D-Lib Magazine
November 1999
Volume 5 Number 11
ISSN 1082-9873
Cross-Organizational Access Management
A Digital Library Authentication and Authorization Architecture
David Millman
Columbia University
[email protected]
Abstract
An architecture to enable cross-organizational access management of web-based resources is described. The architecture uses digital certificates and secure directory services to implement decoupled authentication and authorization functions. It improves management information and enables more flexible service possibilities without compromising individual privacy.Introduction
Over the last year, the Digital Library Federation (DLF) initiated a pilot project to investigate a new architecture for networked service provision across organizational boundaries. The architecture, described below, attempts to solve a longstanding problem in access management while enabling new service possibilities.
The participants in the pilot are two suppliers of networked information, the Online Computer Library Center (OCLC) and JSTOR, and two consumer institutions, The University of California and Columbia University.
The architecture is based on existing standards: the X.509 standard for digital certificates and the LDAP directory standard. It uses the former to guarantee the identity of the consumer (authentication) and the latter to enable service provision based on the characteristics of the consumer (authorization). The architecture provides improved access, privacy, efficiency, flexibility and richer management information. We call it the "Digital Library Authentication and Authorization Architecture" or DLA3.
Our model arose in the context of licensed information resources in university libraries. But it is actually quite general, and might apply to many situations in which an organization supplying information restricts access to particular individuals at other organizations.
Motivation
Internet information service providers typically manage access in three ways: by establishing individual passwords, by network topology (IP address) restrictions and, a special case of the latter, using web "proxies." All of these methods have significant problems.
When a service provider establishes id's and passwords for individual customers, it is often duplicating a part of an infrastructure already in place at the customer's institution. For example, most universities have existing infrastructure to manage individual email accounts, library circulation records, access to administrative services, etc. This infrastructure usually includes substantial policies and processes for adding and removing individuals, and for maintaining status information about an individual's eligibility to access different resources. In a university setting, the population itself, as well as any individual's status, is especially dynamic. While information service providers invest considerable effort to create user accounts and passwords, it is nearly impossible for them to accurately reflect the dynamic communities of the consumer institutions. Such systems are also inconvenient for individuals, who must keep track of separate id's and passwords for each information service they use. And consumer institutions must rely entirely on the service provider for any management information, as they have no other way to measure the usage of their own community. The principal advantage of this method is that it permits service providers to create customized services for each individual.
Access management by IP address is, of course, widespread. In this case, the service provider limits access to those portions of the Internet administered by the licensing consumer institutions. While it was always an imprecise strategy, this method is increasingly problematic. Many members of consumer communities are working from locations separate from the institution's network: at home, through commercial Internet Service Providers (ISP's), through newer commercial high speed dialup services. Distance education programs promise to make this situation even worse. One's membership in the institutional community has less and less to do with one's physical location. It is practically impossible for service providers to create customized services for individuals, and management information is again only available to providers, and is rather imprecise.
In the proxy approach, requests to the service provider are routed through a gateway, the proxy, located within the consumer institution's network. Individuals must authenticate, i.e., provide credentials such as an id and password, to gain access to the proxy (therefore requiring an institutional infrastructure for authentication). The proxy then forwards their service request to the provider and must dynamically adjust each web page returned by the provider before it reaches the individual's browser, editing each link back to the provider so that the proxy remains in the path of all transactions. Service providers cannot create customized services and can collect only minimal management information, because all institutional transactions appear to come from a single address (the proxy's). Proxies have been traditionally difficult to program, configure and manage. And recently, as more service providers take advantage of javascript and java to enhance functionality, proxies are increasingly unable to make the required edits and thus fail to operate at all. Another proxy approach (sometimes called a "mechanical" proxy) avoids the editing problem by routing all of an individual's web requests through the proxy. But this method introduces other problems, including potential conflicts in browser configuration and computational bottlenecks.
These access management problems have been discussed at great length elsewhere (Lynch, 1998). Our team sought an architecture that would address the problems of all these traditional approaches.
We met in January, 1999 in Oakland, CA. The team developed a set of principles and a transaction protocol, defined a set of directory attributes and created an extension to the X.509 certificate. The participants were Joan Gargano (University of California, Office of the President), Ariel Glenn (Columbia University), Rebecca Graham (Digital Library Federation), Sal Gurnani (UC), Leah Houser (OCLC), David Millman (Columbia), Spencer Thomas (JSTOR) and Vance Vaughn (UC).
Principles
The architecture follows these principles:
Privacy. No information identifying an individual to the service provider need be exchanged. But, for any particular set of information resources, different degrees of anonymity may be used. For example, "pseudoanonymous" identity may be appropriate, in which a provider can tell if the same person visits more than once but cannot tell who they are (e.g., "user1234"), or certain demographic data may be exchanged in appropriate circumstances. In the default case, the service provider knows only that the individual is an authorized member of the consumer institutional community. Any further information about the individual must be explicitly negotiated: either chosen by the individual and/or agreed to in advance between the service provider and the consumer institution.
Partitioning of information. As far as is possible, both the consumer institution and the service provider should hold information over which they have primary responsibility, respectively. Redundant information should be minimized. For example, if a service provider offers a service customized for each individual, it should arrange for exchange of pseudoanonymous identity with the consumer institution rather than attempt to duplicate institutional id systems. Or, if a consumer institution subscribes to a number of different sets of services from the same service provider it should arrange for the establishment and exchange of a service class identifier with the service provider, encoding the sets of services (i.e., using a "serviceName", described below).
Separation of Authentication and Authorization. An individual's membership in an institutional community should not, in itself, imply what particular services are permitted. For example, alumni and faculty may have access to quite different sets of resources. Also, as mentioned, an individual's status and capabilities may change over time. This architecture requires that authentication be performed through a digital certificate and that authorization be performed through a distinct transaction with an authorization (or "attribute") server.
Transaction Model
Under this architecture, a transaction would proceed as follows:
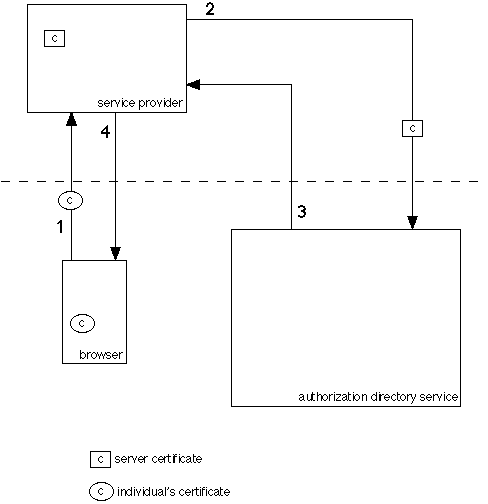
Figure 1. Transaction model.
Note that the dashed line represents an organizational administrative boundary, and not a physical or network topological boundary.
- An individual within the consumer institutional community requests information from a remote service provider. Establishing the SSL (encrypted session) network connection, the individual's digital certificate is sent by the browser. The service provider validates the individual's certificate.
- The service provider extracts information from the individual's certificate, and uses it to locate the institution's authorization server, contact it and request the status of the individual. Establishing this secure connection requires that the service provider present its own certificate to the authorization server.
- The authorization server checks the validity of the service provider's certificate. If valid, it returns attributes concerning the individual's status with respect to this service provider back to the provider in the form of a list of attribute names and values.
- From the authorization server's response, the service provider decides to either deliver the service or an error message back to the individual.
In the first part of the transaction, the service provider must act on two key components: the validity of the certificate received and the ability to initiate the authorization process. Our assumptions for the former were that there be mutual agreement on the contents of, at least, the "Issuer" field of the certificate and that certificates will be issued in accordance with acceptable Certificate Practice Statements (CREN 1999 and Verisign 1998, for example). In our pilot, both of the consumer institutions acted as their own Certificate Authority (CA) and so, for the pilot, agreement on the Issuer field alone was sufficient. When the consumer institution does not act as its own CA, Issuer in combination with another certificate field can accomplish the same goal. (Precisely which other certificate field is still under discussion.)
The authorization process begins as the service provider extracts an X.509v3 extension field from the individual's certificate, the "Query URL." This extension field was developed for this architecture and is registered with ISO under the administration of the Council on Library and Information Resources, parent organization of the Digital Library Federation (see Appendix for details). This URL should be either an LDAPS (secure directory lookup) or HTTPS (secure HTTP) format. Our pilot used LDAPS exclusively and has defined a result format for LDAPS only. Aside from this level of protocol, the rest of the Query URL should be considered opaque by the service provider. The Query URL must contain enough information to identify the individual requester to the authorization facility but, as mentioned above, the service provider should not presume to discover this identity by inspection of the Query URL. For example, temporary random identifiers might be used in the Query URL to identify the individual.
Because the operations use secure network protocols, the service provider and the authorization facility must also possess server certificates. In the same way the individual delivered their certificate to the service provider originally, so the service provider delivers its certificate to the authorization facility. Using the provider's certified identity, using the "Issuer" and "Subject" fields, the authorization server can adjust the query result per provider, returning only appropriate information previously agreed upon.
Authorization is implemented by associating a set of attributes to each institutional user. The most critical is the repeatable attribute "Service Class." Each institutional user will probably have a number of Service Class attributes. We define Service Class as an ordered triple. The fields of Service Class are currently human-readable strings for convenience. A Service Class is:
- vendorName. This should uniquely map to a service provider.
- serviceName. This is intended to distinguish among sets of services that may be offered by the same service provider. For example, in our pilot the consumer institutions subscribed to several different packages of services from OCLC, while JSTOR offered only a single service.
- serviceType. Intended to specify the individual's level of access to the particular service. For example, library staff will have different access from undergraduates for the same service. Again from our pilot: JSTOR provides the same level of access for all institutional individuals, while for OCLC this field was an account code.
It was clear that vendorName should correspond uniquely to each service provider, and that this mapping will be used to insure that service providers will only be presented with Service Classes pertaining to themselves (i.e., one provider may not see Service Class values for other providers). It is our hope that serviceName and serviceType are sufficiently flexible to accommodate a wide variety of access possibilities.
In any case, the service provider receives the Service Class information from the authorization facility and decides whether or not to deliver the service requested by the individual, based on the serviceName, serviceType and on the consumer institution.
In addition to the Service Class(es) for the individual, the authorization facility also may deliver these attributes:
- Statistical Role. To provide necessary management information, this field will be supplied by the consumer institution and will be used by the service provider as an aggregation key for statistical reporting to the consumer institution. It is not precisely defined by this architecture but should be negotiated and mutually agreeable. We strongly recommend conformance to the guidelines set forth by the International Consortium for Library Consortia (ICOLC, 1998).
- Persistent Identifier. To enable individual-based services and state information of individuals for the use of service providers, this identifier must be unique within the consumer institution population. Its precise format and lifetime are not defined here, but it must never be mappable to any public identifier for an individual. This suggests a hashed value, such as MD5.
- Access Denied Message. In cases where the service provider cannot deliver its own appropriate error message to the requesting individual, this field should be sent. Again, its format is not yet defined.
Other attributes may be returned to the service provider as well (demographic information, for example). The precise set of attributes delivered must be negotiated in advance.
This model may dramatically improve the acquisition of management information for both the service provider and the consumer institution -- in the former case, by providing appropriate attributes and in the latter, by analysis of the authorization server traffic.
Public Key Infrastructure Issues
This process doesn't address the way in which an individual obtains an appropriate certificate in the first place and how they install that certificate into their browser. Methods vary, depending both on the browser itself and on the public key infrastructure and procedures in place at the consumer institution. This is a critical requirement but is of a larger scope and should be addressed independently from this architecture.
Two distinct kinds of certificate management are implied by this architecture, for servers and for individuals.
As mentioned, in order to operate secure network connections, service providers and authorization servers must possess certificates. The number of such certificates is relatively small, perhaps only one or two per organization. Methods for obtaining such certificates and for establishing peer to peer trust for this application appear to be straightforward and reasonably priced.
Establishing a public key infrastructure for individuals at large institutions is much more complex, involving legal and policy work in addition to the technology changes. And it may have a significant financial impact.
Distribution of individual certificates raises a number of issues, such as portability (e.g., home vs. office) and manipulation of multiple certificates for different purposes (e.g., university services vs. banking services). Shared workstations are common in higher education and pose particular distribution problems. And current browsers have relatively poor certificate manipulation interfaces.
While this architecture may be considered an early, cutting edge application of PKI, it is entirely consistent with the efforts of Educause (Educause 1999), CREN, and the federal government (NIST, 1998) to promote standards-based inter-organizational secure communications.
Future Work, Next Steps
We believe our pilot has successfully proven this architecture can work from a technical point of view. But a number of items need more clarification before this model can move into a scalable production setting. And there are a few open issues.
Formal specifications and procedures must be in place so that this model can be integrated into licensing negotiations between service providers and consumer institutions. Agreement on the precise contents of certificate fields and procedures to communicate changes in certificate hierarchy are needed.
As mentioned, the Statistical Role, Persistent Identifier and Access Denied Message have not been sufficiently defined. These elements need to be tested further, and must eventually become part of the service provider licensing negotiation process. It is also possible for an individual to have multiple Statistical Roles or multiple Service Classes for the same service, although it is not clear how these cases should be handled.
Certificate revocation is not discussed here, and is relevant in the larger PKI context. For individuals' certificates, our model can implement this function informally by simply denying access to such individuals in the authorization process.
We have not specified any particular caching guidelines. It appears reasonable that caching should happen per individual "session" and not for every transaction. Caching would, of course, affect traffic analysis measures and so should be designed carefully and described clearly.
As mentioned, attributes returned by the consumer institution's authorization server are currently defined only for LDAPS protocol query/response. We have not designed or tested an HTTPS (secure HTTP) transaction but believe this to be an important alternative. We presume, in this case, the attributes and values would be encoded in XML.
It takes considerable labor at the consumer institution to implement an authorization service. Enterprise-wide high-performance directory infrastructures are relatively new and appear primarily at large research institutions. These infrastructures are an important investment, independent of this particular application. But to quickly make use of this architecture it may be more straightforward for an institution to begin with the HTTPS alternative. We would like to extend our pilot in this direction as soon as possible.
Our decision to use LDAPS made sense functionally: it is designed to return attribute-value pairs. But only the most recent implementations support secure connections and the use of certificates for authentication. Some custom programming was necessary. Using HTTPS would eliminate portions of that effort.
While still a work in progress, this architecture has made substantial headway toward a more secure, private, accurate and at the same time a more flexible access management framework. Organizations interested in participating in these next steps should contact Rebecca Graham at the Digital Library Federation.
References
CREN, 1999. "CREN's Certificate Authority Service", Corporation for Research and Educational Networking, <http://www.cren.net/cren/caindex.html >
Digital Library Federation, <http://www.clir.org/diglib/dlfhomepage.htm >
Educause, 1999. PKI For Networked Higher Education Working Group, NET@EDU <http://www.educause.edu/netatedu/contents/groups/#2 >
ICOLC 1998. "Guidelines for Statistical Measures of Usage of Web-Based Indexed, Abstracted, and Full Text Resources", International Consortium for Library Consortia, <http://www.library.yale.edu/consortia/webstats.html >
Lynch, 1998. C. Lynch, ed., "A White Paper on Authentication and Access Management Issues in Cross-organizational Use of Networked Information Resources". Coalition for Networked Information. Revised Discussion Draft of April 14, 1998. <http://www.cni.org/projects/authentication/authentication-wp.html >
NIST, 1998. "Overview of the NIST Public Key Infrastructure Program: working towards the development of a Federal PKI," National Institute of Standards and Technology, <http://csrc.nist.gov/pki/program/welcome.html >
Verisign, 1998. "Certification Practice Statement", Versign, Inc. <http://www.verisign.com/repository/CPS/ >
Appendix: X509 Extension and Attribute Definitions
Certificate extension, OID 1.2.840.114006.1000.1:
id-clir OBJECT IDENTIFIER ::= {iso(1) member-body(2) us(840) 114006} id-clir-dla3 OBJECT IDENTIFIER ::= {id-clir 1000} id-clir-dla3-queryURL OBJECT IDENTIFIER ::= {id-clir-dla3 1} The query is either LDAP over SSL or HTTP over SSL. The query string must comply with the syntax of RFC 2255 for LDAPs, except that the query shall start with the string "LDAPS" instead of "LDAP". Or with RFC 1630 for HTTPS, except that the query shall start with the string "HTTPS" instead of "HTTP". In the case of an LDAPS query, the SASL EXTERNAL method of authentication shall be used, as described in the Internet draft "Authentication Methods for LDAP" (IETF, 1998).Attribute response from the authorization facility:
serviceClass ::= SEQUENCE { vendorName OCTET STRING, serviceName OCTET STRING, serviceType OCTET STRING } statisticalRole ::= OCTET STRING persistentID ::= OCTET STRING accessDeniedMessage ::= OCTET STRING
Copyright © 1999 David Millman
Top | Contents
Search | Author Index | Title Index | Monthly Issues
Previous story | Next story
Home | E-mail the EditorD-Lib Magazine Access Terms and Conditions
DOI: 10.1045/november99-millman