|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2015
Volume 21, Number 1/2
Data without Peer: Examples of Data Peer Review in the Earth Sciences
Sarah Callaghan
British Atmospheric Data Centre, UK
sarah.callaghan@stfc.ac.uk
DOI: 10.1045/january2015-callaghan
Abstract
Peer review of data is an important process if data is to take its place as a first class research output. Much has been written about the theoretical aspects of peer review, but not as much about the actual process of doing it. This paper takes an experimental view, and selects seven datasets, all from the Earth Sciences and with DOIs from DataCite, and attempts to review them, with varying levels of success. Key issues identified from these case studies include the necessity of human readable metadata, accessibility of datasets, and permanence of links to and accessibility of metadata stored in other locations.
1 Introduction
Much has been written and said about peer review in recent years (Bohannon, 2013; Bornmann, 2011; Lee, Sugimoto, Zhang, & Cronin, 2013; Weller, 2001), in particular focussing on its problems, and the choke points in the whole academic publishing system. Peer review of journal articles by external reviewers is in fact only a relatively recent development — the journal Nature instituted formal peer review only in 19671.
It is unsurprising therefore that even though the community generally agrees that peer review should be applied to the other outputs of research, such as data and software, the prospect of actually implementing these processes is daunting. Data in particular are much more heterogeneous than publications, and require more tools in order to interpret them. The size of modern datasets means that it is no longer possible to publish them as part of the journal article describing them. Instead they must be permanently linked to the article, and in such a way that the reader of the article can also understand the data enough to be reassured that the data do indeed support the arguments made in the article.
One of the foundations of the scientific process is reproducibility — without it, conclusions are not valid, and the community can be sent down costly and wasteful side tracks. Yet, for reproducibility to be achieved, the data must be made open to scrutiny, and in such a way that a researcher with knowledge in the field of study will be able to understand and interpret the data, at the very least.
Researchers who produce data want recognition for their efforts, and quite rightly. Research funders also want to know what impact their funding has had on the community and wider society. Hence the drive to make data open also includes a drive to assess the quality of the data. This can be done in a number of ways.
For those communities where large datasets are the norm (e.g. the climate modelling and high energy physics communities), the data tend to be stored in custom built repositories, with standardised metadata and quality control checks performed as part of the repository ingestion process (Adelman et al., 2010; Stockhause, Höck, Toussaint, & Lautenschlager, 2012). For the majority of research groups, lacking discipline-specific repositories capable of performing quality checks, their only ways of getting their data assessed is to wait for others to use it, and hope that the new users provide feedback2, or to submit it to a data journal, where as part of the publication process it will go through peer review.
Data journals are a new type of academic publication where authors write a short article about, and permanently linking to, a dataset, which is stored in a trusted data repository. The reviewers then review the article, and the linked dataset as one unit, providing assurance to the user community that this data is useful, and can be reused by researchers other than the original data producers.
How this peer-review process should be done is a matter of debate, and in all likelihood, will be very discipline specific. Other articles deal with the generalities and theories of data peer review (Lawrence, Jones, Matthews, Pepler, & Callaghan, 2011; Mayernik, Callaghan, Leigh, Tedds, & Worley, 2014; M. A. Parsons & Fox, 2013; Mark A. Parsons, Duerr, & Minster, 2010), this article instead chooses to focus on worked examples of peer review of data, in particularly outlining the many pitfalls that can occur in the process!
2 Methodology
This paper is an expansion of the blog post at (Callaghan, 2013), where I performed peer-review on two datasets held in two different repositories. This paper uses the same methods as in the blog post, but broadens the sample space to include seven other datasets.
For all the datasets reviewed, the same set of questions were applied and answered. As my expertise is in the Earth Sciences, the questions are therefore somewhat biased to those that would need to be answered in that field. Many questions are common, however, and deal with fundamental issues regarding the accessibility of the data and understandability of the metadata.
The first four questions in the series can be viewed as editorial questions:
- Does the dataset have a permanent identifier?
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Is it in an accredited/trusted repository?
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
In other words, these are questions that should be answered in the affirmative by an editorial assistant at the data journal before the paper and dataset even get sent out for review. If the dataset fails any of these, then it will not be possible for the reviewer to get any further in the review process, and asking them to try will be wasting their time and good will.
I apologise for the repetition involved in answering the same questions for each of the seven datasets, but hope that it will make the reader's understanding of the thought processes behind the review more clear.
2.1 Finding the datasets
In the blog post, I deliberately went to two data repositories that I had personal experience with, and searched within their catalogues for a particular search term "precipitation". For this experiment, I widened the net. Firstly I attempted to use Google to search for suitable datasets, with no success — many results were obtained, but trying to filter them to find the links to actual datasets was very difficult.
