|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2011
Volume 17, Number 1/2
Abelard and Héloise: Why Data and Publications Belong Together
Eefke Smit
International Association of STM Publishers
smit@stm-assoc.org
doi:10.1045/january2011-smit
Abstract
This article explores the present state of integration between data and publications. The statistical findings are based on the project PARSE.Insight, which was carried out with the help of EU funding in 2008 - 2010. The main conclusion drawn from these findings is that currently very few conventions and best practices exist among researchers and publishers in how to handle data. There is strong preference among researchers and publishers alike for data and publications to be linked in a persistent way. To achieve that, we advocate good collaboration across the whole information chain of authors, research institutes, data centers, libraries and publishers. DataCite is an excellent example of how this might work.
1. Introduction
Like Abelard and Héloise, research data and research publications belong together. Even if the two lead separate lives, wanted or not, they do remain wedded throughout their lives. The lives of Héloise and Abelard were linked via their intense correspondence — and the story goes that they were reunited in their joint grave at the Paris graveyard Père Lachaisse to be together in perpetuity. [1]
Likewise, in the context of preservation of data and research publications, it is also important that this couple is linked — to be curated for access and reuse in conjunction. Researchers often fear that those who reuse their data may take them out of context, misinterpret them, or otherwise misuse them. This has resulted in a call for better metadata around research data. But what better metadata can one think of than the formal research article? Is it not the official version of record, as officially peer reviewed and published, that will explain background, context, methodology and possibilities for further analysis in the best possible way, and express the intentions of the person who helped collect the data?
Before the analogy between research output and one of the most famous love couples in history takes us too far, this article wishes to make the point that there is great value in good and persistent linking between data and publications.
2. Making data available
Publishers have long advocated the opportunity for governments and/or funders to play a beneficial role in promoting access to raw or researcher-validated primary data.
In the Brussels declaration of 2007 [2], signed by a long list of STM publishers and their associations worldwide, it was stated:
"Raw research data should be made freely available to all researchers. Publishers encourage the public posting of the raw data outputs of research. Sets or sub-sets of data that are submitted with a paper to a journal should wherever possible be made freely accessible to other scholars."
It was also in 2007 that Microsoft researcher Jim Gray addressed the National Research Council in the US [3] to point out how the availability of data and the increasing ease of sharing them, may alter the nature of scientific communication. He said, before he sadly disappeared at sea in 2007:
"Experimental, theoretical, and computational science are all being affected by the data deluge, and a fourth, "data-intensive" science paradigm is emerging. The goal is to have a world in which all of the science literature is online, all of the science data is online, and they interoperate with each other. Lots of new tools are needed to make this happen."
It now appears that activity is taking place. In the U.S., the National Science Foundation (NSF) released a data-sharing policy. Starting on January 18, 2011, NSF grant applicants must include a data management plan detailing how they will share research results. And at the other side of the Atlantic, in 2010 the High Level Expert group in the EU published its report on scientific data: Riding the Wave, how Europe can gain from the rising tide of scientific data [4]. The report illustrates the rise in data and its ubiquitous presence. It makes a strong statement for conserving and sharing, using and reusing available research data, for having an e-infrastructure that facilitates this with reliable places to deposit data, and for a system that anchors trust and security about quality and provenance of data. In an October comment during the release of the report, EU Vice President Neelie Kroes said:
"We need to ensure that every future [research] project funded by the EU has a clear plan on how to manage the data it generates. Such plans should foster openness and economies of scale, so that data can be re-used many times rather than duplicated. ...We all should strive to make real progress towards open access to the scientific data produced within the EU's framework programme research projects."
But what does this mean for the relationship between data and publications? In 2010 project PARSE.Insight was concluded. It undertook a survey and several case studies about the preservation of every kind of research output, ranging from raw data all the way to final publications. The International Association of STM Publishers was one of the project partners, together with research institutes, research funders and national libraries.
The project [5] was carried out with the help of EU funding in 2008—2010. The main conclusion in this context is that very few conventions and best practices exist currently among researchers and publishers in how to handle data. (See http://www.parse-insight.eu/ for the full report.) There is strong evidence that researchers and publishers want data and publications to be linked in a persistent way.
3. Data, data everywhere
The surveys and case studies carried out under project PARSE.Insight add a useful view across all scientific disciplines, compared to many other studies that have generated data about data, but usually only in a specific research discipline. Responses from roughly 1200 scientists from all over the world indicate how conventions on what to do with data are as good as absent nowadays. As the graph in Illustration No. 2 shows, there is no single destination for data — in fact, you will find data everywhere, with the scary observation that most data remain on the individual researcher's computer, on their computers at work (> 80 %), or even on computers at home (> 50 %). Then there are hard disks and institutional servers, but only very few datasets get stored safely at a digital archive, be it at the organisation (< 20 %) or a subject-specific archive (< 10 %).
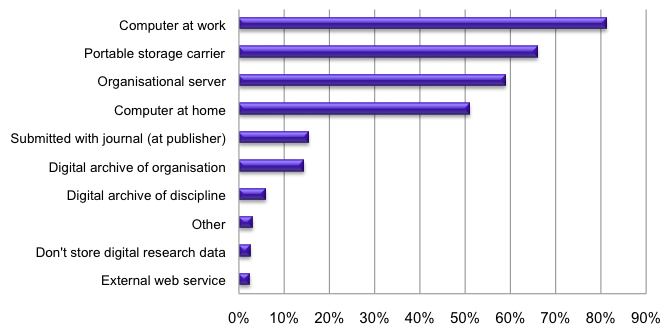
Illustration No. 2
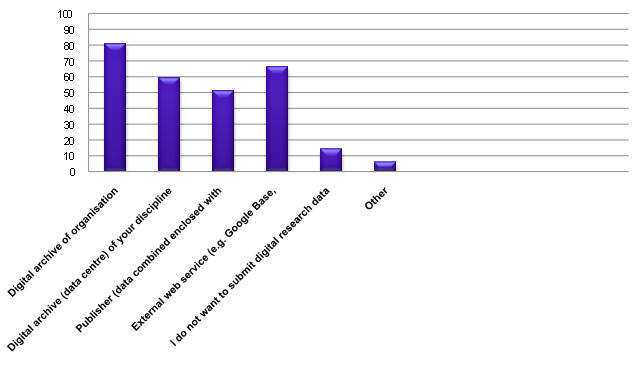
Illustration No. 3
Another interesting observation is that many researchers, as many as over 50%, would like to submit their data to publishers enclosed with their research papers as submitted to scholarly journals. This is most likely related to the strong wish of researchers to have data and publications linked. (See also Section 5. Linking Publications and Data).
4. Deluge or Tsunami
It hardly needs emphasizing that the data deluge is only at its beginning. The amount of data stored per research project is now estimated by researchers to be in the order of mega- and giga-bytes, but will soon shift to tera- and peta-bytes. (See Illustration No. 4.)
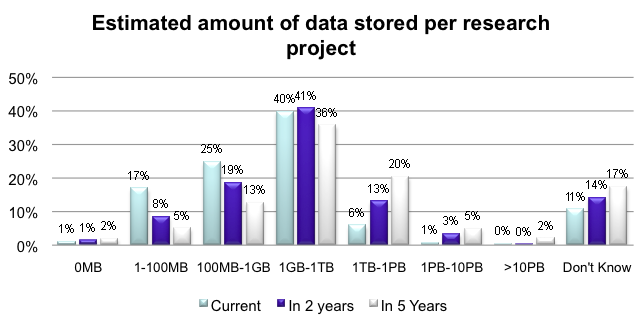
Illustration No. 4
5. Linking Publications and Data
Reflecting the findings in the previous paragraphs of the absence of single behavior patterns, very few researchers (only 28%) find and access data via a Data Center or an Archive. Many (63%) find relevant data, if not via their colleagues (73%) and general searches (63 %), via the formal literature. (See Illustration No. 5) Institutional databases account for another 57% (multiple answers possible).
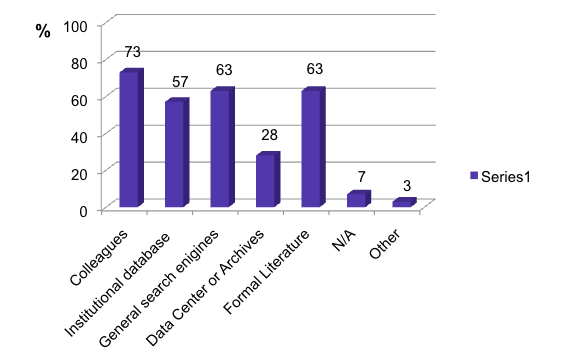
Illustration No. 5
For researchers, it is therefore very important that available data and the publications about the data remain connected. Not surprisingly, 85% of the responding researchers in the PARSE.Insight survey find links between data and the formal literature useful.
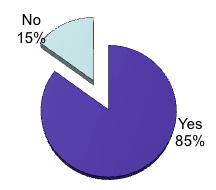
Illustration No. 6
In general, authors can submit but are hardly ever required to add the data to their publications. See the survey responses in the illustrations below explaining how very few journals officially require that authors include such data, while according to publishers most journals do provide the facility for it. Note: on the survey addressed to publishers, 134 publishers responded, representing 37% of all journals. The larger publishers represent <90 % of all journals covered in the survey.
i.e., data used to create tables, figures, etc.? (Researchers, N = 1202)
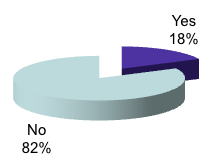
Illustration No. 7
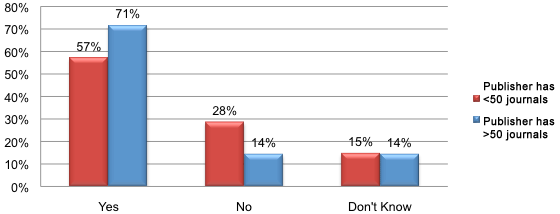
Illustration No. 8
6. What Publishers do
Publishers are fairly generous in the variety of data they accept supplementing the submitted research article and this variety most likely reflects the multidisciplinary reach of the survey.
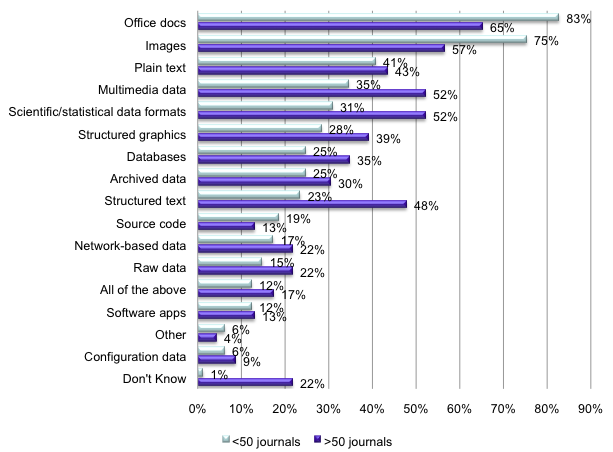
Illustration No. 9
But the picture gets sketchy if we wish to know what publishers do with these data in terms of validation and quality control, in terms of linking, and in terms of preservation measures. See the illustrations below for the responses received on questions about these issues.
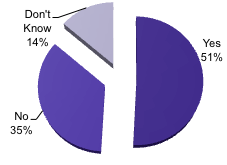
Illustration No. 10
is it possible for users of that digital research data to link to it? (Publishers, N = 134)
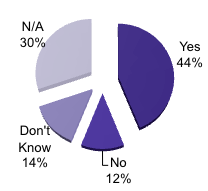
Illustration No. 11
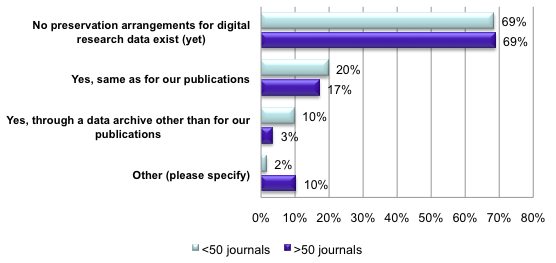
Illustration No. 12
The majority of 'no' respondents for preservation of submitted data is especially scary. If data are not preserved, how can future access and reuse of data be secured? It is not that publishers are not aware of the importance of digital preservation, because an overwhelming majority of 84% do have a preservation policy for their own publications.
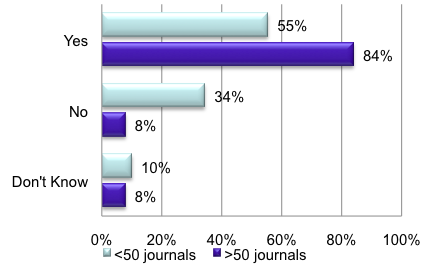
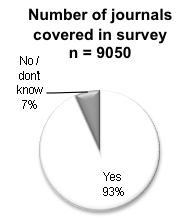
Illustration No. 13
7. Future Outlook: the need for Conventions and for more Convergence
So, what can we learn from all these data about data? I believe the following facts are quite clear.
- Researchers would like to submit their data to archives and to publishers, but at present keep their data in many different ways without necessary measures for preservation, access and reuse by others.
- Researchers locate data in a patchy way: via colleagues, general searches and via the formal literature. They like data and publications to be linked.
- Publishers accept data submitted with publications in a wide variety of ways. But what happens to the data in terms of validation, linking and accessibility does not follow general standards or conventions. Preservation of data other than formal publications is not well managed by the publishers at the moment.
- Most journals facilitate the submission of data together with an article manuscript. But the journals to which the researchers submit do not generally require the inclusion or availability of underlying research material.
In the context of data volumes that are about to explode in size, it is time to get certain conventions in place and to work across the information chain of researchers, publishers, datacenters and libraries towards more convergence. This is necessary also against a background in which trust has to be built. The same PARSE.Insight survey indicated that a large number of researchers are reluctant to share their own data as long as certain trust issues are not resolved. They do not want their data to be used out of context, they want to be credited when the data is re-used, and they want certain privacy and legal aspects to be secured.
Good connections with formal publications help to put this in place, at least partly. Publications are richer in content and better understandable if underlying data is available, while at the same time pointers from data to the publications that use and mention them can ensure that the data is properly understood and put in the right context by next users. What better metadata can anyone think of than the full publication about the data?
Links between data and publications also make it easier to properly cite datasets and indicate their provenance.
Hence, what is needed with regard to data and publications, is the following:
- Journals to require availability of underlying research material as an editorial policy
- More careful treatment of submitted digital research data by those who accept them
- Ensure data is stored, curated and preserved in trustworthy places
- Ensure links (bi-directional) and persistent identifiers between data and publications
- Establish uniform citation practices of data
- Develop data-publications and quality standards
8. Supporting DataCite
DataCite is an excellent initiative that can offer easy solutions for the proper storage and curation of datasets and their linking with publications. If authors submit difficult datasets to publishers, it will make everybody's life easier if publishers can direct authors to trusted and certified datacenters recognised by and collaborating with the DataCite network. These will register and supply Digital Object Identifiers (DOI® names) for deposited datasets to link the publication and the data in a persistent way.
Datacenters are likely to be better placed than publishers for proper quality control and preservation of data that is supplemental to publications. The DOIs will facilitate good citation practices. The STM publishing community has good experiences in working with DOIs as they are the backbone of persistent refence linking via CrossRef. Extending this to proper referencing and linking of datasets is unlikely to pose any technical barriers on the side of publishers.
This will make data and publications as inseparable as Abelard and Héloise, in perpetuity.
9. Reference and Useful Links
[1] See for example http://classiclit.about.com/cs/articles/a/aa_abelard.htm, http://en.wikipedia.org/wiki/Helo%C3%AFse_(abbess) and http://en.wikipedia.org/wiki/Peter_Abelard.
[2] Brussels declaration of 2007, signed by the international scientific, technical and medical (STM) publishing community, 2007.
[3] Jim Gray on eScience: A Transformed Scientific Method. Based on the transcript of a talk given by Jim Gray to the NRC-CSTB1 in Mountain View, CA, on January 11, 2007.
[4] "Riding the wave: How Europe can gain from the rising tide of scientific data", Final report of the High Level Expert Group on Scientific Data; A submission to the European Commission, October 2010.
[5] See PARSE.Insught and Alliance for Permanent Access.
About the Author
 |
Eefke Smit is Director Standards and Technology at the International Association of Scientific, Technical and Medical Publishers. This is a global association of more than 100 scientific, technical, medical and scholarly publishers, collectively responsible for more than 60% of the global annual output of research articles, over half the active research journals and the publication of books, reference works and databases. It represents all types of STM publishers — large and small companies, not for profit organisations, learned societies, traditional, primary, secondary publishers and new entrants to global publishing. Eefke Smit brings a background of more than 25 years in publishing with experience in e-publishing. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |