many of the identifiers have as referents abstract content entities ("works" rather than a specific physical or digital form: e.g., ISAN, ISWC, ISTC) [3]. The existing schemes are numbering management schemes, not tied to any specific implementation (hence for internet "actionability", these identifiers may be incorporated into URN, URI, or DOI formats, etc.). Recently SC9 has requested that new and revised identifier schemes specify mandatory structured metadata to specify the item identified; that metadata is now becoming key to interoperability. There has been continuing discussion over a number of years within ISO TC46 SC9 of the need for interoperability between the various standard identifiers for which this committee is responsible. However, the nature of what that interoperability might mean – and how it might be achieved – has not been well explored. Considerable amounts of work have been done on standardising the identification schemes within each media sector, by creating standard identifiers that can be used within that sector. Equally, much work has been done on creating standard or reference metadata sets that can be used to associate key metadata descriptors with content. Much less work has been done on the impact of cross-sector working. Relatively little is understood about the effect of using one industry's identifiers in another industry, or on attempting to import metadata from one identification scheme into a system based on another. In the long term it is clear that interoperability of all these media identifiers and metadata schemes will be required. What is not clear is what initial steps are likely to deliver this soonest. Under the auspices of ISO TC46, an ad hoc group of representatives of TC46 SC9 Registration Authorities and invited experts met in London in late 2005, in a facilitated workshop funded by the registration agencies (RAs) responsible for ISAN, ISWC, ISRC, ISAN and DOI, to develop definitions and use cases, with the intention of providing a framework within which a more structured exploration of the issues might be undertaken. A report of the workshop prepared by Mark Bide of Rightscom Ltd. was used as the input for a wider discussion at the ISO TC46 meeting held in Thailand in February 2006, at which ISO TC46/SC9 agreed that Registration Authorities for ISRC, ISWC, ISAN, ISBN, ISSN and ISMN and the proposed RAs for ISTC and DOI should continue working on common issues relating to interoperability of identifier systems developed within TC46/SC9; some of the use cases have been selected for further in-depth investigation, in parallel with discussions on potential solutions. Section 2 below is based extensively on the report [4] of the output from that workshop, with minor editorial changes to reflect points raised in the subsequent discussion. The second activity, not yet widely appreciated as being related, is the development of a content-focussed data dictionary within MPEG. ISO/IEC JTC 1/SC29, The Moving Picture Experts Group (MPEG) [5], is formally a joint working group of ISO and the International Electrotechnical Commission. Originally best known for compression standards for audio, MPEG now includes the MPEG-21 "Multimedia Framework", which includes several components of digital rights management technology standardisation. Some of the components are already being used in digital library activities [6]. One component is a Rights Data Dictionary that was established as a component to support activities such as the MPEG Rights Expression Language. In April 2005, the ISO/IEC Technical Management Board appointed a Registration Authority for the MPEG 21 Rights Data Dictionary (ISO/IEC Information technology - Multimedia framework (MPEG-21) - Part 6: Rights Data Dictionary, ISO/IEC 21000-6), and an implementation of the dictionary is about to be launched. However, the Dictionary design is based on a generic interoperability framework, and it will offer extensive additional possibilities. The design of the dictionary goes back to one of the major studies of the conceptual model of interoperability, <indecs>. Section 3 below provides a brief summary of the origins and possible applications of the ISO/IEC 21000-6 Dictionary. 2. ISO TC46/SC9 identifier standards: Use Cases for interoperability12.1 DefinitionsAny discussion of this kind is made much more difficult in the absence of a clear definition of scope. The initial task of the activity was therefore to agree a definition of "interoperability". The following generic definition of interoperability was accepted: Interoperability is the ability of independent systems to exchange meaningful information and initiate actions from each other, in order to operate together to mutual benefit. In particular, it envisages the ability for loosely-coupled independent systems to be able to collaborate and communicate. Exploration of what this might mean in the specific context of identifier interoperability suggested three possible different areas for exploration:
Each of these is discussed in more detail below. The importance of the discussion of "metadata" also identified a requirement to define this term. It was agreed that a modification of the <indecs> [7] definition should be adopted:
In the context of identifiers, a further term of art is required for the metadata that is mandated within an identifier standard. This is sometimes referred to as a "minimum metadata set", but such a description can be misleading (since it simply raises a further question – minimum for what purpose?). We therefore agreed to use the term "reference descriptive metadata" for that set of metadata that has been defined within each standard. 2.1.1 Metadata interoperabilityVarious descriptions of metadata interoperability were put forward, including: "...metadata associated with an identified entity can be painlessly referenced in the context of one class of entity even though it was originated in the context of another class of entity." In the absence of a universal implementation of a common metadata scheme for all identifier schemes, these imply that mechanisms need to be defined through which it is possible:
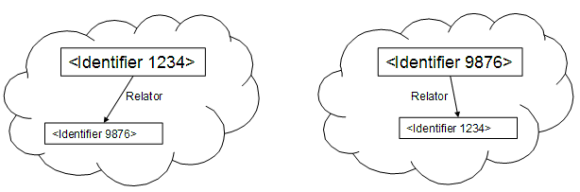
So far as this is possible, it has to be achieved without the loss of semantic value (meaning). 2.1.2 Expression of relationships between referentsDescriptions proposed included: "...the ability to set as one of the properties of an identified object a reference that links it with another identified object." This fulfils illustrative requirements such as: "The book identified with this ISBN is a manifestation of the work identified with this ISTC." This implies the development of a standard set of typed relationships between identifiers with well-defined semantics. 2.1.3 Common ServicesDescriptions proposed included: "...the use of a shared syntax or physical interface for the expression of requests and responses for provision of services and/or data." The types of service that might be considered include:
These can be seen as a development of metadata interoperability – having created the potential for interoperability between metadata sets, how can user value be created? 2.2 Some further notes on scopeMachine-to-machine or human-to-machine: should the "systems" that need to be interoperable always involve machine to machine interoperability? As we developed use cases, it became apparent that human users would normally be a core element of the systems and that consideration should not exclude interoperability mediated by people. Beyond the TG46 SC9 identifier family: discussions within the group deliberately ranged beyond the existing family of TC46 SC9 standards. Discussions included identifiers that have already been discussed as potential TC46 SC9 identifiers, including the Digital Object Identifier and the idea of an international standard "interested party" identifier. However, discussion also covered trade identifier standards such as EAN/UPC; SMPTE's UMID identifier standard; the music industry's GRid (Global Release Identifier) and MWLI (Musical Works Licence Identifier); and the potential role of metadata standards including ONIX, LOM and SCORM. TC46 SC9 and commercial considerations: it is inevitable that discussions should at some point focus on the commercial reality that implementation of interoperability measures will only be possible if they meet some kind of (probably commercial) need to justify the necessary investment. It was agreed that the role of TC46 SC9 is limited to the creation of the standards and governance infrastructure within which it would be possible for others – Registration Authorities, Registration Agencies, third parties – to create implementations should they elect to do so in response to a specific requirement. The role of TC46 SC9 is to facilitate the task of others in creating interoperability between identifier standards, not to effect interoperability services itself. 2.3 Use CasesEleven use cases were developed during the course of the workshop. The intention was to be illustrative rather than exhaustive. It is worth noting that, in discussion, each of the use cases could be seen to be a specialised instance of a more generic requirement that spanned all media types represented at the workshop (even where the specific use cases do not).
USE CASE 1:
USE CASE 2: Although some TC46 SC9 identifiers (particularly ISBN, ISMN) can be correctly characterised as "product" identifiers, some (such as ISAN) emphatically are not. Considerable difficulties arise when an identifier specified for one purpose is used erroneously for a different purpose.
USE CASE 3:
USE CASE 4:
USE CASE 5:
USE CASE 6:
USE CASE 7:
USE CASE 8:
USE CASE 9: This example relates to the collective management of reprographic rights in literary works; similar use cases could be written relating to creator's rights in musical works; performers and producers rights in recordings; and others. The issues would be slightly different in each case.
