![]()
| Search | Back Issues | Author Index | Title Index | Contents |
|
|
D-Lib Magazine
|
New content and services for 19th century American documentsThe Perseus Digital Library is releasing a collection that introduces significant new content and brings new technologies and services to a mainstream digital library. All XML source texts of the collection are available under an open source license. All software is likewise designed as open source. XML TaggingAll of the markup in the example shown in Figure 1 was automatically added. Buell and Corinth are correctly interpreted George P. Buell and Corinth, MS. General John Pope – a dominant figure in this text – is never mentioned by his first name. The system thus mistakenly links Pope to "Curran Pope," named twice elsewhere in the document. The XML tagging includes both the rule used ("most common") and the number of times that Curran has been mentioned in the text (2). 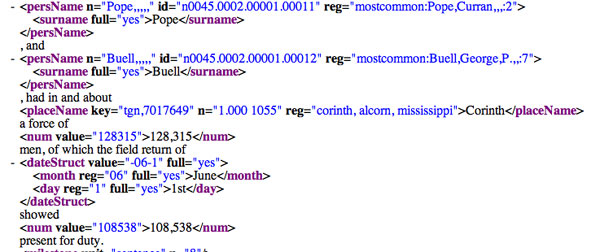
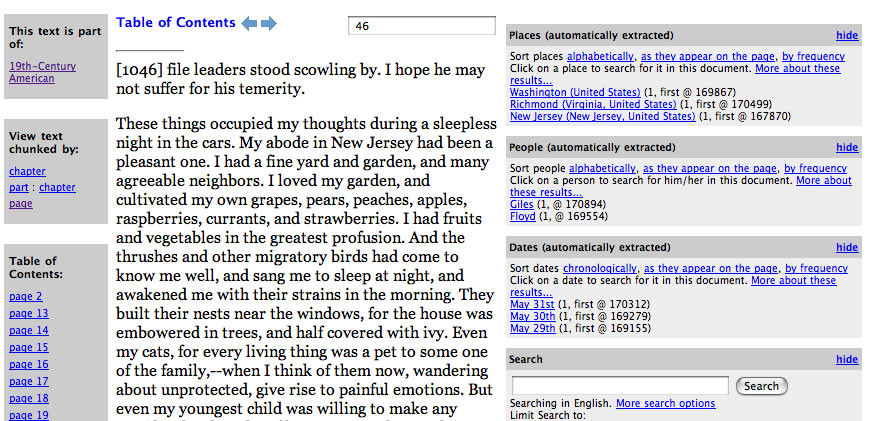
Figure 1. Sample Page ViewFigure 2 shows a representative page from the 19th century collection as seen in the Perseus digital library interface. The right hand side contains a range of added services (designed to become Fedora disseminators) relevant to the text. In this case, we see a summary of people, places and dates on a particular page of text. The digital library system can chunk documents in various ways and could, in this case, provide a chapter at a time. 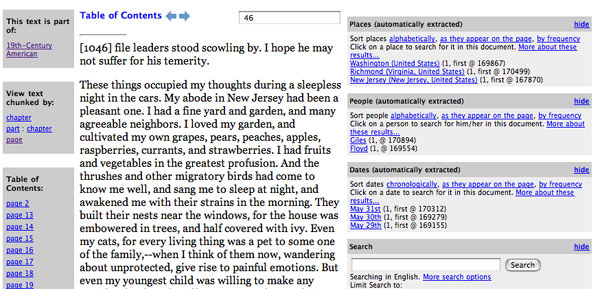
Figure 2. Personal Name SearchingSearching for people with the last name Webster calls up the list shown in Figure 3. Since Daniel and Noah Webster are pre-eminent figures in their domains, Webster often appears in documents without a forename. We have chosen to defer automatically aligning possible name variants (e.g., Daniel Webster and D. Webster) since we were not satisfied with initial results. We expect to reactivate this feature in a more sophisticated form in the future. 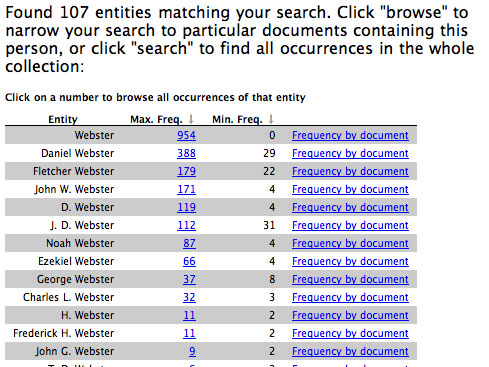
Figure 3. Frequency SearchingAlmost all of the Richmonds in our collection denote Richmond, VA. The example shown in Figure 4 illustrates the results for Richmond, KY: the results include two figures. In the document with the most potential references to Richmond, KY, the system reports that there may be as many as 71 references but probably at least 16. The lower figure, which maximizes precision, reports phrases such as "Richmond, Kentucky", where the language makes it highly likely that we have the right Richmond. The higher figure includes all those Richmonds that could be Richmond, KY. Given the pervasive references to Richmond, VA, many of the 71 will be false positives. 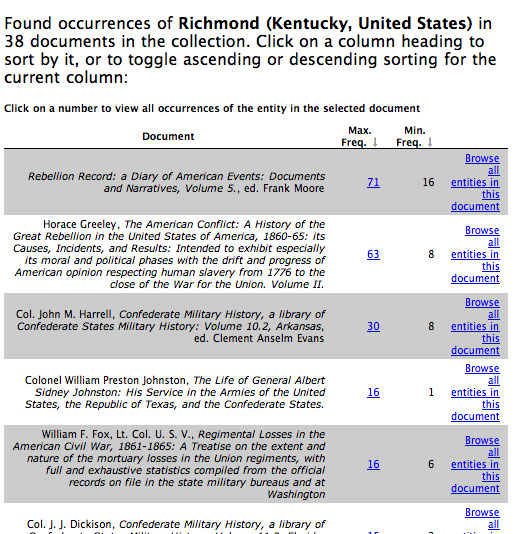 Figure 4. Our named entity identification system tuned for 19th century historical materials has extracted from the 55 million word test collection 1.5 million personal names, 1 million place names, 600,000 dates, 500,000 organization names, and 12 million auomatically generated annotations. While we have extracted dates and places in the Perseus Digital Library since 2000, the new system is optimized for the challenges posed by American English, which contains both semantic ambiguity (e.g., Washington can be a person or a place) and which uses the same names over and over again (there were more than 150 places named Washington in mid nineteenth century America). This system lays the foundation for a general web service to tag named entities in documents that could process up to 1 billion words in a day. The current database of named entities from the initial test collection can be expanded to cover all pre-twentieth century American English publications. For the technical details and general performance of the system, see Crane and Jones. A new release of the Perseus Digital Library System includes an initial interface whereby users can browse and search semantically:
Collection DescriptionSources on 19th century American culture and especially the US Civil War: This release includes a test collection of 55 million words, with a number of core works on the Civil War. Our purpose was to create a testbed whereby we could study the problems and opportunities presented by various genres of 19th century American English. Content includes:
Acknowledgements The foundations for this work were laid with support from the National Endowment for the Humanities and the National Science Foundation under the DLI-2 Initiative. Tufts University provided support for much of the data entry, and the open source policy championed by its president, Lawrence Bacow, has allowed us to make the XML source texts accessible. The Institute for Museum and Library Services and our collaborators at the University of Richmond in their Civil War Newspapers Project provided much of the support for developing the backend named entity analysis system and the digital library named entity searching and browsing environment. Gregory Crane scanned most of the American books, supervised their OCR, post-processing into TEI-conformant XML and was primarily responsible for the named entity analysis system. Adrian Packel built the named entity searching and browsing environment. Lisa Cerrato, Alison Jones, David Mimno, and Gabe Weaver all made major contributions to the work. |
Copyright© 2006 Gregory Cranedoi:10.1045/march2006-featured.collection |
{kind=link}