|
Search | Back Issues | Author Index | Title Index | Contents |
![]()
D-Lib Magazine
|
|
|
Julien Masanès |
![]()
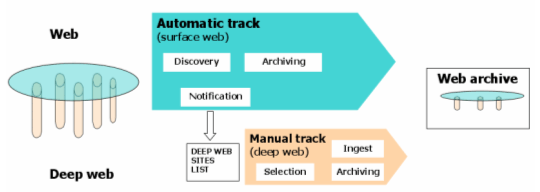
1. IntroductionThe Web has become one of the major channels for dissemination of culture and knowledge. Consequently, there is a growing awareness of the need to track and archive Web content. Pioneering work in this regard began in 1996 by the Australian, Canadian and Swedish national libraries and also by the Internet Archive, a US-based non-profit foundation. These institutions have been using two different approaches for archiving the Web. The Australian [1] and the Canadian [2] national libraries have been exploring a selective approach based on pre-selection, capture and cataloguing of individual Web sites. This approach uses a selection policy adopted to restrict the scope of candidate Web sites for archiving. The Swedish [3] National Library and the Internet Archive [4] have been archiving the Web based on automatic harvesting policies using tools called "crawlers". Crawlers had already been developed for other types of information retrieval on the net. They allow a much broader scope for archiving Web content, but they do not provide for the monitoring of individual sites or adapting the archiving frequency of those specific sites. These pioneering efforts have contributed to rising awareness about the possibility for, and necessity of, web archiving. An increasing number of national libraries are now engaged in building, or are planning to build, web archives, and many other institutions like universities are starting topic related projects [5]. The need to develop common tools and enable information exchange on the topic of Web archiving has already been addressed by the NEDLIB European [6] project, which initiated the development of an open source crawler that meets specific functional requirements such as harvesting priorities (for example, trying to lower the total delay for archiving a single site to keep a consistent image of it). Within the small but growing community of web archivists [7], possible collaborations and joint projects are openly discussed [8]. Those involved in the discussions hope that effective collaboration will be possible in the future to help the community face difficult but fascinating challenges. In this article, I will outline the contribution of the national library of France (BnF) to this discussion. At BnF, we began a research project on Web archiving in late 1999. Our project experiments have been ongoing even as the legal deposit law has been in the process of being updated—a process that has not yet ended. Our work on Web archiving is divided into two parts. The first part is to improve crawlers for continuous and adapted archiving. This means being able to automatically focus the crawler for satisfactory archiving. Apart from getting existing, hands-on tools, this part of our project, which is presented in this article, consists of defining and testing good parameters toward that aim. The second part of our work is testing every step of the process for depositing web content. In our view, deposit is a necessary part of archiving the Web, because a large amount of very rich Web content is out of the reach of crawlers. This hidden content is often called the "deep web", and it consists mainly of large document repositories accessible only through descriptive information stored in relational databases (see, for instance, the 30 million digitized pages from the Gallica collection at <http://gallica.bnf.fr>). During the workshop on Web Archiving [9] at the 2002 European Conference on Digital Libraries (ECDL), I presented results from a pilot study on archiving deep web sites. Before going into more detail about improving crawlers in this article, let me first explain how our project envisions articulation of online harvesting and deposit.