USE CASE 10: Appendix E of the Committee Draft of the ISTC provides extensive illustrative examples of the potential relationships between ISTC and other TC46 SC9 identifiers (particularly but not exclusively between ISTC, ISBN and ISSN). This not only provides one potential starting point for the semantics required for typing identifier to identifier relationships (see Section 2.5), it also provides the basis for a considerable number of possible use cases, of which this is just one.
USE CASE 11: There are many potential examples of the requirement to link a list of repertoire covered by a specific set of usage terms with that set of usage terms. This particular example may be slightly unfamiliar, but is included for precisely that reason.
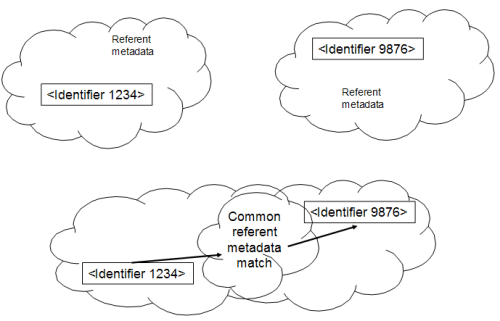
2.4 Gaps in the identifier portfolioDuring the course of development of the use cases, a number of gaps were identified in the TC46 SC9 portfolio. None of this is necessarily new, but the significance of the gaps is probably increasing. 2.4.1 International Standard Interested Party IdentifierAn International Standard Interested Party Identifier is being discussed as a possible work item for ISO TC46/SC9. The role of party identifiers in disambiguation of personal and corporate names has been extensively discussed elsewhere (e.g., the <indecs> Directory of Parties report [8] and the deliverables of the InterParty project [9]). The classic use case is "show me all recordings made by 'John Williams'" – but which 'John Williams'? The requirement for unambiguous party identification is obvious from a number of the use cases discussed here (as indeed is the requirement in some instances to express party to party relationships). Some communities, notably the music rights organisations, have developed party identifiers for internal purposes, on which ISPI might be modelled. However, it should not be pre-supposed that there is a complete consensus within the rights holder community, for example, for the widespread implementation of a standard interested party ID. Indeed, in some communities of interest we believe that there would be significant opposition. There may be a number of reasons for this, ranging from concerns about privacy and data protection to a commercial interest in maintaining ambiguity of identity (and depending on more uncertain methods like name string matching – see also Section 2.5). A distributed mechanism for management of the data associated with ISPI, allowing local control of local data rather than a central repository, may be essential for practical implementation. It is also possible to envisage the deployment of party identifiers in specific domains, perhaps associated with specific roles (for example, the same individual might have a different identifier as a performer from the one they have as a composer or as an author). This scenario – extensively explored in the InterParty project – substantially reduces the utility of the party identifier across different domains in the absence of some interoperability mechanisms to map the identifiers to one another – which, if it exists, creates precisely the same set of objections as a system based on a single identifier. This is no reason to reject the concept of a TC46 SC9 International Standard Interested Party Identifier, but it suggests that its introduction and deployment might not be entirely straightforward, however high its apparent utility to many different users. 2.4.2 Image identificationThe most significant gap in resource identification appears to lie in the domain of graphic images. It has been suggested that existing standards such as ISAN might be applied to digital photographic works; however, that would still leave a substantial number of classes of graphics without a standard identification mechanism. 2.4.3 Usage Term Set [or Licence] identifierThe requirement for the unambiguous identification of licences (or of usage terms sets where these are not based on licences) has been explicitly recognised in the music industry through the introduction of the Musical Works Licence Identifier (MWLI). However it is clear that the requirement goes beyond the specific requirements of licensing musical works. Related work is being carried out by EDItEUR for the ONIX standards (see section 3.5 below). 2.5 Creating and maintaining links2.5.1 Establishing identifier linksCreating a link between two referents is likely to require a human decision, based on the available data. Wherever at least one abstraction is involved (say, linking an ISBN to an ISTC, or an ISRC to an ISWC), a human decision will be required at some stage; machines can not directly recognise abstractions. However, the automated establishment of links between digital fixations is achievable, and other links can be derived automatically from this. For example: if Links are typically made by metadata matching, although the extent to which this can be automated clearly depends on the quality, consistency and comprehensiveness of the available metadata. The issue has several other facets:
2.5.2 Persistent or transient (repetitive) linkingA link between two referents is primarily created by matching metadata about the referents:
This match may have to be made repeatedly if no mechanism is available to manage a persistent link. Alternatively, the link may be stored in either of the two metadata sets, or in both:
This clearly has significant efficiency advantages in comparison with making the same link repeatedly, and allows the autonomy of the two separate metadata sets. The final alternative is to create a definitive link entity (which might be stored in both metadata sets, or might form a separate metadata set). By creating a typed link entity of this kind, the link itself can be given attributes (such as the name of the creator of the link – see Section 2.5.3) 2.5.3 Who makes the claim of the veracity of the linkWe should return briefly here to the definition of metadata: An item of metadata is a relationship which somebody claims to exist between two referents. Here, we have perhaps the perfect example to illustrate the importance of unambiguously identifying the "somebody" who makes the claim. Anyone can make a claim, but the authority of the claim for those who must depend on it is paramount. This is at least in part a specialised use case for the adoption of unique party identifiers (although it may also imply mechanisms for authenticating those identities). The veracity of claims of linkage is particularly important in the management of rights, where significant amounts of money may be distributed. 2.5.4 Access to link dataMany organisations currently create and manage link data of the kind we are considering here within their own systems, and either maintain those links in confidence or share them with a limited range of business partners. Many of the use cases imply a much wider availability of this type of data, and the implications need to be considered carefully. Combining the facets of veracity and access suggests a requirement for a certification or authentication mechanism for identifier links themselves. 2.6 Possible actions on the part of TC46 SC9Several possible activities might be undertaken by TC46 SC9 in the light of the results of the meeting described in this document. These are all subject to verification with users to ensure that requirements are properly identified. The activities might include:
None of this will solve the endemic problems of managing identifiers, including poor metadata quality and the inappropriate application of identifiers. As well as working on the technical standards themselves, some thought probably needs to be given to best practice issues (including, for example, business rules about the circumstances in which it may be appropriate to make an authoritative claim of a link between two referents). Considerable work will remain to be done, even if elements of an interoperability framework are created, to ensure that consensus is built around its application so that it is widely adopted. 3. ISO/IEC 21000-6: a semantic interoperability data dictionary for contentThe Moving Picture Experts Group (MPEG), a working group of ISO/IEC, includes the MPEG-21 "Multimedia Framework" that includes several components of digital rights management technology standardisation. In April 2005, the ISO/IEC Technical Management Board appointed a Registration Authority for the MPEG 21 Rights Data Dictionary (ISO/IEC Information technology - Multimedia framework (MPEG-21) - Part 6: Rights Data Dictionary, ISO/IEC 21000-6). The International DOI Foundation (IDF) was appointed as Registration Authority, with Rightscom Ltd as technical subcontractor, and has been working with ISO and others to establish operational details of this function, resulting in the imminent launch of the operational dictionary [12]. The Rights Data Dictionary was established as a component to support activities such as the MPEG Rights Expression Language. However, the Dictionary design is based on a generic interoperability framework and it will offer extensive additional possibilities. The design of the dictionary goes back to one of the major studies of the conceptual model of interoperability: <indecs>. 3.1 Semantic interoperabilityAn ontology-based Data Dictionary for content entities exists to solve an obvious but difficult problem: how does one computer system know what the terms from another computer system mean? If A says "owner" and B says "owner", are they referring to the same thing? If A says "released" and B says "disseminated", do they mean different things? A data dictionary provides a way of describing relationships between terms, and confirming agreement about this, so that A or B (or anyone else) can make use of one another's metadata with confidence and in a highly automated way. It may be assumed that A knows what he means, and B knows what she means; but they may be assuming totally different concepts from each other. This is true of any term: concepts (e.g., "depression" as understand by the mental health, economics, and meteorological communities), roles (e.g., "publisher" as understood by music, newspaper and book industries), and physical formats (e.g., "folio" as understood by the bookkeeping, legal, historical, and printing communities). The only way of unambiguously deciding if one term means the same as another, irrespective of what it is called, is by sharing a single frame of reference: a structured ontology (an explicit formal specification of how to represent the entities that are assumed to exist in some area of interest and the relationships that hold among them) with an underlying model that allows the generation of consistent new relationships, and a method of recording the agreement between the parties whose terms are included in it. Mapping terms from one scheme to another is not always straightforward. Terms may be expressed in different parts of speech and tenses, and meanings are often "contextual" (e.g., the same term "Identifier" in one place may mean "Product Identifier" and in another "Party Identifier", within the same scheme). A Data Dictionary must support these levels of complexity and contextuality. Whilst there are many ontology approaches, few address the semantic interoperability requirement.3.2 The origins: <indecs>The <indecs> project [13] developed an analysis of the requirements for metadata for e-commerce in Intellectual Property (IP) in the network environment. This analysis has received widespread support. At its heart, <indecs> proposed a very simple generic model of commerce (the "model of making"): people make stuff; people use stuff; and (for commerce to take place) people make deals about the stuff. If secure machine-to-machine management of commerce is to be possible, the stuff, the people and the deals must all be securely identified and described in standardised ways that machines can interpret and use – metadata. This metadata is crucial to all e-commerce, but is particularly relevant to commerce in IP where the goods being traded are intangible rights rather than tangible goods. With the increasing granularity of the IP being traded, metadata is never likely to come from a single source or to follow a single standard for identification and description. If metadata from different sources is to interoperate successfully, it must, though, be developed within a coherent and consistent view of the things that are being described so that such views can be successfully mapped to others. Central to the analysis is the assumption that it is possible to produce a generic mechanism to handle complex metadata for all different types of IP. So, for example, instead of treating sound carriers, books, videos and photographs as fundamentally different things with different (if similar) characteristics, they are all recognised as creations with different values of the same higher-level attributes, whose metadata can be supported in a common environment. Any serious approach to the problem of interoperability of metadata for IP in the network environment needs to support interoperability of at least five different types:
The <indecs> project proposed a framework, described in detail in the final project documents, within which such interoperability could be achieved. As part of the project, several principles were stated that have proved to be key to the management of identification:
<indecs> also produced a useful definition of metadata:
This provides a concise paraphrase of much of the <indecs> framework. It stresses the significance of relationships, which lie at the heart of the <indecs> analysis. It underlines the importance of unique identification of all entities (since otherwise expressing relationships between them is of little practical utility). Finally, it raises the question of authority: the identification of the person making the claim is as significant as the identification of any other entity. 3.3 Further development of the <indecs> framework: a methodology for contextual data dictionariesThe <indecs> framework was developed further (by CONTECS, a consortium of parties including the International DOI Foundation and trade bodies in the audio-visual sectors) as a methodology for semantic interoperability, with the specific aim of responding to the MPEG requirement for a Rights Data Dictionary. Whilst "crosswalks" can be constructed to compare terms in any two metadata schemes, the total number of such crosswalks grows much faster as the number of schemes grows linearly (N schemes require (N/2)(N-1) mappings). The existence of one dictionary "hub" reduces this to N mappings, one for each scheme. Bilateral agreement between dictionary and scheme ensure that the existence of agreed mapped terms enables extensibility – mapping to another scheme – without reference to the originators of each scheme. Such mappings will increasingly be computable and thus automated. Mapping through a hub only works if the hub is sufficiently rich (one to one mappings are preferable to mapping through an inappropriate hub); the model of mapping introduced in the <indecs> project has now been expanded into a contextual, events-based ontology that provides a means of precise definition and so allows rich interchange between metadata schemas. It is widely recognised that ontologies are the key to semantic automation [14]. The methodology was reviewed and accepted as the basis for ISO/IEC 21000-6 (MPEG Rights Data Dictionary, RDD) by the ISO/IEC MPEG working