So instead I went to the DataCite metadata store and searched the catalogue of datasets there, using the search terms "rain" and "precipitation". The results still required a certain amount of filtering, as DataCite DOIs can be applied to publications and other research outputs, as well as datasets. The seven datasets chosen are not intended to be a representative sample of the datasets in DataCite, but are more illustrative of the type of issues I came across.
As all the datasets were chosen from DataCite, they all have a DOI, hence I decided to omit the first editorial question from each of the review examples, as the answer is the same in all cases:
- Does the dataset have a permanent identifier?
- Yes, a DOI.
2.2 Caveats and biases
As mentioned earlier, my background is in atmospheric science, particularly the space time variability of rain fields and the atmospheric impacts on radio communications systems (Callaghan, 2004). Hence the choice of my search terms, as I wished to find datasets to review that I had sufficient domain knowledge to do so.
As I work for a discipline-specific repository (the British Atmospheric Data Centre), one of NERC's federation of environmental data centres, I also excluded datasets from any of the NERC data centres due to potential conflicts of interest.
The results given in this paper are not intended to be exhaustive, or statistically meaningful. I made deliberate choices of datasets to review, based on what I thought would provide interesting and illuminating examples. A far less biased sample would have been to randomly choose a number of datasets from the list of returned search results, however, I hope my (biased) selection process is more illuminating.
It's also worth pointing out that even though the researchers who created these datasets have made them available, they probably didn't expect them to be reviewed in this fashion.
3 Datasets
Dataset 1: Hubbard Brook Rain Gages
Citation: Campbell, John; (2004): Hubbard Brook Rain Gages; USDA Forest Service. http://doi.org/10.6073/AA/KNB-LTER-HBR.100.2
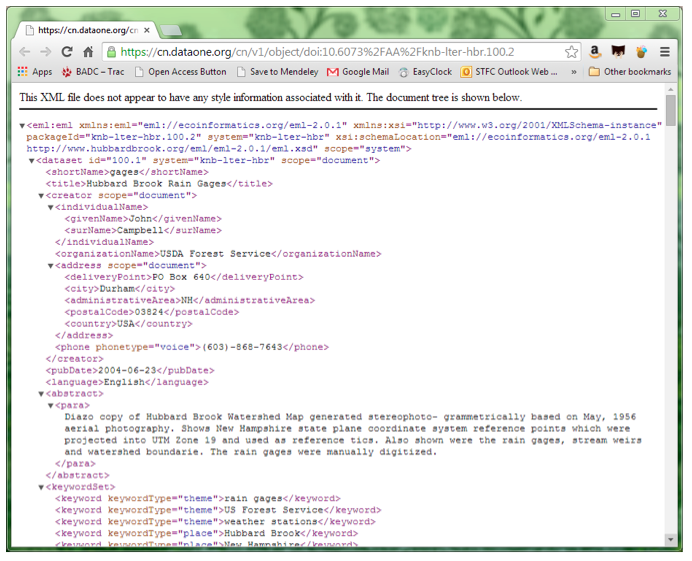
Figure 1: Landing page for (Campbell, 2004)
This dataset nearly fell at the very first hurdle, in that the landing page for the DOI is an xml file without any style information associated with it, which makes the whole thing really difficult to read, and hence review. (If I was reviewing this for real, I would have rejected it as soon as I saw the raw xml, but for the purposes of this paper, I have tried to answer the review questions.)
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Yes, but it's in raw xml, which makes it really hard to read.
- Is it in an accredited/trusted repository?
- DataONE is hosting the DOI landing page, but it appears that the data is being held by the Hubbard Brook Ecosystem Study, part of the USDA Forest Service. I'm not personally familiar with them.
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
- It's hard to tell from the raw xml, but there are large chunks of text dealing with Acceptable Use, Redistribution and Citation. Finding the link to the data is difficult — there are 13 http links in the document. Several are to pages in esri.com (which get a "not found" error). The link in the "download" section takes you to an executable file, which, given I don't know the data repository, I would prefer not to click on, just in case.
And it's at this stage that I give up on this particular dataset.
Verdict: Revise and Resubmit. This case study is a really good example of how important it is to have the landing pages for your DOIs presented in a way that is good for humans to read, not just machines. If the landing page was more user-friendly, then I'd probably have got further with the review.
Dataset 2: Daily Rainfall Data (FIFE)
Citation: Huemmrich, K. F.; Briggs, J. M.; (1994): Daily Rainfall Data (FIFE); ORNL Distributed Active Archive Center. http://doi.org/10.3334/ORNLDAAC/29
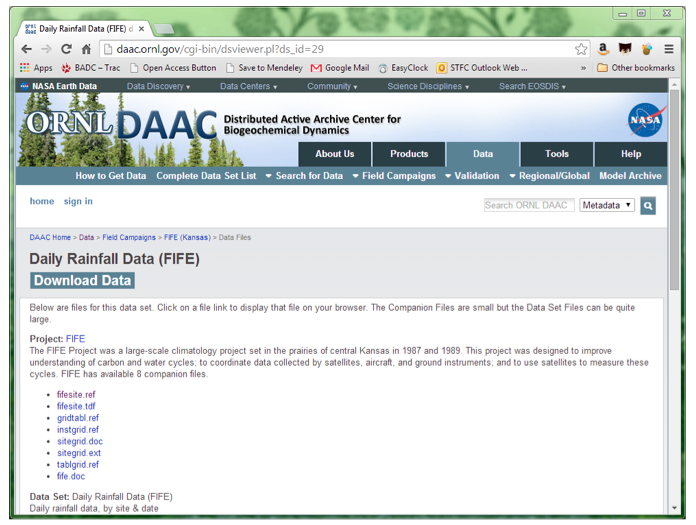
Figure 2: Landing page for (Huemmrich and Briggs, 1994)
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Yes.
- Is it in an accredited/trusted repository?
- I know ORNL DAAC, the federation, but haven't worked with the Biogeochemical Dynamics group before now.
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
- There is a nice, large and friendly "Download Data" button, right at the top. However, when I click on it I get told I need to sign in to download the data. Confusingly, there are also a list of files underneath that button, with the caption "Below are files for this dataset". Further down the page is "Download Data Set Files: (1.0 MBytes in 89 Files)" (with no hyperlink to click on), which seems to suggest that the files on the page aren't the data.
It looks like the registration process is easy, and I couldn't find any information there about restrictions to users, but given I'm on Dataset 2, and haven't managed to properly review anything yet, I decided to move on and find another, more open, dataset.
Verdict: Don't know. This case does show, however, that even minor access control restrictions can put users off accessing and reusing this data for other purposes.
Dataset 3: ARM: Total Precipitation Sensor
Citation: Cherry, Jessica; (2006): ARM: Total Precipitation Sensor; http://dx.doi.org/10.5439/1025305.
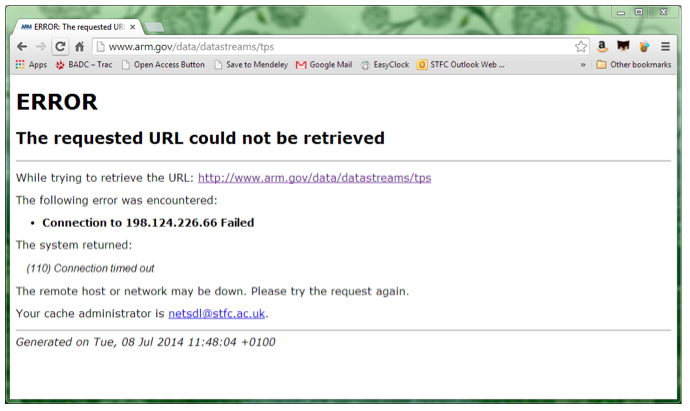
Figure 3: Error page received when attempting to resolve the DOI for Cherry, Jessica; (2006): ARM: Total Precipitation Sensor; http://doi.org/10.5439/1025305
On my first attempt to review this dataset, the DOI resolved to the dataset landing page for long enough so that I could take a first glance and identify it as a candidate for review. However, when I came back to the page after an hour or so, the page wouldn't reload, and the DOI failed to resolve repeatedly. This happened when I tried again four days later.
Verdict: Reject. If the DOI doesn't resolve, don't even bother sending it for review.
Dataset 4: Rain
Citation: Lindenmayer, David B.; Wood, Jeff; McBurney, Lachlan; Michael, Damian; Crane, Mason; MacGregor, Christopher; Montague-Drake, Rebecca; Gibbons, Philip; Banks, Sam C.; (2011): rain; Dryad Digital Repository. http://doi.org/10.5061/DRYAD.QP1F6H0S/3
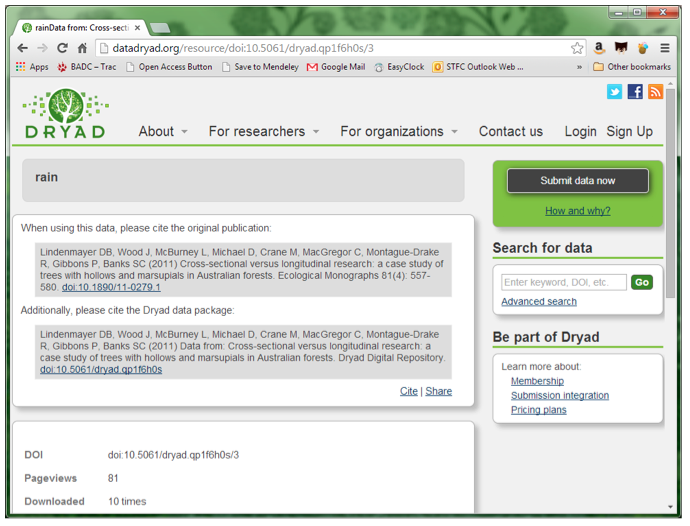
Figure 4: Landing page for (David B. Lindenmayer et al., n.d.-b)
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Yes, although the title is still just "rain" (which is a particularly unhelpful title for a dataset).
- Is it in an accredited/trusted repository?
- Yes, the data is stored in Dryad.
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
- Yes, both the data file rain.csv and the readme.txt file are both clearly found on the page and are easily downloadable.
- Are the access terms and conditions appropriate?
- At the bottom of the page is the text "To the extent possible under law, the authors have waived all copyright and related or neighboring rights to this data." There are also CC-zero and Open Data logos next to that text.
- Is the format of the data acceptable?
- Yes, csv is very open and portable.
- Does the format conform to community standards?
- Yes.
- Can I open the files and view the data? (If not, reject straight away)
- Yes.
- Is there information about any proprietary software required to open the data including version number?
- Not applicable.
- Is the metadata appropriate? Does it accurately describe the data?
- The metadata is in the readme.txt file and is a simple sentence: "rain.csv contains rainfall in mm for each month at Marysville, Victoria from January 1995 to February 2009". This is not enough metadata.
- Are there unexplained/non-standard acronyms in the dataset title/metadata?
- The dataset title is just "rain", which is not very helpful at all to any potential users. On the landing page, it does show clearly that this particular dataset is, in fact, part of another larger data package: (David B. Lindenmayer et al., n.d.-a)
- Is the data calibrated? If so, is the calibration supplied?
- Don't know, and no calibration is supplied.
- Is the data flagged? Is there an appropriate description of the flagging parameters?
- There are null flags in the csv file, but no explanation of them.
- Is information/metadata given about how/why the dataset was collected? (This may be found in publications associated with the dataset)
- Not in the readme file, or on the landing page itself. I'm assuming this information is in the paper associated with this data package: (D. B. Lindenmayer et al., 2011) Unfortunately I can't check, as the paper is behind a paywall.
- Are the variable names clear and unambiguous, and defined (with their units)?
- Not in the csv file itself, but there is a little bit of information in the readme.txt file.
- Is there enough information provided so that data can be reused by another researcher?
- Yes, but only because it's such a simple measurement. Though providing the latitude and longitude of the site would have made it far more useful.
- Is the data of value to the scientific community?
- Yes, but only because it's observational data and therefore can't be repeated.
- Does the data have obvious mistakes?
- No.
- Does the data stay within expected ranges?
- Yes (no minus values for rainfall).
- If the dataset contains multiple data variables, is it clear how they relate to each other?
- Not applicable.
Verdict: Revise and resubmit. This is a small part of a research project that wasn't really looking at rain at all — yet what data they have collected could potentially be amalgamated with other datasets to provide a wider-ranging, more useful dataset. The title definitely needs fixing, and extra metadata about the calibration, type of gauge, latitude and longitude, need to be supplied. (This information may be in the associated paper, but seeing as it's behind a paywall, it's not much use to a user at this time).
It's also interesting to see that you can import the data citation into Mendeley from Dryad (by clicking the "Save to Mendeley" plugin button I have in Google Chrome). Unfortunately the dates of the data citations get a bit messed up by this.
Dataset 5: Meteorological Records from the Vernagtferner Basin — Gletschermitte Station, for the Year 1987
Citation: Weber, Markus; Escher-Vetter, Heidi; (2014a): Meteorological records from the Vernagtferner basin — Gletschermitte Station, for the year 1987; PANGAEA — Data Publisher for Earth & Environmental Science. http://doi.org/10.1594/PANGAEA.832561
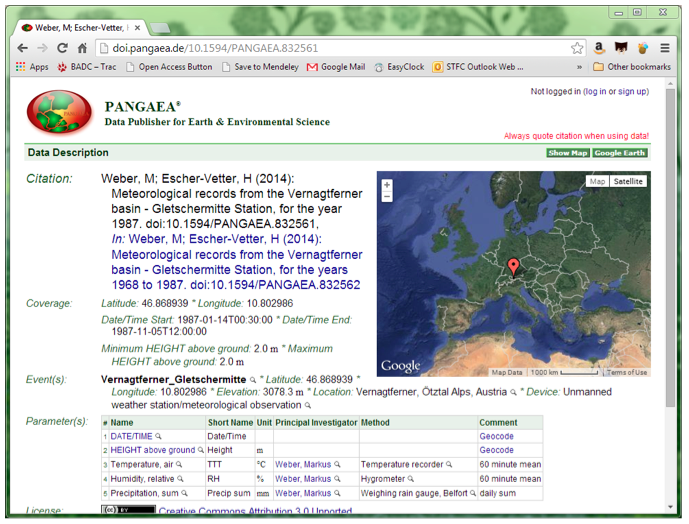
Figure 5: Landing Page for (Weber & Escher-Vetter, 2014a)
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Yes.
- Is it in an accredited/trusted repository?
- Yes.
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
- Yes.
- Are the access terms and conditions appropriate?
- Yes, Creative Commons Attribution 3.0 Unported.
- Is the format of the data acceptable?
- Yes, Data is provided as tab delimited text in a choice of standards.
- Does the format conform to community standards?
- Yes.
- Can I open the files and view the data? (If not, reject straight away)
- Yes.
- Is there information about any proprietary software required to open the data including version number?
- Opens in a text editor, so not applicable.
- Is the metadata appropriate? Does it accurately describe the data?
- Yes, though there are gaps in the series that you'll only see by looking at the data — it would have been good to have these gaps identified in the metadata.
- Are there unexplained/non-standard acronyms in the dataset title/metadata?
- No.
- Is the data calibrated? If so, is the calibration supplied?
- No information about calibration supplied. The rain gauge is given as "Weighing rain gauge, Belfort", but it would have been helpful to give a make and model, as a Google search results in several different instruments of that type.
- Is the data flagged? Is there an appropriate description of the flagging parameters?
- The data isn't flagged, which caused me a bit of confusion when opening the csv file in a text editor as it looked like there were no relative humidity or precipitation sum values — but they are there if the user scrolls down far enough. Having the html view of the first 2000 lines is helpful in this respect, as it makes it easy for the user to scroll quickly through the data.
- Is information/metadata given about how/why the dataset was collected? (This may be found in publications associated with the dataset)
- Yes. This dataset is a year's worth of data from a larger dataset spanning multiple years, all at the same location: (Weber & Escher-Vetter, 2014b). This dataset collection also provides a link to a grey literature document entitled: "Technical comments on the data records from the Gletschermitte station, Vernagtferner, Oetztal Alps, for the period 1968 to 1987".
- Are the variable names clear and unambiguous, and defined (with their units)?
- Yes.
- Is there enough information provided so that data can be reused by another researcher?
- Yes.
- Is the data of value to the scientific community?
- Definitely. Historical meteorological records of this quality are important to the atmospheric and climate modelling communities.
- Does the data have obvious mistakes?
- Not that I can see with a scan over.
- Does the data stay within expected ranges?
- As far as I can see with a quick scan, yes.
- If the dataset contains multiple data variables, is it clear how they relate to each other?
- Yes.
Verdict: Accept. Of all the datasets reviewed in the process of writing this paper, this was the best documented, and therefore the most useful.
Dataset 6: National Oceanic and Atmospheric Administration. Weather Measurements: Monthly Surface Data: Total Precipitation | Country: USA | State: South Carolina — [Data-file]
Citation: Data-Planet by Conquest Systems, Inc. (2014). National Oceanic and Atmospheric Administration. Weather Measurements: Monthly Surface Data: Total Precipitation | Country: USA | State: South Carolina — [Data-file], Retrieved from http://www.data-planet.com, Viewed: July 8, 2014. Dataset-ID: 018-002-006. http://doi.org/10.6068/DP143A169EBCB2
Or (DataCite citation)
Conquest System Datasheet; (2013): Average Daily Precipitation from the Weather Measurements: Monthly Surface Data Dataset shown in Inches; Conquest Systems, Inc.. http://doi.org/10.6068/DP13F0712607393
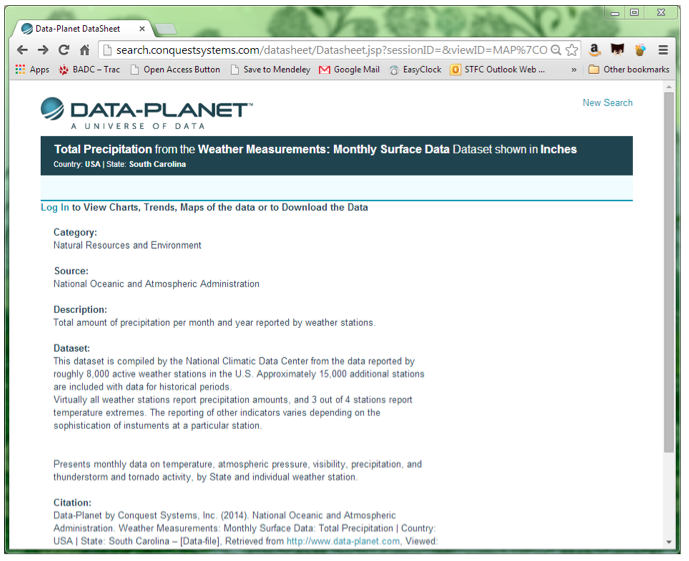
Figure 6: Landing page for (Data-Planet by Conquest Systems, Inc. 2014).
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Yes, although when I was doing the search to find candidate datasets for review in DataCite, I discovered that for this particular data centre there were three pages of results, all with the same title (Figure 7). It's only when you go to the landing page that you discover they're all for different US states.
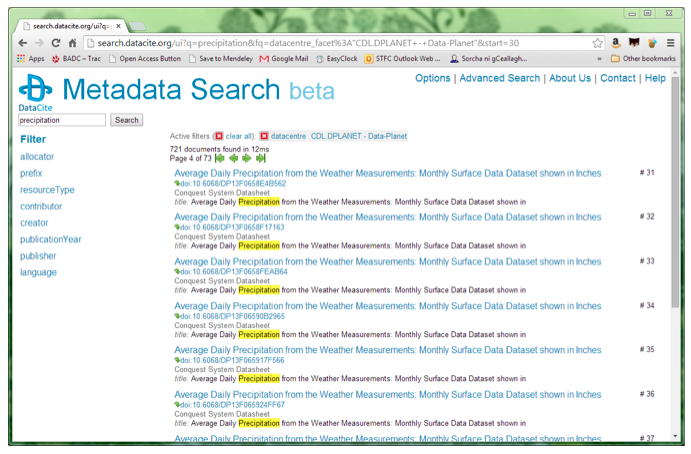
Figure 7: Screenshot from the DataCite search pages, showing the list of identically-titled datasets in this repository.
- Is it in an accredited/trusted repository?
- This is my first experience with them, so reserving judgement.
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
- No and no. The text at the top of the page says "Log In to View Charts, Trends, Maps of the data or to Download the Data". Clicking on the login link takes you to a login page where you can login if you have an existing account. There's no information on that page about how to register a new account, or even a link to a help page. Going to the top level page of the site gives you a link for FAQs, where, at the bottom of the page you can learn that it's a subscriber only platform, where the cost "varies according to type of institution and size of user population".
Verdict: Reject. Don't even send out for review. On a more positive note, I like the way they've very clearly spelled out how the dataset should be cited. And, to be fair, I would expect that if the dataset authors had sent their dataset for review, then they would have arranged access. Though it's interesting to note that in the citation, Data-Planet is given as the dataset creators, when I'd expect them to be the publishers. Oh, and the citation Data-Planet give isn't the same as the DataCite citation, which will cause confusion.
Dataset 7: ECHAM5-HAM Precipitation and Aerosol Optical Depth Data
Citation: Benjamin S. Grandey; (2014): ECHAM5-HAM precipitation and aerosol optical depth data; Figshare. http://doi.org/10.6084/M9.FIGSHARE.1061414
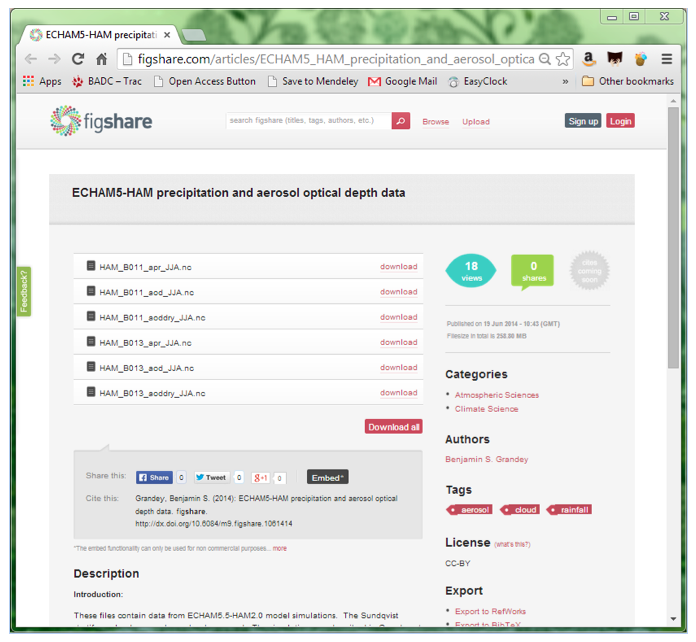
Figure 8: Landing Page for for (Benjamin S. Grandey, 2014)
- Does it have a landing page (or README file or similar) with additional information/metadata, which allows you to determine that this is indeed the dataset you're looking for?
- Yes.
- Is it in an accredited/trusted repository?
- Yes.
- Is the dataset accessible? If not, are the terms and conditions for access clearly defined?
- Yes, the dataset is readily downloadable, under a CC-BY licence.
- Are the access terms and conditions appropriate?
- Yes.
- Is the format of the data acceptable?
- The files provided are *.nc files, which given the subject area I'd assume are netcdf files. However, this isn't explicitly stated in the dataset metadata. The files open using standard netcdf software (ncdump.exe) and hence can be determined to be netcdf.
- Does the format conform to community standards?
- As they're netcdf then yes.
- Can I open the files and view the data? (If not, reject straight away)
- Yes, using standard netcdf tools. These are big files — the precipitation file is 77.6 MB, so having a warning about the file size would have been a nice idea.
- Is there information about any proprietary software required to open the data including version number?
- No.
- Is the metadata appropriate? Does it accurately describe the data?