2. Towards Continuous Surface Web ArchivingThe snapshot approach and its limitationsUp to now, on-going projects based on automatic tools have gathered what we call "snapshot" collections. Ironically, one of these snapshot collections is anything but instantaneous. The single capture period for a snapshot extends for months because the amount of data to be collected is huge. What we finally get are temporally based slices of a collection. Consequently, each site is only archived once every two to six months, no matter what the site is. Though harvesting content from some sites (steady or cumulative ones) at such intervals may be adequate, for most sites it is not adequate (think for instance of newspapers sites). As trying to increase the frequency of global snapshots costs too much, the only solution is to refine the collection process by adapting the capture frequency to each site and/or change the perimeter of the crawl. Valuation of page dynamic and incremental crawlerSuch adapted crawls can take into account only the site change rate or, at least, an estimation of the change rate. This estimation has long been implemented in search engine robots. When a first snapshot is completed, the robot checks for updates without actually loading documents, which saves a great deal of time. The http protocol makes this possible, even though it is based on information provided by servers, which is not terribly reliable. The second crawling round being much more rapid, the robots can make another harvest, for example, the week after, and again and again, until the robots get an estimation of the change rates for every page in the database at a day- or even an hour-level. Using this information, archivists can then set their robots to more frequently refresh particular pages. For archiving purposes, one might be reluctant to utilize information provided by http servers (which are often only roughly configured). In that case, it is possible to load the document and perform one's own change valuation. This can be useful when trying to make a better change appraisal (for instance, excluding time stamps or visiting counters on HTML pages, mostly dynamically generated ones). Research to evaluate site-level, adapted diff functions may also be helpful in this regard [10]. Change frequency estimation can then be made on a more reliable basis, and the rest of the process can be the same as described above. Even with change rate estimation, there is still a trade-off between the updating and breadth of the collection, but change rate estimation dramatically improves achievements in both dimensions [11]. Focusing the crawlAnother non-exclusive procedure is to adapt capture frequency, taking into account not only a particular site's intrinsic dynamic but also the relative importance of each site. Evaluating site importance or relevance allows one to focus the crawl on specific parts of the web in order to ensure that these parts will be archived and monitored appropriately. However, this is not an all-or-nothing choice. One can assign various levels of priority to sites for crawling and also for archiving (which may be different). This makes it possible, for instance, to perform a yearly global snapshot and then to focus additional crawls on subsets of the Web so that these subsets are archived as often as necessary. Discovering or manually adding new sites and manually changing parameters in the database can be done "on the fly" in such a process. It may be important to have different priorities for crawling and archiving. For instance, it might be interesting for discovery purposes to frequently crawl certain URLs but not archive them each time. Here again, focusing the crawl and the archiving process would dramatically improve the Web archive and help us face the continually growing amount of publicly accessible information on the Internet. Overall, focused crawls would help in building coherent collections for which the collection extent and freshness would be defined according to a documentation policy rather than determined by technical or financial limitations. (I don't feel comfortable with the perspective of having to justify myself in a few years saying "We don't have this site because we had to stop the robot after its two-month blind trip".) Importance estimationThe question remains: Is it possible to define relevant and automatically computed parameters to focus a robot on only that part of the web we want to archive? Of course, other national libraries may have different policies in this regard, just as they have different collection policies for traditional publications. It is not my intention to discuss here the variety of existing and possible choices in this domain. But we should try to set down a policy on parameters, and the key issue is: What parameter can we use? At the BnF we have tried to explore in two directions, but other directions could certainly appear in the future. The first direction we explored is framed by the traditional librarian approach based on published material (contrary to a traditional archivist approach). The problem is that the notion of what constitutes "publishing" (to make some content "publicly available") has been greatly broadened due to the low cost of making content available on the Internet. As Internet "publishing" is almost cost-free, the traditional editorial filter seems to be no longer needed, or at least can be by-passed easily. This means that material can be "published" on the Internet without professional appraisal of the significance or relevance of that material. National libraries cannot replace the workload of all the traditional publishers and, on their own, filter this proliferating mass of content. This doesn't mean selection of sites can't be done on the Internet. It just means that national libraries can't select all the content on the Internet needed for the collections they are used to building and archiving through legal or copyright deposit. However, many persons actually do select content on a very small scale using links. Extracting the link structure at the scale of the global Web tells us much about what is "visible" in the Web space. In a very broad sense, sites that have more in-going links can be considered as the more relevant or significant sites [12]. At least, it is a hypothesis that we have been testing at the BnF. Before presenting our test results in more detail, I offer a few comments on our approach. Using a global computation of the link structures is a way for us to stick to something similar to the previously mentioned notion of publishing. If making something "publicly available" on the net becomes insignificant in and of itself, let's try to refine and focus on some part of it—the most "public" one, which in a hypertext space is the most linked one. This type of computation has proven its efficiency for ranking query results on particular keywords (see Google's success, based on utilization of the now famous algorithm, PageRank [13]). Of course, the context in which we propose to use this information is quite different. The main difference is that Google is able to efficiently rank pages, given a specific set of query terms. Google computes an absolute ranking from the global matrix of all links, but this ranking is only used each time in a subspace defined by the query terms. Using this type of ranking to define a global selection policy is different. Two particular risks arise in the selection policy context: The first risk is to under rank valuable sites on a very specific domain. For instance, highly specialized research topics may be represented by only a few sites with few links, even if these sites are to become very important in the future. The second risk is—on the contrary—to over rank some sites, mainly very well known sites that may have little value for archiving, like document-like weather forecast sites or sites that may be of low priority for long term archiving (like e-commerce sites). Analyzing the link structure is not a very efficient means to avoid these risks, as we will see in the results of our study. However, robots can obtain other types of information, like linguistic information, that help define selection policies. That is the second direction in which we are working at BnF. Following are a few words on this work, which is just beginning. The presence of rare words is a particular feature of focused topic-related sites, for instance. These rare words can be good indicators of valuable, though specialized, sites that aren't discerned from the global linking matrix. Rare word appraisal could therefore be used to balance the pure ranking-based appraisal. We are currently testing this at the BnF on a sample of ranked sites for which a "rare words" parameter has been computed. Over valuation of certain types of sites could also be balanced if they were detected efficiently. These sites are characterized by linguistic patterns like clue phrases, for example. Some applications already achieve fairly good identification of e-commerce sites based on clue phrases. Identification of such sites could be used to lower crawling or archiving priority for certain types of sites, even though they are very well ranked. As can be seen, utilization of a site's "popularity" estimation based on in-going links has to be done in a certain way to prove efficiency. But it then appears to be very relevant, as our tests tend to show. Testing site importance estimationThe test described below was conducted at the BnF during the winter of 2002. Eight skilled librarians [14] participated to evaluate of a sample of ranked sites. ProtocolThe test sample was extracted from an 800-million-page crawl made by Xyleme <http://www.xyleme.com> in Fall 2001. The ranking computation is based on a Xyleme algorithm, but it is quite close to Google's ranking algorithm. (The main difference is that Xyleme is able to make this computation without storing the links matrix, which saves both storage capacity and time [15]). (For more details on this algorithm, see Abiteboul and Cobena [10]). The sample was restricted to the .fr domain with the site rankings based on their index page rankings. Site rankings were distributed on a 9-level scale, ranging from 10 to 100 with the higher levels usually considered as more significant. Xyleme provided 100 unique site URLs for each of the 9 levels. The tested levels were:
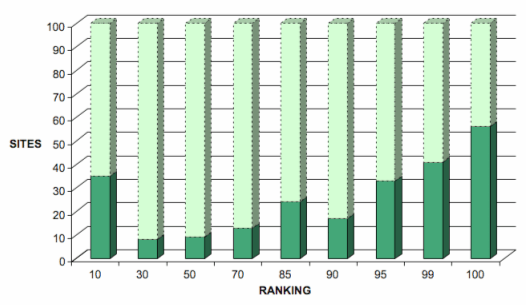
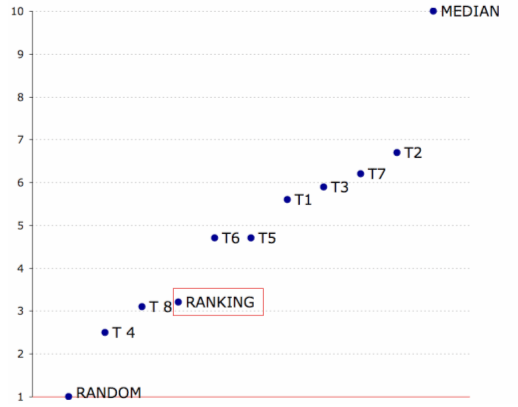
Manual removal of non-responding sites and pure e-commerce sites was conducted by one of the testers in order to save time for the other testers. 664 sites (mainly e-commerce) were removed. Figure 2 shows a distribution graph of the 236 remaining sites (dark green).
The librarians' evaluations of sites were based on their professional experience of the utilization of the traditional legal deposit collection by the BnF's readers. No other specific rules were defined. Site evaluation had to be made on a four-level scale by librarians. The scale used was:
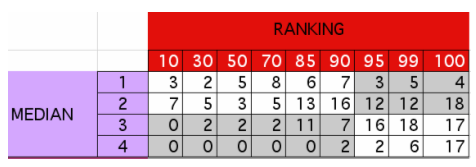
The test was a blind test, and each tester made his or her appraisal ignoring others' evaluations and site rankings, and the responses were fed through the intranet into a database. ResultsA median human evaluation was calculated for comparison with selection based on the linking parameter [16]. This median result was considered as the "ideal" evaluation. Note that ranking wasn't taken into account for evaluating this "ideal result". The following results matrix illustrated in Figure 3 specifies for a given level of linking parameter and of human evaluation regarding how many sites are concerned. The two white parts indicate where the two appraisals (human and ranking) correlate, the two grey ones where they differ.
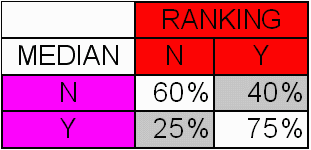
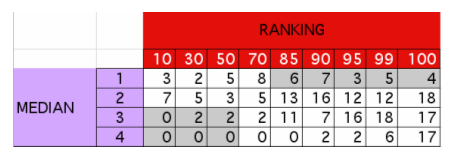
The tab shown in Figure 4 summarizes these results:
We can see that ranking enables an effective choice (the no-choice table would have contained 50 in each cell). When human evaluation (median) determines that a site should be included in the collection, the linking parameter is high in 75% of cases. This means that a choice based on the linking parameter would have been equivalent to human appraisal in 75% of cases. For excluding sites from the collection, results are lower. Human and linking parameter based choices correlate only in 60% of cases. These results show that ranking and human evaluation correlate quite well. This is obvious when we take a look at each human tester results compared to the median results. The same matrix has been calculated for each tester. To make a cross-comparison, an "accuracy factor" on a 10-level scale from 1 to 10 (the best correlation) has been calculated as follows: The sum of converging evaluations is divided by the total number of results. Figure 5 provides the results for each tester:
The results in Figure 6 above show that all valuations tend to converge (>1), and most importantly, the valuation based on linking parameter is not the one that most diverges from the median (though it has not been included for its computation). This means the ranking is a good candidate to help focus the crawl. To go into more detail, let's look at sites for which valuations diverge most between human tester and ranking.
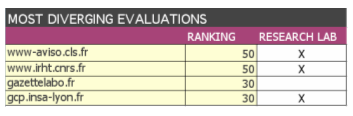
See Figure 7. First consider sites for which librarians' appraisals were highest (level 4). None has a linking parameter under 90. This is pretty comforting, for it means a selection based on this parameter would not miss very important sites. If we look at sites on level 3 of human valuation (see Figure 8), 4 had a linking parameter under 70, all belonging to a specific type: they are all research lab sites (gazettelabo.fr is a research material vendor gazette).
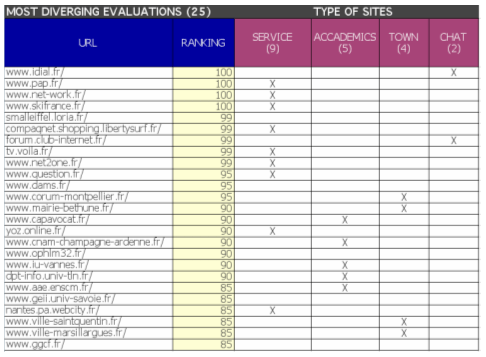
Librarians have selected these sites because they provide research papers or other documentation of interest. But they are much too specialized to get high ranking. If we take a look at sites "selected" according to the linking parameter but not to librarians, we also see types of sites emerging. See Figure 9
Most of the sites (9 of 25) are services sites providing weather forecasts or other types of "everyday life" information. Two are chat sites. One may be surprised to find 5 academic sites with good linking parameter that were nevertheless set out by librarians. For these sites, testers have estimated that no real material was provided except information on course schedules or a similar kind of general information. Librarians have selected other academic sites when they provided real content, research publications, for instance. This kind of refinement seemingly surpasses linking parameter possibility. The same thing applies with town council sites about which librarians discriminated based on content evaluation. The fact that most of the misleading evaluations occurred with regard to specific site types (service, chat, research lab) leads us to think that we will have the ability to correct this situation with site structure analysis and linguistic content evaluation. Chat sites and service sites, like e-commerce sites, have specific features that can be analyzed (clues phrases, for instance). More tests need to be done in the future with a crawler able to extract such information. For the rest, these results show that linking-based parameter is a good candidate to be used for focusing the crawl. 4. ConclusionAnalyzing and evaluating Web page or site relevance is a priority for building heritage Web collections on a large scale. We can't manually select large collections of sites, but neither can we be satisfied with blind crawls for selecting content for heritage collections. Commercial search engines have long been improving functional capacity of their crawlers for information retrieval purposes. It is now time for national libraries to adapt these techniques for heritage Web collection building. The "popularity parameter" is a good candidate to help us in this regard. It can be automatically calculated, and our results show that it correlates with librarian evaluations of site relevance. This correlation can be even better if sites are categorized by "genre" or type. The techniques described in this article could effectively help national libraries build large-scale, focused Web collections and, by allowing a better allocation of resources, achieve continuous archiving for sites that deserve it. We now need to develop tools using this technology and test them on a large corpus. 5. Notes and References[1] Cathro, W., Webb, C. & Whiting, J. (2001). "Archiving the Web: the PANDORA archive at the National Library of Australia." Preserving the Present for the Future Web Archiving Conference, Copenhagen, 18-19 June 2001. Available at: <http://www.nla.gov.au/nla/staffpaper/2001/cathro3.html>. [2] Electronic Collections Coordinating Group, National Library Of Canada, (1998). "Networked Electronic Publications Policy and Guidelines". Available at: <http://www.nlc-bnc.ca/9/8/index-e.html>. [3] Arvidson, A., Persson, K. & Mannerheim, J. (2000). "The Kulturarw3 Project—the Royal Swedish Web Archiw3e: an example of 'complete' collection of web pages." 66th IFLA Council and General Conference, Jerusalem, Israel, 13-18 August 2000. Available at: <http://www.ifla.org/IV/ifla66/papers/154-157e.htm>. [4] Kahle, B. (2002). "Editors' Interview: The Internet Archive." RLG DigiNews, 6 (3), 15 June 2002. Available at: <http://www.rlg.org/preserv/diginews/diginews6-3.html#interview>. [5] See for example political sites archiving in The Netherlands, Available at: <http://www.archipol.nl/>. Or the Digital Archive for Chinese Studies (DACHS), Available at: <http://www.sino.uni-heidelberg.de/dachs/>. We are trying to make an inventory of on-going web archiving project, so you are welcome to send information about the ones of which you are aware. [6] Hakala, J. (2001). "Collecting and Preserving the Web: Developing and Testing the NEDLIB Harvester." RLG DigiNews, 5 (2), 15 April 2001. Available at: <http://www.rlg.org/preserv/diginews/diginews5-2.html#feature2>. [7] The main discussion list on this topic is web-archive@cru.fr. Information available at: <http://listes.cru.fr/wws/info/web-archive>. [8] cf. 2nd ECDL Workshop on Web Archiving, Rome, Italy, 19 September 2002. Available at: <http://bibnum.bnf.fr/ecdl/2002/>. [9] Masanès, J. (2002). "Archiving the deep Web" 2nd ECDL Workshop on Web Archiving, Rome, Italy, 19 September 2002. Available at: <http://bibnum.bnf.fr/ecdl/2002/>. [10] Abiteboul, S., Cobéna, G., Masanès, J. & Sedrati, G. (2002). "A first experience in archiving the French Web." In: Research and advanced technology for digital libraries: 6th European conference, ECDL 2002, Agosti, M. & Thanos, C., eds., Rome, Italy, September 16-18, 2002. Lecture Notes in Computer Science, 2458. Berlin: Springer, 1-15. Also available at: <ftp://ftp.inria.fr/INRIA/Projects/verso/gemo/GemoReport-229.pdf>. [11] To give an illustration of possible gains, here are figures extracted from our 'Elections 2002' collection. This collection encompasses 2.200 sites or part of sites related to the presidential and parliamentary elections held in France in 2002. On a sample on these sites, 43 of the most captured ones, we have for April 2.103.360 files for 6 captures which represent 108 GB of data. Among these files only 45,7% are unique files, which represent 56.3% of the total amount of data. This means that more than a half of the crawling capacity and 43.7 of the storage capacity is 'wasted' in this case. It is really beneficial to have crawler able to manage sites changes in this kind of 'continuous' crawl. The small crawler we have used, HTTRACK (see <http://www.httrack.com>), is able to do incremental crawl and with a few scripts and a database, it can be used to handle automatic crawl of hundreds of sites. [12] Masanès, J. (2001). "The BnF's project for Web archiving." What's next for digital deposit libraries? ECDL Workshop, Darmstadt, Germany, 8 September 2001. Available at: <http://bibnum.bnf.fr/ecdl/2001//france/slg001.htm>. [13] Brin, S. & Page, L. (1998). "The Anatomy of a Large-scale Hypertextual Web Search Engine." Computer Networks and ISDN Systems, 30 (1-7), 107-117. Full version published in the proceedings of the 7th International World Wide Web Conference, Brisbane, Australia, 14-18 April 1998. Available at: <http://www7.scu.edu.au/programme/fullpapers/1921/com1921.htm>. [14] Véronique Berton, Virginie Breton, Dominique Chrishmann, Christine Genin, Loïc Le Bail, Soraya Salah, Jean-Yves Sarazin and Julian Masanès. [15] Abiteboul, S., Preda, M. & Cobéna, G. (2002). "Computing Web page importance without storing the graph of the Web (extended abstract)." Bulletin of the IEEE Computer Society Technical Committee on Data Engineering, 25 (1), 27-33. Available at: [16] Thanks to Gregory Cobéna from INRIA for his help on this part. Copyright © Julien Masanes |
||||||||||
| |
||||||||||
|
Top | Contents | ||||||||||
| | ||||||||||
|
D-Lib Magazine Access Terms and Conditions DOI: 10.1045/december2002-masanes
|