group [15]; it has also been used to develop similar specific dictionary tools, which are instantiations of the same process, and has strongly influenced revision and development of the ONIX family of standards in the book and serials sectors. The collection of these efforts might usefully be referred to as the "<indecs>-based semantic interoperability" initiatives.3.4 Relation to other semantic mappingsFormal grammars of the type used in XML cannot convey any information about the meaning of data elements (except for human-readable descriptions in comment elements). Formal representation of semantics has been a research topic for decades and is now increasingly becoming used in applications. A data model that has undergone semantic analysis at an abstract level can be expected to remain unchanged in a changing environment for much longer than a model that is based on an analysis of current requirements alone. Such analysis of semantic issues has been extraordinarily useful in the context of some metadata projects: in addition to <indecs> two more specialised efforts are noteworthy:
The "<indecs>-based semantic interoperability" initiative and these efforts recognise that they have much in common, and some attempts are being made to investigate areas of commonality. Representatives from RDA, CIDOC, EDItEUR and Rightscom (the most advanced implementers of the contextual ontology model) have launched a joint initiative to develop a common framework for resource categorization [19] with the aim of providing some high level connection between the standards for the future, by agreeing a common top level ontology for carrier/content types that will serve both further ONIX developments in multimedia (see below) and RDA (the new version of AACR2). This may be through an extension to the basic Abstraction/Performance/Fixation/Item groups (and FRBR's version of these) for RDA. 3.5 Practical applications of semantic interoperabilitySeveral activities are already seen (by some of the participants at least) as potential candidates for this approach. Using one technology initiative applied to a range of problems could clearly generate both (a) economies of scale for implementation and (b) critical mass of support. Some nascent initiatives in individual sectors are coming to see that issues of interoperability and extensibility cannot be solved by one body alone, and that adoption of a standards-based approach offers the best way forward. 3.5.1 ISO TC46/SC9 identifier interoperabilityAs described in section 2, ISO TC46SC9 interoperability work will likely result in the need for a registry for metadata semantics for all its content identifiers. It is attractive to consider this approach as a potential solution; an ISO standard that could provide a common basis for identifier semantics and be promoted to other activities would add considerable value. We referred above to the potential role of ISO/IEC 21000-6 in supporting typed links between identifiers (relators), and to the potential development of a taxonomically structured glossary including reference descriptive metadata to support the development of all TC46 SC9 standards. These activities, and the further suggested development of a schema to facilitate interoperability between reference descriptive metadata sets (hub and spoke mapping), are exactly analogous to the work already done in the <indecs>-based interoperability studies and development for ISO/IEC 21000-6. 3.5.2 Digital Object IdentifiersDigital Object Identifiers [20] are actionable persistent identifiers that include a mechanism for the management of metadata, using a data dictionary to precisely define referents, and a grouping mechanism (Application Profiles) to relate sets of DOIs with common properties. Resolution of a DOI involves the retrieval of a record that includes reference to metadata about the referent object; a DOI Resource Metadata Declaration (RMD) is a form of message designed specifically for the exchange of metadata between DOI registration agencies to support their service requirements. Since a DOI can be assigned to any entity, at any level of granularity, it is necessary to provide a formal mechanism for description and interoperability, using – where appropriate – existing metadata mapped using a standard dictionary. The metadata elements specified in the DOI system are mapped through a Data Dictionary that is built on the same principles as, and includes as a subset, the ISO MPEG 21 Rights Data Dictionary specified in ISO/IEC 21000-6. Compatibility with this data dictionary provides semantic interoperability between DOI metadata and the metadata element sets used by other systems that are similarly mapped. The IDF's Data Dictionary is at present an internal development tool and is not publicly available. However, the creation of the public ISO/IEC 21000-6 dictionary (for which IDF is the MPEG21 Registration Authority), an instantiation of the same <indecs>-based ontology process, offers an easy means of expanding mappings across these different "views". 3.5.3 ONIX: licensing terms and multimediaThe ONIX family of standards is a well-structured and well-accepted tool for electronic commerce in the book and serials sectors. The ONIX family of standards are already informed by, and compatible with, the <indecs>-based ontology approach; a declared aim of ONIX is to share a dictionary based on <indecs> semantic interoperability principles with other activities (such as DOI) [21]. ONIX is now expanding into the more complex areas of including licensing and multimedia, both of which require a rich semantic interoperability. EDItEUR [22], the body co-ordinating the development, promotion and implementation of ONIX, is developing standards for the communication of licensing terms, ONIX for Licensing Terms, building on earlier joint EDItEUR / NISO work on ONIX for Serials and the work of the Digital Libraries Federation's Electronic Resource Management Initiative (ERMI) [23]. EDItEUR has used the ERMI requirements as the foundation of its work in developing its ONIX for Licensing proof of concept model. Complementing this, the National Information Standards Organisation, DLF, EDItEUR, and the UK Publishers Licensing Society (PLS) have formed a License Expression Working Group to review needs for standards relating to electronic resources and license expression, and engage in the development of the ONIX license messaging specification. ONIX for Books Release 3.0, due early next year, will deal more thoroughly with multimedia products than have previous releases. Some preliminary work is underway on extensions of ONIX to multimedia as part of a European project. 3.5.4 Music Industry Integrated Identifiers ProjectOther projects have already developed their own dictionaries on the same principles of semantic interoperability, independent of other efforts. One of the most advanced examples of practical implementation of these concepts is the Music Industry Integrated Identifiers Project (MI3P) [24]. MI3P is developing an infrastructure for the music industry value chain that will enable the development of automated transaction processing in a music e-commerce environment, through integrated standards for identification and description of releases, sound recordings, musical works and licences. A number of key standards have or are being developed. These include the Global Release Identifier Standard (GRid) and the Musical Work Licence Identifier Standard (MWLI) designed to be applied respectively to electronic Releases that might embody sound recordings, music videos and other digital content, and to Licences issued in respect of the musical works contained within those Releases. The MI3P Data Dictionary [25] provides the canonical definition of all elements to be used in associated message standards and other framework components. 3.6 ISO/IEC 21000-6 implementationThere are increasing demands for metadata interoperability in both the commercial media and library sectors, and the semantic interoperability technology developed from the <indecs> model has a role to play in addressing these. The ISO/IEC 21000-6 dictionary is a limited one, with one clear initial role as a component of MPEG-21: the one task of the RDD specifically mentioned in the standard is to support the MPEG REL (Rights Expression Language), though it embodies many useful generic concepts such as relators for typed links between identifiers. It will clearly not be a single giant resource for all content interoperability mappings, nor will it take advantage of all potential ontology tools: there are obvious commercial difficulties in creating such a single resource. Nonetheless as the first public, and standard, implementation, there is great potential in using this initiative as a rallying point, and perhaps starting point for further development, creating both economies of scale and critical mass of support. The most effective route to ensure this would be to promote the adoption of ISO/IEC 21000-6 as a solution for other initiatives that encounter the same problem of semantic interoperability, where this meets the needs. CONTECS members have agreed that the most effective route would be through promoting the adoption of ISO/IEC 21000-6 rather than any further implementation, to which end consortium members have agreed to support the ISO/IEC 21000-6 Registration Authority becoming operational, and to make the CONTECS technology available to other parties. As a step towards this, the International DOI Foundation intends to widen the base of governance and support of the ISO/IEC 21000-6 for which it acts as Registration Authority. Among ways being actively considered, since the ISO/IEC JTC1 directives require a governance procedure for e.g., disputes, a Registration Authority Management Group could be created to oversee the dictionary's operation. That Management Group could include representatives of key sector bodies and stakeholders. Note1 Section 2 is closely based, with permission, on the report of the Dec 2005 ISO TC46/SC9 identifier interoperability workshop prepared by Mark Bide of Rightscom Ltd., which itself was based on input from the registration agencies responsible for ISAN, ISWC, ISRC, ISAN and DOI, and invited experts.References[1] ISO: International Organization for Standardization: <http://www.iso.org>.
[2] ISO TC46 SC9 home aage: <http://www.iso.org/iso/standards_development/technical_committees/ [3] Renato Iannella: Digital Rights Management (DRM) Architectures D-Lib Magazine. <doi:10.1045/june2001-iannella>. [4] The original report is document N417 of ISOTC46SC9; "Use cases for interoperability of ISO TC46/SC9 identifiers: background information for agenda item 9.7 of the ISO TC46/SC9 meeting in Chiang Mai, Thailand." <http://www.collectionscanada.ca/iso/tc46sc9/docs/sc9n417.pdf>. [5] MPEG home page: <http://www.chiariglione.org/mpeg/>. [6] Jeroen Bekaert: Using MPEG-21 DIDL to Represent Complex Digital Objects in the Los Alamos National Laboratory Digital Library. D-Lib Magazine. <doi:10.1045/november2003-bekaert>; Using MPEG-21 DIP and NISO OpenURL for the Dynamic Dissemination of Complex Digital Objects in the Los Alamos National Laboratory Digital Library. D-Lib Magazine. <doi:10.1045/february2004-bekaert>. [7] Godfrey Rust and Mark Bide: The <indecs> Metadata Framework: Principles, model and data dictionary (2000): <http://www.doi.org/topics/indecs/indecs_framework_2000.pdf>. [8] <indecs> Directory of Parties: Outline specification: <http://www.indecs.org/pdf/DirectoryofParties.pdf>. [9] InterParty project: <http://www.interparty.org>. [10] Drury & Burnett "MPEG-21 in a Backpack Journalism Scenario" IEEE Multimedia, October - December 2005 12(4) 24-32: <http://ro.uow.edu.au/infopapers/10/>. [11] Glossary of terms and definitions in International Standards developed by ISO/TC 46/SC 9: <http://www.collectionscanada.ca/iso/tc46sc9/standard/glossary.htm>. [12] ISO/IEC 21000-6 RDD Registration Authority, http://www.iso21000-6.net>. [13] <indecs> project home page: <http://cordis.europa.eu/econtent/mmrcs/indecs.htm>. [14] Ian Horrocks, "Ontologies and the Semantic Web": <http://www.epsg.org.uk/pub/needham2005/>. [15] CONTECS:DD Press Release 3 June 2004: ISO Publication of the MPEG Rights Data Dictionary Standard, ISO/IEC 21000-6: <http://www.doi.org/news/contecsdd_standard_pr.html>. [16] Functional Requirements for Bibliographic Records: Final Report: <http://www.ifla.org/VII/s13/frbr/frbr.htm>. [17] Joint Steering Committee for revision of Anglo-American Cataloguing Rules: RDA – Resource Description and Access: <http://www.collectionscanada.ca/jsc/rda.html>. [18] CIDOC Conceptual Reference Model homepage: <http://cidoc.ics.forth.gr/index.html>. [19] "RDA and ONIX Launch Joint Initiative": Joint Steering Committee for Revision of Anglo-American Cataloging Rules, News and announcements. 11 April 2006. <http://www.collectionscanada.ca/jsc/rdaonixann.html>. [20] Digital Object Identifier system: <http://www.doi.org>. [21] IDF Press Release, April 2003: Common Dictionary for DOI and ONIX Metadata: <http://www.doi.org/news/030415dictionarynews.pdf>. [22] EDItEUR home page: <http://www.editeur.org>. [23] DLF Electronic Resource Management Initiative: <http://www.diglib.org/standards/dlf-erm02.htm>.
[24] and [25] MI3P home page: <http://www.mi3p-standard.org/> and MI3P Data Dictionary: <http://www.mi3p-standard.org/specification/MI3P-DICT-10-FDS.pdf>. (Links for references [2], [7], and [13] were updated on September 8, 2008, at the request of the author. Also at the request of the author, on February 10, 2009, a note was added to references 24 and 25 to direct readers to new websites for current information.) Copyright © 2006 Norman Paskin |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Top | Contents | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
D-Lib Magazine Access Terms and Conditions doi:10.1045/april2006-paskin
|