| ||
D-Lib Magazine
|
|
|
Kurt Maly |
![]()
AbstractThere are a number of ways a service provider can provide a resource discovery service across several data providers, that is, several digital libraries. In the harvesting approach, the service provider harvests the metadata of the digital libraries and uses them for unified resource discovery. A recent standardization effort, the Open Archive Initiative (OAI), defines a standard, open interface between data providers and service providers to implement digital library interoperability based on the harvesting approach. The intention of OAI is to support data providers (archives) that exist at an organizational level. A typical data provider is a digital library that has no constraints on how it implements its services with its own set of publishing tools and policies. However, to be part of OAI, a data provider needs to be "open" in as far as it needs to support the OAI metadata harvesting protocol. In this paper, we propose the Kepler framework1 based on OAI to support what we call "personal data providers" or "archivelets". The objective of the Kepler framework is to satisfy the need for average researchers at an average university to publish results and disseminate them quickly and conveniently to a wide audience. While this primary objective is the result of our personal experience, we believe the concept can be extended to any community that wishes its publications to be made available to a wide audience over the Internet. We have a reference implementation for the Kepler framework that we call a digital library of many "little" publishers. In particular, we have implemented (a) an easy-to-use archivelet that is downloadable and self-installing, (b) an automated registration service to support tens of thousands of publishers, and (c) a simple service provider to harvest metadata from archivelets. 1. IntroductionTransparent resource discovery occurs when the average researcher can find needed papers without having to go to each of any number of individual digital libraries. One of the biggest obstacles to transparent resource discovery is the fact that many digital libraries use different, proprietary technologies that do not allow for interoperability.
Of the three approaches, the federation approach is the most demanding and requires considerably more cooperation from the participating digital libraries. The gathering approach is the least demanding; however, quality suffers regarding the coherent set of digital library services it can provide. In this work, we focus on the harvesting approach. Harvesting provides a unified interface to discover information from different digital libraries and is not as demanding as the federation approach. To achieve DL interoperability in our harvesting based approach, we use the open OAI protocol to communicate between data provider and service provider. The intention of OAI is to support data providers (archives) that exist at an organizational level. A typical data provider would be a digital library, yet no constraints are imposed on how the digital library implements its services with its own set of publishing tools and policies. To be part of OAI, however, a data provider needs to be "open" in as far as it needs to support the OAI metadata harvesting protocol. In this paper, we propose the Kepler framework based on OAI to support what we call "personal data providers" or "archivelets". The objectives of the Kepler framework are to:
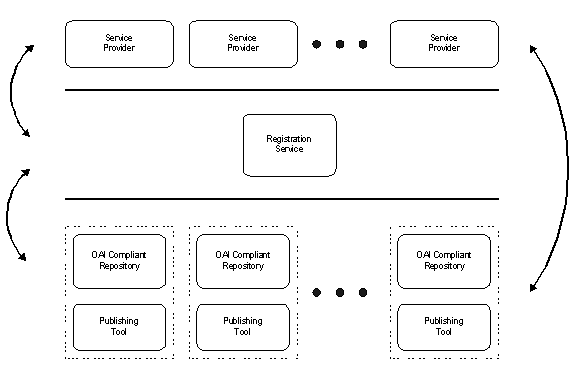
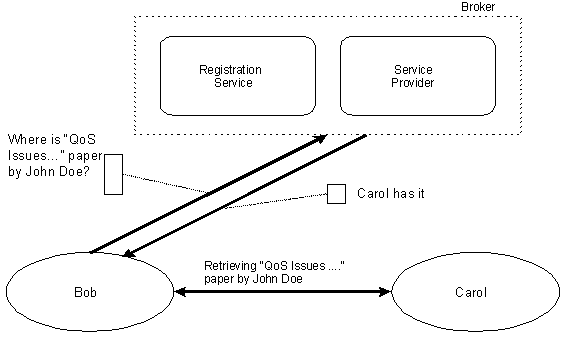
In this paper we address the self-publishing part of the first goal and the unified-access goal. In our vision, we shall create a self-contained, self-installing software package that easily allows a researcher to create and maintain a small, OAI-compliant archive -- archivelet. We shall create an OAI-compliant service provider that will harvest metadata from all existing archivelets and make them available to the general public. In this vision, we see tens of thousands of researchers creating their own personal archive housed on a variety of machines in different network environments ranging from the sophisticated direct Internet access at the university to a home computer connected only by a modem during certain times. One or more service providers will make all these archivelets available seamlessly to any user as if they were all one large digital library. In section 2 of this article we describe the Kepler framework, and in section 3 we give the details of our reference implementation. In particular, we have implemented (a) an easy-to-use archivelet that is downloadable and self-installing; (b) an automated registration service to support tens of thousands of users; and (c) a simple service provider to harvest metadata from archivelets. Sections 4 gives our initial experience with the prototype and directions for future research and development. 2. Kepler FrameworkWe believe that two factors are critical to the success of any digital library effort: simplicity of use and control. Hence, we strongly feel that the publication tools to create an archivelet should be a downloadable, platform-independent, software package that can be installed on individual workstations and PCs, rather than software that is installed by organizational system staff. For example, the eprints.org OAI-compliant software package exists, but its heavy footprint reflects its intended institutional-level service [2]. The archivelet needs to have an extremely easy-to-use GUI for publishing and needs to be an OAI-compliant data provider. Since we want to be as independent as possible of other software and we expect the archivelet to store relatively few objects, we shall use the native file system to store the objects rather than, for example, a database system. In supporting archivelets, the registration service takes on a bigger role than the registration server plays in regular OAI. The number of archivelets is expected to be on the order of tens of thousands, and their state in terms of availability will show great variation. Currently, the OAI registration service keeps track of OAI-compliant archives and the current registration process is mostly manual. In contrast to data providers at an organizational level, archivelets will switch more frequently between active and non-active state. It will be necessary for the registration service to keep track of the state of the registered archivelets in support of higher-level services. For this, we borrow the concept from Napster and the instant-messenger model where the central server keeps track of active clients. The OAI presents a technical and organizational metadata harvesting framework designed to facilitate the discovery of content stored in distributed archives. The framework consists of two parts: the definition of a set of simple metadata elements (for which OAI uses Dublin Core [3]), and the definition of a common protocol to enable extraction of document metadata and archive-specific metadata from participating archives. The OAI also defines two distinct participants: data provider and service provider. A data provider is the manager of an archive; a service provider is a third party, creating end-user services based on data stored in the archives. The current OAI framework is targeted for large data providers (at the organization level). We propose the Kepler framework based on the OAI to support archivelets that are meant for many "little" publishers. The Kepler framework promotes fast dissemination of technical articles by individual publishers. Moreover, it is based on interoperability standards that make it flexible so as to build higher-level services for communities sharing specific interests. Figure 1 shows the four components of the Kepler framework: OAI compliant repository, publishing tool, registration service, and service provider. The OAI compliant repository along with the publishing tool, also referred to as the archivelet, is targeted for individual publishers. The registration service keeps track of registered archivelets including their state of availability. The service provider provides high-level services such as a discovery service that allows users to search for a published document among all registered archivelets. The Kepler framework supports two types of users: individual publishers using the archivelet publishing tool, and general users interested in retrieving published documents. The individual publishers interact with the publishing tool and the general users interact with a service provider and an OAI-compliant repository using a browser. In a way, the Kepler framework looks very similar to a broker based Peer-to-Peer (P2P) network model [4] (Figure 2). Typically, a user is both a data provider and a discovery user that accesses a service provider. Thus the primary mode of operation might be construed as one of exchanging documents. Given our notion that the Kepler framework is for the "little" person with few resources (i.e., home computer accessed through a modem), services beyond resource discovery that we envision developing in the future include review and archiving services. One key issue we needed to address in the Kepler framework was the issue of scale. The intention of OAI has been to support a contributing audience consisting of few (relatively speaking -- currently it is an order of ten expanding to an order of hundreds) data providers, each representing a digital library with a large holding (on the order of a hundred thousand to a million objects). In the Kepler framework, the opposite is true: each data provider has only a few objects (e.g., an order of a hundred) but there may be, if the Kepler framework is successful, tens of thousands (or if extended to all interested persons, maybe millions) of such archivelets. The second issue we faced, normally not present in the regular OAI environment, is the issue of unreliable up-time of the machine that houses the archive(let).
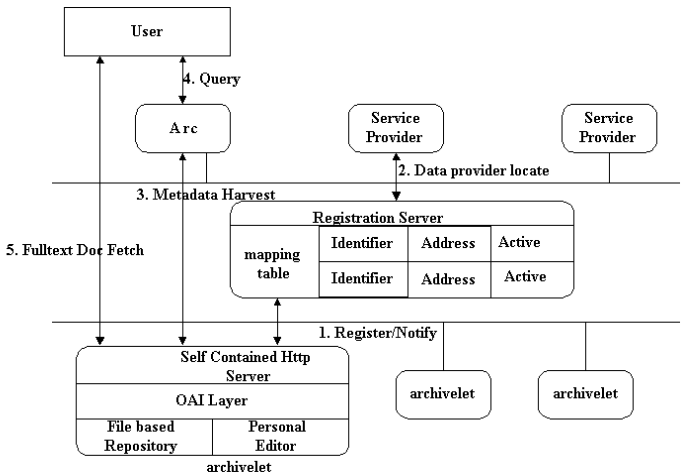
2.1 ArchitectureIn Figure 3 we show how we are addressing these issues at an architectural level. A registration server allows new archivelets to register, and the server also is used to keep track of the archivelets active/inactive time. That is, each archivelet lets the registration server know when it goes off-line. The registration service needs to be able to handle tens of thousands of entries. A service provider uses the registration server to locate all Kepler archivelets for whatever service it wants to provide. For example, the one labeled "Arc" is a discovery service that harvests metadata from all known archivelets on a daily basis for updates and changes. Some of these services may also need to know when an archivelet is active. The information we need to keep in the mapping table of the registration for each unique archivelet identifier is its current IP address and its state. |
|
|
|
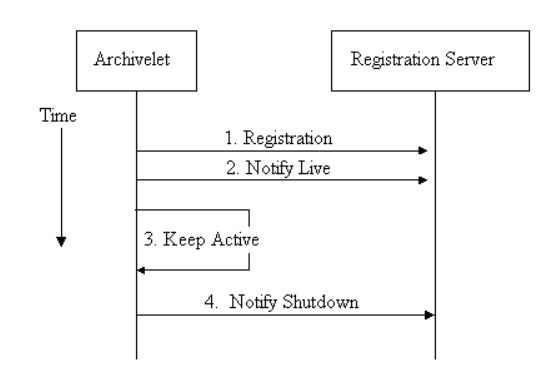
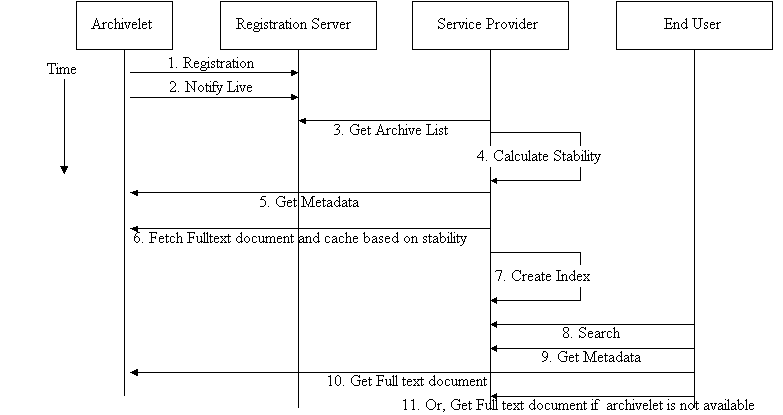
The archivelet combines the OAI-compliant repository and the publication tool in a downloadable and self-installable component. We provide http transport as specified in the protocol, but only OAI requests are supported, not any other http actions. The basic service part of Kepler is the discovery service -- Arc. There are a number of issues related to such a service and to basic OAI itself. They include: consistency between service and data providers, harvesting scheduling, fault tolerance, and data provider overload. Most of these issues are discussed in the paper on Arc in this issue of D-Lib Magazine. Here we want to address the issue of unreliability specific to Kepler. When a discovery user poses a query to Arc, we need to return not just the metadata of the hits matching the query, but we also need to get the state of the archivelets that contain the hits. At this stage, we propose three modes for full-text fetching. One is simple: do nothing beyond providing the URL and letting the user know if the machine that houses the web server is accessible. A second model caches an archivelet before it goes off-line. The third model caches the most frequently accessed documents themselves. In this model, frequency is measured across all users accessing Arc and all archivelets registered with Kepler. 2.2 Operational UsageIn Figure 4 we show the process an archivelet must go through first to register and then to notify the server of its state of availability (e.g., being on- or off-line). In Figure 5 we have shown the flow of activities as they occur in the model, where the service provider caches the documents of the archivelets when needed so it can provide full-text fetch when a query comes for the document even though the archivelet is off-line. Notice step 6 where the service provider, and not the discovery user, fetches the document and caches it based on some historical information of the archivelets behavior. In step 10, the service provider still goes to archivelet to fetch the document, when a hit has been made, to make sure it has the latest version; only when the archivelet is off-line will it use the cached copy. |
|
|
|
If we do not use caching, the process would consist of steps 1, 2, 3, 5, 7, 8, 9 and 10 from Figure 5. The third model can be realized by making the last step (get full-text document) consist of the following: if the document is in the cache at the service provider, return it to the discovery user; in either case record the usage pattern and, if indicated, cache it at the service provider. 3. Prototype ImplementationThe prototype system we have implemented as a first feasibility step uses an LDA- based registration system. For the service provider we have used a modified Arc. Arc uses an Oracle database to create the index for the harvested metadata. Using the OAI protocol, the service provider harvests daily, asking for updates from the last successful harvest. It keeps a list of successful harvests with the registration service. The location of all registered archivelets is made available upon request from the registration service. An example of the information kept in the LDAP database is shown in Figure 6.
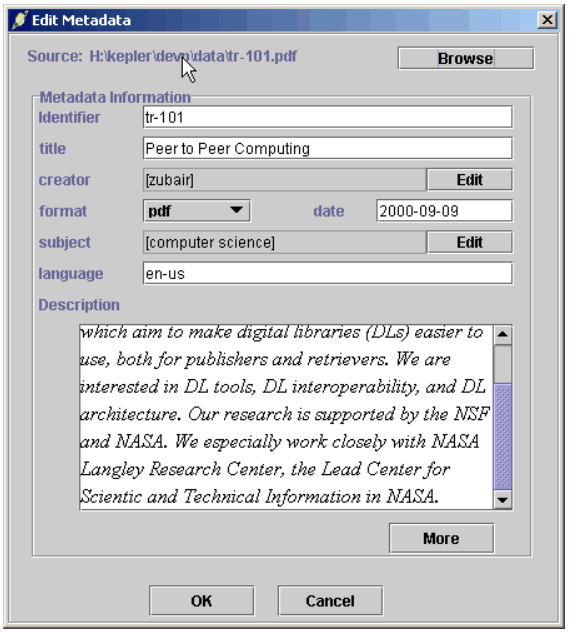
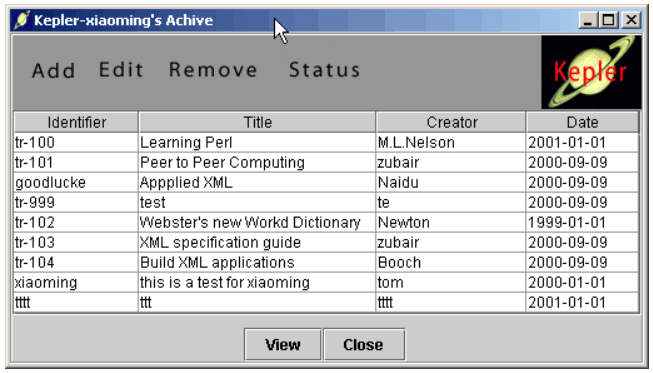
The publication tools consist of a simple display of the archive and a tool to specify metadata and upload files into the archivelet, and these tools are shown in Figures 7 and 8. The publication tools, together with the client for the automatic registration process and the client to interact with the service provider (the OAI layer and the simplified web server), have been packaged together with the Java virtual machine (and necessary Swing classes) into a self-installing zip file that can be downloaded from the Kepler home page <http://kepler.cs.odu.edu>. Finally in Figure 9, we show the display of one particular object found through searching with Arc. The display shows selected metadata together with the URL of the document in the archivelet that will be either served by the web server of the archivelet if it is on-line, or by the service provider otherwise. However, in the latter case it will only be a cached copy and may not be the most recent one.
|
|
|
4. Conclusions and Future WorkKepler's main purpose is to show the feasibility of a new paradigm of publishing and discovering scientific information. Kepler is based on and enabled by the OAI, which is gaining acceptance in the digital library research community. Kepler is motivated by the length and complexity of the current publication process used by existing digital libraries and professional societies, and provides another possible implementation to the vision of author self-archiving [5] In addition, it is also motivated by the success of P2P systems such as Napster and widely-used Web search engines such as GoogleTM. Finally, Kepler is motivated by the observation that most people who publish scientific material want simple publication tools and processes and, perhaps most importantly, want to retain control over their material. We have built a prototype system that self-installs on any machine with no prerequisites (such as having a particular Java environment) and that handles all the interactions with the registration server and a standard service provider -- Arc. Arc provides a discovery service that ties all known archivelets together to make it appear to the discovery user that all of them form one large digital library. The current version is experimental, not fully tested and has not been officially released; it can be accessed at the Kepler home page <http://kepler.cs.odu.edu>. We have not yet demonstrated (but plan to do so in the future through simulation studies) that the architecture will scale to tens of thousands of publication users. Similarly, an important task for the future will be an investigation as to what model of solving the unreliability issue is most appropriate for this publication paradigm and which model delivers the best performance. Finally, we plan to address the other goals, set out in the introduction, as to how we can add value to this paradigm by adding review and annotation services. 5. AcknowledgementsOur thanks to Michael Nelson for providing valuable input and reviewing the manuscript; and Jianfeng Tang and Naveed Shaik for implementing some of the modules for the prototype. 6. Note[Note 1] The Kepler framework is named after the great theoretician, Johannes Kepler. According to Carl Sagan in his book Cosmos, Kepler struggled to get data from his sponsoring colleague, Tycho Brahe, the great observationalist. Only when Brahe was on his deathbed did he finally give Kepler access to all his data. 7. References[1] The Open Archives Initiatives. <http://www.openarchives.org>. [2] About the eprints.org Software. <http://www.eprints.org/software.html>. [3] OCLC, The Dublin Core: A Simple Content Description Model for Electronic Resources. <http://purl.org/DC>. [4] Bob Knighten, Peer-to-Peer Working Group. <http://www.peer-to-peerwg.org/>. [5]Harnad, S. Free at Last: The Future of Peer-Reviewed Journals. D-Lib Magazine, 5(12), December 1999. <http://www.dlib.org/dlib/december99/12harnad.html>. Copyright 2001 Kurt Maly, Mohammad Zubair, and Xiaoming Liu |
|
| |
|
|
Top
| Contents |
|
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/april2001-maly
|