- The metadata on the dataset landing page only gives a short outline of what the data is, and the naming conventions of the files. There metadata in the headers of the files, standard procedure for netcdf, which gives variable names, units etc.
- Are there unexplained/non-standard acronyms in the dataset title/metadata?
- Yes, but ECHAM5.5-HAM2.0 is the model name. Citations on the dataset page to the model used and the Sundqvist stratiform cloud cover scheme would have been helpful.
- Is the data calibrated? If so, is the calibration supplied?
- This dataset consists of model run data. Some information on how it was created is in the header of the netcdf file, but not on the dataset landing page.
- Is the data flagged? Is there an appropriate description of the flagging parameters?
- No.
- Is information/metadata given about how/why the dataset was collected? (This may be found in publications associated with the dataset)
- Yes, but only in the related paper (B. S. Grandey, Stier, & Wagner, 2013), which is open access.
- Are the variable names clear and unambiguous, and defined (with their units)?
- Yes, all as part of the netcdf header.
- Is there enough information provided so that data can be reused by another researcher?
- Yes, though that is primarily due to the in-file metadata in the netcdf files.
- Is the data of value to the scientific community?
- A qualified yes, as it's model data, and (in theory, if not in practice) model data can be rerun to reproduce it. Making it available allows users to check and verify the linked papers conclusions more easily.
- Does the data have obvious mistakes?
- I can't tell — the files are large. I can easily dump the headers into a text file, but doing the same for the data doesn't work.
- Does the data stay within expected ranges?
- Again, without an easy to use viewer, I wasn't able to check this.
- If the dataset contains multiple data variables, is it clear how they relate to each other?
- Yes.
Verdict: Accept. Reviewing this dataset got outside my comfort zone, as I'm not a climate modeller, and if I'd been asked to review this for real, I would have declined. In terms of usability and metadata, the metadata provided on the landing page isn't really good enough to help the reader judge. Having metadata inside the data files is all well and good, but does require software to open them. NetCDF is a common format, but wouldn't be accessible to researchers outside the Earth Science and climate fields. I'd recommend that the dataset authors update their description section with the full reference for the paper (marked as "in press, 2014") that analyses the data. I also really like how figshare have an "export to Mendeley" button set up on their dataset pages.
4 Conclusions
If data are to become recognised outputs of the research process (as they should) then they need to be available for other users to scrutinise, for the verification and reproducibility of the research. As the case studies presented here show, peer review of data can be done, though potentially has many problems. These problems aren't necessarily with the datasets, but with the way they are presented and made available (or not) to the user, making them primarily the repository's area of concern.
- Accessibility is a major issue — if a dataset isn't open to the reviewer, then it's not possible for it to be reviewed. Even minor blocks to accessibility, such as signing up for a free account to download data, could put reviewers off. Similarly, if important metadata for the dataset is locked in a paper behind a paywall, then that reduces the usability of the dataset significantly.
- Human-readable metadata is critical. Peer review is not going to be carried out by machines any time soon, so the dataset's metadata has to be open and easily readable by human reviewers. Hence it needs to be presented in an easy to read, user-friendly and understandable format.
- Linking from the dataset landing pages to other sources of metadata is helpful, but these links need to be maintained as well as the link to the data.
The true impact of a dataset, like the true impact of a research article, can really only be determined over a long period of time, by the number of researchers using and citing it. Yet, if a dataset is difficult to use and understand, it is very likely that its impact will be seriously reduced. Peer review of data, as presented in this paper, provides a way of checking the understandability and usability of the data, allowing other users to filter available datasets to those that will be of use to them, without a significant overhead in opening and interpreting the data and metadata.
Acknowledgements
The work required to write this paper has been funded by the European Commission as part of the project OpenAIREplus (FP7-2011-2, Grant Agreement no. 283595).
Notes
1 "History of the journal Nature". Timeline publisher Nature.com. 2013.
2 Quality control through user feedback is an interesting topic, but unfortunately out of scope for this paper. The CHARMe project is looking into this in greater detail and will be producing a software mechanism to support this.
References
[1] Callaghan, S.A, "Fractal analysis and synthesis of rain fields for radio communication systems" PhD thesis, University of Portsmouth, June 2004.
[2] Callaghan, S., 2013: How to review a dataset: a couple of case studies [blog post].
[3] Campbell, John; (2004): Hubbard Brook Rain Gages; USDA Forest Service. http://doi.org/10.6073/AA/KNB-LTER-HBR.100.2
[4] Data-Planet by Conquest Systems, Inc. (2014). National Oceanic and Atmospheric Administration. Weather Measurements: Monthly Surface Data: Total Precipitation | Country: USA | State: South Carolina — [Data-file], Retrieved from http://www.data-planet.com, Viewed: July 8, 2014. Dataset-ID: 018-002-006. http://doi.org/10.6068/DP143A169EBCB2
[5] Adelman, J., Baak, M., Boelaert, N., D'Onofrio, M., Frost, J. A., Guyot, C., ... Wilson, M. G. (2010). ATLAS offline data quality monitoring. Journal of Physics: Conference Series, 219(4), 042018. http://doi.org/10.1088/1742-6596/219/4/042018
[6] Bohannon, J. (2013). Who's afraid of peer review? Science, 342, 60—65. http://doi.org/10.1126/science.342.6154.60
[7] Bornmann, L. (2011) Scientific peer review. Annual Review of Infomration Science and Technology, 45, 197—245. http://doi.org/10.1002/aris.2011.1440450112
[8] Grandey, B. S. (2014). ECHAM5-HAM precipitation and aerosol optical depth data. http://doi.org/10.6084/m9.figshare.1061414
[9] Grandey, B. S., Stier, P., & Wagner, T. M. (2013). Investigating relationships between aerosol optical depth and cloud fraction using satellite, aerosol reanalysis and general circulation model data. Atmospheric Chemistry and Physics, 13(6), 3177—3184. http://doi.org/10.5194/acp-13-3177-2013
[10] Lawrence, B., Jones, C., Matthews, B., Pepler, S., & Callaghan, S. (2011). Citation and Peer Review of Data: Moving Towards Formal Data Publication. International Journal of Digital Curation, 6(2), 4—37. http://doi.org/10.2218/ijdc.v6i2.205
[11] Lee, C. J., Sugimoto, C. R., Zhang, G., & Cronin, B. (2013). Bias in peer review. Journal of the American Society for Information Science and Technology, 64(1), 2—17. http://doi.org/10.1002/asi.22784
[12] Lindenmayer, D. B., Wood, J., McBurney, L., Michael, D., Crane, M., MacGregor, C., ... Banks, S. C. (n.d.-a). Data from: Cross-sectional versus longitudinal research: a case study of trees with hollows and marsupials in Australian forests. http://doi.org/10.5061/dryad.qp1f6h0s
[13] Lindenmayer, D. B., Wood, J., McBurney, L., Michael, D., Crane, M., MacGregor, C., ... Banks, S. C. (n.d.-b). rain. http://10.5061/dryad.qp1f6h0s/3
[14] Lindenmayer, D. B., Wood, J., McBurney, L., Michael, D., Crane, M., MacGregor, C., ... Banks, S. C. (2011). Cross-sectional vs. longitudinal research: a case study of trees with hollows and marsupials in Australian forests.
[15] Mayernik, M. S., Callaghan, S., Leigh, R., Tedds, J., & Worley, S. (2014). Peer Review of Datasets: When, Why, and How. Bulletin of the American Meteorological Society, 140507132833005. http://10.1175/BAMS-D-13-00083.1
[16] Parsons, M. A., Duerr, R., & Minster, J. B. (2010). Data citation and peer review. Eos. http://doi.org/10.1029/2010EO340001
[17] Parsons, M. A., & Fox, P. A. (2013). Is Data Publication the Right Metaphor? Data Science Journal, 12, WDS32—WDS46. http://doi.org/10.2481/dsj.WDS-042
[18] Stockhause, M., Höck, H., Toussaint, F., & Lautenschlager, M. (2012). Quality assessment concept of the World Data Center for Climate and its application to CMIP5 data. Geoscientific Model Development, 5, 1023—1032. http://doi.org/10.5194/gmd-5-1023-2012
[19] Weber, M., & Escher-Vetter, H. (2014a, May 16). Meteorological records from the Vernagtferner basin — Gletschermitte Station, for the year 1987. PANGAEA. http://doi.org/10.1594/PANGAEA.832561
[20] Weber, M., & Escher-Vetter, H. (2014b, May 16). Meteorological records from the Vernagtferner basin — Gletschermitte Station, for the years 1968 to 1987. PANGAEA. http://doi.org/10.1594/PANGAEA.832562
[21] Weller, A. C. (2001). Editorial Peer Review: Its Strengths and Weaknesses (p. 342). Information Today, Inc.
[22] Huemmrich, K.F.; Briggs, J.M.; (1994): Daily Rainfall Data (FIFE); ORNL Distributed Active Archive Center. http://doi.org/10.3334/ORNLDAAC/29
[23] Cherry, Jessica; (2006): ARM: Total Precipitation Sensor. http://dx.doi.org/10.5439/1025305
About the Author
 |
Sarah Callaghan received her PhD for a programme of work investigating the space-time variability of rain fields and their impact on radio communications systems, from the University of Portsmouth in 2004. Dr Callaghan is now a senior researcher and project manager for the British Atmospheric Data Centre, specialising in data citation, data publication and digital curation. She is a co- chair of the CODATA-ICSTI Task Group on Data Citations, and co-chair for the Research Data Alliance's Working Group on Bibliometrics for data. She is also an associate editor for Wiley's Geoscience Data Journal, and Atmospheric Science Letters. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |