|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
November/December 2012
Volume 18, Number 11/12
CORE: Three Access Levels to Underpin Open Access
Petr Knoth and Zdenek Zdrahal
Knowledge Media institute, The Open University
{petr.knoth, zdenek.zdrahal}@open.ac.uk
10.1045/november2012-knoth
Abstract
The last 10 years have seen a massive increase in the amount of Open Access publications in journals and institutional repositories. The open availability of large volumes of state-of-the-art knowledge online has the potential to provide huge savings and benefits in many fields. However, in order to fully leverage this knowledge, it is necessary to develop systems that (a) make it easy for users to discover and access this knowledge at the level of individual resources, (b) explore and analyse this knowledge at the level of collections of resources and (c) provide infrastructure and access to raw data in order to lower the barriers to the research and development of systems and services on top of this knowledge. In this paper, we argue why these requirements should be satisfied and show that current systems do not meet them. Consequently, we present the CORE (COnnecting REpositories) system, a large-scale Open Access aggregation, outlining its existing functionality and discussing the future technical development. We demonstrate how the system addresses the above needs and how it can be applied to the benefit of the whole ecosystem that includes institutional repositories, individuals, researchers, developers, funding bodies and governments.
Keywords: Digital Libraries, Open Access, Technical Infrastructure, Applications of OA, Reuse of OA Content
1. Introduction
Over recent years, statistics have been showing a huge increase in the amount of Open Access (OA) research papers, indicating a cultural change happening across research disciplines. This cultural change has been supported at different levels by governments and funders, digital libraries, universities and research institutions and last but not least by researchers and the general public. The number of OA journals and institutional repositories is increasing year by year and the number of OA papers grows exponentially. The OA movement is certainly gaining momentum.
Apart from the growth of OA journals, providing so-called Gold OA, a cornerstone of the OA movement has been a process called self-archiving (Green OA). Self-archiving refers to the deposit of a preprint or postprint of a journal or conference article in an institutional repository or archive. According to the Directory of Open Access Repositories (OpenDOAR), more than 65% of publishers endorse self-archiving. They include major players, such as Springer Verlag. It is largely due to this policy that millions of research papers are available online without the necessity to pay a subscription. According the to the study of Laasko & Björk (2012), 17% of currently published research articles are available as gold OA. The recent study of Gargouri, et al. (2012) shows that about 20% of articles are made available as green OA. Countries with more and stronger (institutional or funder) green OA mandates have even higher proportions of articles available as green OA. For example, almost 40% of research outputs in the UK are believed to be available through the green route.
The presence of this freely accessible and quickly growing knowledge pool constitutes a great opportunity as well as a challenge. We believe that the availability of open data creates an environment in which technology innovation can accelerate. Open availability of data has been the defining feature of the Web which largely contributed to the success of search engines, wikis, social networks and many other online services. OA appears to be following in the same footsteps. If the current environment is supportive of Open Access, is there anything else that reduces its impact and makes it difficult for Open Access to become the default policy? There is still, of course, a number of reasons that hinder the adoption of Open Access (Björk, 2003) including often discussed legal barriers as well as the issues related to evidence of scientific recognition. In this paper, we discuss a very important yet a rarely debated one — the lack of a mature technical infrastructure.
The Budapest Open Access Initiative clearly identifies, in its original definition of Open Access from 2001, that OA is not only about making research outputs freely available for download and reading. The aspect of reuse, which includes being able to index and pass OA content to software, is firmly embedded in the definition, opening new possibilities for the development of innovative OA services. However, while the growth of OA content has been used in the last decade as a benchmark of success of the OA movement, the successes in terms of finding and reusing OA content are much less documented. We believe that in order to fully exploit the reuse potential of OA, it is vital to improve the current OA technical infrastructure and facilitate the creation of novel (possibly unforeseen) services utilising the OA content. According to Figure 1 below, this OA content consists of OA papers, OA research data and all possibly inferred (or extracted) knowledge from these materials. The services that can access and manipulate this content can be tailored to different audiences and serve different purposes.

Figure 1: Open Access content and services.
There are three essential types of access to this content, which we will call access levels. We argue that these access levels must be supported by services in order to create an environment in which OA content can be fully exploited. They are:
- Access at the granularity of papers.
- Analytical access at the granularity of collections.
- Access to raw data1.
In this paper, we introduce these access levels and demonstrate why their combination is vital. Later, we present the CORE (COnnecting REpositories) system, which we have been developing over the last 1.5 years. CORE delivers services at these access levels and provides the technical infrastructure to facilitate the creation of new services.
The rest of the paper is organised as follows. Section 2 reviews the related work. In Section 3, we analyse the functionalities an OA technical infrastructure should provide. We then introduce the layered model of an aggregation system and use it to highlight the functionality currently not provided by existing aggregation systems. Section 4, introduces the CORE system, which has already been deployed to aggregate millions of publications from hundreds of Open Access repositories, discusses the technical issues in delivering an infrastructure that supports the above mentioned access levels and shows how CORE addresses them. Finally, we outline the future work and provide a discussion of the implications.
2. Related Work
Recent years have seen a substantial investment in the development of (institutional or Open Access) repositories (OARs) supporting the deposit and preservation of Open Access content. While the existence of these repositories is crucial, they are, however, only one side of the coin. The Confederation of Open Access Repositories states: Each individual repository is of limited value for research: the real power of Open Access lies in the possibility of connecting and tying together repositories, which is why we need interoperability. In order to create a seamless layer of content through connected repositories from around the world, Open Access relies on interoperability, the ability for systems to communicate with each other and pass information back and forth in a usable format. Interoperability allows us to exploit today's computational power so that we can aggregate, data mine, create new tools and services, and generate new knowledge from repository content (Rodrigues and Clobridge, 2011). While we fully acknowledge the importance of interoperability, it is in fact the implementation of interoperability in the form of systems and services that will enable us to utilise the knowledge stored in the form of articles, books, theses, research data, etc., in OARs. The technical maturity of the infrastructure for connecting and tying together repositories is vital for the success of Open Access.
A number of projects/systems have addressed the issue of connecting OARs by developing metadata repository aggregators, such as BASE (Pieper and Summann, 2006), IRS (Lyte, et al., 2009) or OAISter (Loesch, 2010). The majority of repository aggregation systems focus on the essential problem of aggregating resources for the purposes of providing cross-repository metadata search. While search is an essential component of an OA infrastructure, connecting and tying OA repositories together offers far more possibilities. Aggregations should not become just large searchable metadata silos, they should offer (or enable others to offer) a wide range of value-added services targeting all different types of users participating in the research process, i.e. not just users searching for individual publications, but, for example, those who need statistical information about collections of publications and their dynamics or those who need access to raw data for the purposes of research or applications development. These characteristics should distinguish OA aggregation systems from major academic search engines, such as Google Scholar or Microsoft Academic Search.
So, what is it that Google Scholar, Microsoft Academic Search and the mentioned cross-repository search systems are missing? What makes them insufficient for becoming the backbone of OA technical infrastructure? To answer this question, one should consider the services they provide on top of the aggregated content at the three access levels, identified in the Introduction, and think about how these services can contribute to the implementation of the infrastructure for connected repositories. Table 1 below shows the support provided by academic search engines at these access levels. As we can see, these systems provide only very limited support for those wanting to build new tools on top of them, for those who need flexible access to the indexed content and consequently also for those who need to use the content for analytical purposes. In addition, they do not distinguish between Open Access and subscription based content, which makes them unsuitable for realising the above mentioned vision of connected OARs.
| Access Level | Google Scholar | MS Academic Search |
| Access at the granularity of papers | The Google Scholar search interface | The MS Academic Search interface |
| Analytical access at the granularity of collections | No specific services other than citation analysis on a per researcher basis | Various visualisation services, such as Academic Map, Domain Trend, Organization Comparison, etc. Accessible from the browser, but most analytical data currently unavailable through the API. |
| Access to raw data | No API is provided, scraping solutions exist, but are likely to violate Google policies | Non-commercial use only, max 200 queries per minute, one API call returns max 100 items. Should not be used to crawl the entire corpus. |
Table 1. Functionalities provided by major commercial academic search engines at the three access levels.
The idea of going "beyond search and access" while not ignoring these functions has already been explored in Lagoze, et al. (2005). The authors argue that digital libraries need to add value to web resources by extending current metadata models to allow establishing and representing context of resources, enriching them with new information and relationships, and encourage collaborative use. While the value of such services is apparent, and their realisation is often entirely plausible, there is a high barrier to entering the market. This barrier is the difficulty of being able to access and work with the raw data needed to realise these services.
As highlighted by the experience of the OAIster team, the realisation of traditional solutions to aggregation systems tends to be expensive and the resulting production systems are hard to sustain in the long term (Manghi, et al., 2010b). Therefore, aggregation systems must (a) become significantly cheaper to develop and run or (b) there should be an open infrastructure that allows others to build on top of the aggregated content.
Option (a) has been recently addressed by a team developing the D-NET architecture (Manghi, et al., 2010a). The D-NET software is realised as a service-oriented architecture providing services ranging from metadata harvesting and harmonisation to the way resources are presented. However, even with reusable software packages, significantly reducing the cost of aggregation is not a trivial task given the growing amount of content available online and the need to store aggregated data. Therefore, Option (b) focuses on offering an open, yet ready-to-use solution in the form of an open online service. This principle is embraced by the CORE system presented in this paper.
One of the important aspects which D-NET shares with CORE is the aggregation of both content and metadata as opposed to the previously mentioned metadata only aggregations. CORE already makes substantial use of the full-text content for various purposes including citation extraction and resolution, content similarity, deduplication, content classification and others. This allows us to build services that clearly add value to the content provided by individual repositories. The D-NET framework is, in this sense, going in the same direction as CORE, promising to implement such services by the end of 20132.
3. The Users and Layers of Aggregations
According to the level of abstraction at which a user communicates with an aggregation system, it is possible to identify the following types of access:
- Raw data access
- Transaction access
- Analytical access
With these access types in mind, we can think of the different kinds of users of aggregation systems and map them according to their major access type. Table 2 lists the kinds of users which we have identified as the main players in the OA ecosystem and explains how aggregations can serve them. Naturally, each user group will expect to communicate with an aggregation system in a specific way that will be most practical for satisfying their information needs. While developers are interested in accessing the raw data, for example through an API, academics will primarily require accessing the content at the level of individual items or relatively small sets of items, mostly expecting to communicate with a digital library (DL) using a set of search and exploration tools. A relatively specific group of users are eResearchers3 whose work is largely motivated by information communicated at the transaction and analytical levels, but in terms of their actual work are mostly dependent on raw data access typically realised using APIs and downloadable datasets.
| Types of information access | What it provides | Users group |
| Raw data access | Access to the raw metadata and content as downloadable files or through an API. The content and metadata might be cleaned, harmonised, preprocessed and enriched. | Developers, digital libraries, eResearchers, companies developing SW, ... |
| Transaction information access | Access to information primarily with the goal to find and explore content of interest typically realised through the use of a web portal and its search and exploratory tools. | Researchers, students, life-long learners, general public, ... |
| Analytical information access | Access to statistical information at the collection or sub-collection level often realised through the use of tables or charts. | Funders, government, business intelligence, repository/digital library managers ... |
Table 2: Types of information communicated to users at the expected level of granularity — access levels.
Figure 2 depicts the inputs and outputs of an aggregation system showing the three access levels. The internals of the aggregation system are described in the next section. Based on the access level requirements for the individual user groups, we can specify services needed for their support. In Section 2, we have discussed that existing OA aggregation systems focus on providing access at one or more of these levels. While together they cover all the three access levels, none of them individually supports all access levels. The central question is whether it is sufficient to build an OA infrastructure as a set of complementary services. Each of these services would support a specific access level and together they would support all of them. An alternative solution would be a single system providing support for all access levels.

Figure 2. The inputs and outputs of an aggregation system.
One can argue that out of the three access levels, the most essential one is the raw data access level, as all the other levels can be developed on top of this one. This suggests that the overall OA infrastructure can be composed of many systems and services. So, why does the current infrastructure provide insufficient support for these access levels?
All the needed functionality can be built on top of the first access level, but the current support for this level is very limited. In fact, there is currently no aggregation of all OA materials that would provide harmonised, unrestricted, transparent and convenient access to OA metadata and content. Instead, we have many aggregations, each of which is supporting a specific access level or a user group, but most of which are essentially relying on different data sets. The critical problem of different data sets is the difficulty of comparing and evaluating the services built on top of this data. As a result, it is not possible for analysts to make firm conclusions about the properties of OA data, it is not possible to reliably inform individuals about what is in the data, and it is very difficult for eResearchers and developers to improve technology for the upper access levels when their level of access to OA content is limited.
To exploit the reuse potential OA content offers, OA technical infrastructure must support all of the listed access levels. This can be realised by many systems and services, but it is essential that they operate over the same dataset.
A. The Layered Model of an Aggregation System
We introduce a layered model of the components of an aggregation system that should support the access levels described in the previous section. The layered model of an aggregation system, shown in Figure 3, illustrates the hierarchy of layers of aggregation systems. Each layer uses the functionality or resources provided by a lower layer and provides functionality or resources to an upper layer. Each layer works with information at a different level of abstraction. All horizontal layers must be implemented to build an aggregation system and the concrete implementation of these layers in a real system will significantly influence the overall solution. A decision on how to implement a lower layer will affect the functionality of all upper layers.

Figure 3. Layers of an aggregation system.
The Metadata Transfer Interoperability Layer — This layer provides the necessary processes for metadata harvesting from repositories. This layer often makes use of the OAI-PMH protocol.
The Metadata and Content layer — This layer consist of the metadata and content components. It provides the necessary processes for storing, updating and accessing both content and metadata. The content component is also responsible for various format conversions. The metadata component works with data objects typically represented using technologies such as XML or RDF, and often conforming to a standard, such as Dublin Core4. The content component works with data objects in various open or proprietary formats including the Portable Document Format or the MS Word format.
The Enrichment layer — This layer includes processes for the cleaning and harmonisation of metadata as well as semantic enrichment of the metadata using content-based analysis. Such processes might be fully automated, semi-automated, can make use of crowdsourcing, or can be manual. The fully automated technologies can make use of external knowledge sources, such as Linked Open Data, or various content analysis approaches (e.g. information extraction). The Enrichment layer can be implemented (from metadata) even if the content is not available, but this will obviously restrict the functionality that can be provided by the aggregation.
The OLTP and OLAP layer — This layer contains two components, the OLTP and the OLAP component. The OLTP (Online Transaction Processing) component provides the entire functionality necessary for handling transaction-oriented requests. In the context of aggregations of research papers, we can consider transactions as processes providing access and information at the level of a single article or a relatively small set of articles. On the other hand, the OLAP (Online Analytical Processing) component provides the necessary processes for supporting the analysis of the metadata and content held in the aggregation at the level of the whole collection or large sets of items.
The Interfaces layer — The Interfaces layer is responsible for handling and supporting the communication with the users of the aggregation at the desired level of granularity.
B. The Metadata and Content Components
Every aggregation system will provide an implementation of the mentioned layers. However the implementation can differ significantly from system to system. A system might choose not to implement a certain component of a layer, but it has to implement all mentioned layers. For example, an aggregation system might choose not to implement the content component, but in that case it has to implement at least the metadata component. Similarly, a system has to implement OLTP or OLAP. Decisions about the extent of the implementation have a high impact on all the upper layers. Therefore, this is particularly important in the case of the Metadata and Content layer. If a system decides not to implement the content component, the decision will impact all the upper layers. While it will still be possible to perform enrichment or generate statistics, the enrichment will not be able to make any use of text-mining or other content analysis tools and the information provided by the statistics will be limited to that present in the metadata.
Surprisingly, it is possible to see that a large majority of existing OA aggregation systems, including BASE and OCLC WorldCat, rely on the use of metadata. Relying on metadata has a number of disadvantages among the most important of which are:
- Certain types of metadata can only be created at the level of aggregation — The content constituting full-texts or research data can be used to extract metadata that cannot be discovered or curated by the data providers themselves. Certain metadata types can hardly be created at the level of the data provider, because they need context or because they are changing in time. For example, semantic relatedness of a full-text paper to other papers across repositories cannot be created by the repositories themselves and may change as new content is added to the collection.
- Content preprocessing is often not only a desire, but can become a necessity — Further processing of content supplied by repository providers and its conversion into a more usable format can usually be more easily done at the level of aggregation than at the level of the content consumers or providers. Conversions or enrichment processes might require considerable computing resources which might not be available in a small institutional repository, but may be readily available and optimised at the aggregation level. For example, for the purposes of text analysis, access to the plain text is essential. Aggregators can provide the infrastructure for format conversions and provide researchers and various services with a more convenient way to access data.
- Availability, validity and quality — Without access to content, the aggregator has no means for checking content availability, validity and quality as it has to rely on the information provided in the metadata. By availability we understand that the resource described by the metadata record is held in the system and that it is currently available and accessible for a particular audience. Validity means that the metadata used for the description are appropriate. Finally, quality refers to the fact that the resource satisfies the criteria for being offered by the aggregator.
4. The CORE System
In this section, we introduce the CORE system and describe the functionality it offers at each of the layers defined in the previous section. The system design addresses the above mentioned issues hindering the reuse potential and impact of OA, in particular:
- Offering support for three groups of users according to the primary way they communicate with the aggregation (i.e. raw data access, transaction access, analytical access).
- Supporting open exposure of raw metadata and content to allow further development and reuse.
- Acknowledging the importance of content as a key component of an aggregation system (as opposed to metadata only aggregations).
The main goal of the CORE system is to deliver a platform that can aggregate research papers from multiple sources and provide a wide range of services on top of this aggregation. The vision of CORE is to use this platform to establish the technical infrastructure for Open Access content taking into account the different needs of users participating in the OA ecosystem.
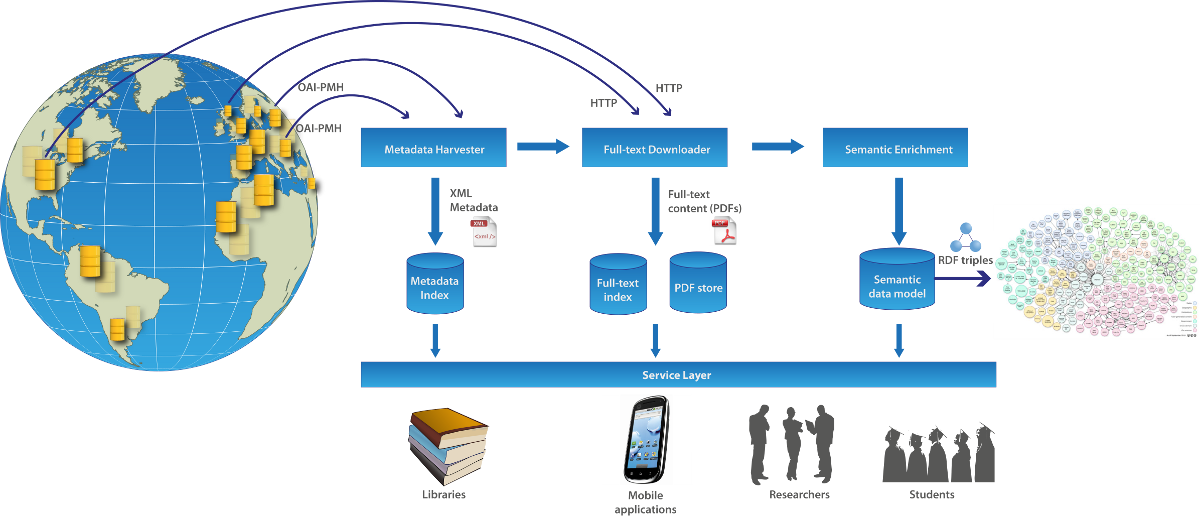
The CORE system offers technical support for three phases: metadata and full-text content aggregation (corresponding to the Metadata Transfer Interoperability layer and the Metadata and Content layer), information processing and enrichment (corresponding to the Enrichment layer) and information exposure (corresponding to the OLTP and OLAP layer and the Interface layer). The overall process is depicted in Figure 4.

Figure 4. The CORE processes.
[View detail in a larger version of this image.]
{kind=link}
A. The Metadata and Content Components
In the metadata and full-text content aggregation phase, the CORE system harvests metadata records and the associated full-text content from Open Access repositories listed in CORE. The harvesting of the metadata is performed using OAI-PMH requests sent to the repositories.5 Successful requests return an XML document containing information about the papers stored in a repository. A good practise in repositories, unfortunately not consistently applied, is to provide as part of the metadata the links to the full-text documents6. The CORE system extracts these links and uses them to download full-texts from repositories. The system then carries out format conversions, such as the extraction of plain text.
The CORE system supports the harvesting and downloading of content from multiple repositories at the same time and has been optimised to utilise architectures with multiple processors. The harvesting component in CORE can be controlled using a web interface accessible to the system administrator. The system supports adding/removing and editing repositories, importing and synchronising repository updates with the OpenDOAR repository registry, and the scheduling and monitoring of the harvesting process.
B. Information Processing and Semantic Enrichment
The goal of the information processing and semantic enrichment is to harmonise and enrich the metadata using both the harvested metadata as well as the full-text content. Given the fact that metadata harmonisation and cleaning in aggregation systems is the de facto standard, we will focus on how the CORE system utilises the full-text. First, the system runs a standard text preprocessing pipeline including tokenisation, filtering, stemming and indexing of the metadata and text. A number of text mining tasks is then performed. They include the discovery of semantically related content, categorisation of content, extraction of citations and citation resolution. New data and text mining algorithms can be added to the system and we plan to do so as we progress.
Discovery of semantically related content — information about the semantic relatedness of content can be used for a number of purposes, such as recommendation, navigation, duplicates or plagiarism detection. CORE estimates semantic relatedness between two textual fragments using the cosine similarity measure calculated on term frequency-inverse document frequency (tfidf ) vectors. Details of the similarity metric are provided in (Knoth, et al., 2010). Due to the size of the CORE dataset7 and consequently the high number of combinations, semantic similarity cannot be calculated for all document pairs in reasonable time. To make the solution scalable, CORE uses a number of heuristics, to decide which document pairs are unlikely to be similar and can therefore be discarded. This allows CORE to cut down the amount of combinations and to scale up the calculation to millions of documents. CORE supports the discovery of semantic relatedness between two texts held in the CORE aggregator. In addition, the system supports the recommendation of full-text documents related to a metadata record and the recommendation of a semantically related item held in the aggregator for an arbitrary resource on the web.
Categorisation of content — content stored in OA repositories and journals reflects the diversity of research disciplines. For example, information about the specific subject of a paper (e.g. computer science, humanities) can be used to narrow down search, to monitor trends and to estimate content growth in specific disciplines. Only about 1.4% (Pieper and Summann, 2006b) of items in OA repositories have been classified and manual classification is costly. We recently carried out a series of experiments with text-classification of full-text articles into 18 top-level classes of the DOAJ classification using a multiclass SVM. The experiments were carried out on a large balanced dataset of 1,000 documents, articles randomly selected from DOAJ. The system produced encouraging results achieving about 93% accuracy.
Extraction of citations and citation resolution — CORE uses the ParsCit system to extract citation information from the publications full-text. This information is used in turn to check if the (cited) target documents are also present in the CORE aggregation to create a link between the cited publications. Within the currently running DiggiCORE project, we aim at extracting and releasing these citation networks for research purposes.
C. Information Exposure
In the information exposure phase, the system provides a range of services for accessing and exposing the aggregated data. At the moment, the services are delivered through the following applications: CORE Portal, CORE Mobile, CORE Plugin, CORE API and Repository Analytics. All of these tools utilise the information provided by the lower layers, in particular the Semantic Enrichment layer and the Metadata and Content layer.
CORE Portal — a web-based portal for searching, exploring and accessing the aggregated content. CORE Portal is not just another search engine for scholarly materials. CORE follows the idea that a resource can only be regarded as Open Access if its full-text is openly accessible. While this might sound trivial, the usual practise of green Open Access aggregators is to aggregate metadata of resources and not check the availability of the full-text. CORE takes a different approach ensuring the availability of information specified in the metadata. Consequently, all search results produced by the system as a response to a user's query will contain links to openly accessible full-texts (unless explicitly requested otherwise by the user), for the purposes of availability and reliability cached on the CORE server. In addition to search, the CORE Portal offers other services on top of the aggregated Open Access collection utilising the information provided by the lower layers, including content recommendation and navigation, duplicates filtering, citation extraction, etc.
CORE Mobile (for Android, for iOS) — functionality similar to the CORE Portal, but using a mobile application. It is an application for iOS (iPhone, iPad, iPod Touch) and Android devices, which can be used on both smartphones and tablet devices. The application provides search and navigation capabilities across related papers stored in OA repositories. It also supports downloading of full-text articles to the mobile devices.
CORE Plugin — a platform- and browser-independent plugin for digital libraries and institutional repositories that provides information about related documents. The plugin recommends semantically related papers to the document currently being visited and the recommendations are based on either full-text or metadata.
CORE API — two APIs enabling external systems and services to interact with the CORE system. The first is a REST API which supports tasks such as searching for content using various criteria, downloading documents in PDF or plain text, getting information about related documents, and detecting the subject of a research text. The second API is a SPARQL endpoint to the CORE repository registered in the Linked Open Data cloud. It provides information about the harvested papers and their similarities encoded in the RDF format.
Repository Analytics — a tool that enables monitoring the ingestion of metadata and content from repositories and provides a range of data and usage statistics including the amount of content, accesses to the content, availability and validity of the metadata and content.
5. Serving the Needs of Multiple User Groups
The CORE applications convey information to the user at the three levels of abstraction specified in Section 3. The CORE API communicates information in the form of raw data typically requiring further processing before it can be used for the task at hand. CORE Portal, CORE Mobile and CORE plugin make all use of a user interface to convey information at the level of individual articles. Repository Analytics provide information at the level of the whole collection or subcollections.
CORE supports all three types of access specified in Table 2 and also provides functionality for all the user groups identified using a single dataset and at the content level (not just metadata). While we do not claim that CORE provides all functionality that these user groups need or desire8, we do claim that this combination provides a healthy environment on top of which the overall OA technical infrastructure can be built. For example, it allows eResearchers to access the dataset and experiment with it, perhaps to develop a method for improving a specific task at the transaction level (such as search ranking) or analytical level (such as trend visualisation). The crucial aspect is that the method can be evaluated with respect to existing services already offered by CORE (or by anybody else) built on top of the CORE aggregated dataset, i.e. the researcher has the same level of access to the data as the CORE services. The method can now also be implemented and provided as a service using this dataset. The value of such an infrastructure is in the ability to interact with the same data collection at any point in time at the three access levels. This allows the propagation of findings and ideas in a top down or bottom up fashion between these levels and thereby between different user groups. This creates an environment in which technologies can be applied and tested soon after they are developed on a transparent data sample.
A question one might ask is why should an aggregation system like CORE provide support for all three access levels when the job of an aggregator is often seen as just aggregating and providing access. As we explained in Section 3, the whole OA technical infrastructure can consist of many services providing they are built on the same dataset. While CORE aims to support others in building their own applications, we also recognise the needs of different user groups (apart from researchers and developers) and want to support them. Although this might seem a dilution of effort, our experience indicates that about 90% of developers time is spent in aggregating, cleaning and processing data, and only the remaining 10% in providing services working with this data. This is consistent with the findings of Manghi, et al., (2010b) who notes that building aggregations is an expensive task. It is therefore not only needed that research papers are Open Access, the OA technical infrastructures and services should also be metaphorically open access, opening new ways for the development of innovative applications, allowing analytical access to the content while at the same time providing all basic functions users need, including searching and access to research papers.
6. Future Work
At the time of writing, CORE has aggregated millions of articles from hundreds of Open Access repositories9. In the future we expect to continue adding more content and repositories as they appear. CORE uses the APIs of repository registries, such as OpenDOAR to discover new repositories and update information about the existing ones. In the future, we aim to work towards improving the freshness of information in CORE by increasing the frequency of updates from individual repositories.
In terms of services, we aim at adding more semantic enrichment processes and making use of their results at all three access levels with a particular focus on the raw data access level currently realised through the CORE API. For example, as part of the Digging into Connected Repositories (DiggiCORE) project our goal is to provide information about citations of papers between OA articles. This information can be utilised at the raw data access level to provide developers and eResearchers with convenient access to the OA citation graph, both at the transaction level to improve navigation between papers and at the analytical level to, for example, discover the most cited repositories.
7. Discussion
The huge amount of content openly available online offers a lot of opportunities for semantic enrichment realised through text mining, crowdsourcing, etc. Exploiting this content might completely redefine the way research is carried out. We may be standing at the brink of a research revolution, where semantic enrichment or enhancement and Open Access will take the lead role. However, there are two frequently discussed issues slowing down or even preventing this from happening — legal issues and the issue of scientific esteem and recognition.
In a recent study commissioned by JISC (McDonald and Kelly, 2012), it was reported that copyright law and other barriers are limiting the use of semantic enrichment technologies, namely text-mining. In our view, this creates a strong argument for the wide adoption of Open Access in research. If semantic enrichment technologies are applied as part of an OA technical infrastructure in a way that provides significant benefits to users, users will prefer OA resources and this will create pressure on commercial publishers. To fully exploit the OA reuse potential, it is therefore important to better inform the Open Access comunity about both the benefits and commitments resulting from OA publishing. In particular, publishers should be aware of the fact that the content they publish might be processed and enriched by machines and the results further distributed. Similarly, the academic community should be better informed about the benefits of increased exposure and reuse potential of their research outputs due to these technologies.
The second often discussed issue is that of building confidence in Open Access. Apart from a few successful OA journals, such as those maintained by PLoS or BioMed central, it is still (possibly wrongly) believed that OA journals today typically do not compare in terms of impact factor with their commercial counterparts. However, the traditional impact measures based purely on citations are inappropriate for use in the 21st century (Curry, 2012) where scientific debate is happening often outside of publications, such as on blogs or social websites, and where scientific results do not always materialise into publications, but also into datasets or software. Instead of trying to achieve high impact factors by establishing government policies that would require researchers to deposit their results as Open Access, we need to develop a technical infrastructure that will be completely transparent and will enable us to establish new measures of scientific importance. At the same time we need methods and tools that will provide analytical information, including trends, about the OA content. This will strengthen the argument for both academics and publishers to adopt Open Access as a default policy.
Overall, we believe that what OA needs now is a technical infrastructure demonstrating the advantages of OA policy over traditional publishing models. This can be achieved by supporting all participating user groups at all three access levels described. The evidence suggests that the critical mass of content is already available. If the OA technical infrastructure helps to redefine the way researchers communicate, and to articulate these benefits to all participating user groups, legislation changes and/or political stimulation10 might not be necessary to realise the OA vision.
8. Conclusion
This paper articulated the need for a technical infrastructure for Open Access research papers and analysed its requirements. We believe that such an infrastructure should not only provide search functionality (though the search tools are essential), it should provide support at the three identified access levels addressing the needs of different user groups. One of the most important user groups is comprised of eResearchers and developers who need access to raw data so that they can analyse, mine and develop new applications. Such an infrastructure does not exist, and we claim that its nonexistence is hindering the positive impact of Open Access in much the same way as other issues, such as scientific esteem and recognition which are more frequently discussed. The CORE system presented in this paper attempts to fill this gap, providing support at all of the presented access levels.
9. Acknowledgement
This work has been partly funded by JISC and AHRC. We would also like to thank the contributions of the those involved in the development of the CORE software (Vojtech Robotka, Jakub Novotny, Magdalena Krygielova, Drahomira Herrmannova, Tomas Korec, Ian Tindle, Harriett Cornish and Gabriela Pavel) and those who regularly participated to CORE Advisory Boards and other meetings (Owen Stephens, Bill Hubbard, Andy McGregor, Stuart Dempster, Andreas Juffinger, Markus Muhr, Jan Molendijk, Paul Walk, Chris Yates, Colin Smith and Non Scantlebury).
10. Notes
1In this article, the concept of raw data refers to structured or unstructured publication manuscript data provided by repositories, or resulting from processing at the level of aggregation, to be used for further machine processing. Our concept of raw data is different from the more frequently discussed concept of research data which typically refers to data in the form of facts, observations, images, computer program results, recordings, measurements or experiences, in which an argument, test or hypothesis, or another research output, is based.
2http://www.d-net.research-infrastructures.eu/node/8.
3There is not a single authoritative definition of an eResearcher. In this paper, we consider an eResearcher to be a researcher applying information technology with the goal of analysing or improving the research process. An example might be a researcher applying text-mining to semantically enrich research manuscripts, a person analysing bibliometric publication data or a social scientist looking for patterns in the way researchers collaborate.
4Although Dublin Core is considered a standard, in practise, Dublin Core metadata provided by different systems differ significantly and consequently there is relatively limited interoperability between systems.
5The CORE system is not inherently limited to any specific harvesting protocol and it also enables other types of data ingestion, such as import from a specific folder in the file system or ingestion of content by crawling content available on the web. However, OAI-PMH harvesting dominates other types of metadata gathering.
6The OAI-PMH protocol itself is not directly concerned with the downloading of full-text content, as it focuses only on the description and the transfer of metadata.
7Currently over 9 million records from over 270 repositories.
8CORE is certainly in its infancy and improving the existing services as well as adding new services is something that is expected to be done on a regular basis.
9Up-to-date statistics are available on the CORE Portal.
10For example, the policy recommended by the Finch report.
11. References
[1] Bo-Christer Björk. 2003. Open access to scientific publications — an analysis of the barriers to change. Information Research, 9(2).
[2] Petr Knoth, Jakub Novotny, and Zdenek Zdrahal. 2010. Automatic generation of inter-passage links based on semantic similarity. In Proceedings of the 23rd International Conference on Computational Linguistics (Coling 2010), pages 590-598, Beijing, China, August.
[3] Carl Lagoze, Dean B. Krafft, Sandy Payette, and Susan Jesuroga. 2005. What Is a Digital Library Anymore, Anyway? Beyond Search and Access in the NSDL. D-Lib Magazine, 11(11). http://dx.doi.org/10.1045/november2005-lagoze
[4] Martha Fallahay Loesch. 2010. OAISter database http://oaister.worldcat.org/. Technical Services Quarterly, 27(4):395-396. http://dx.doi.org/10.1080/07317131.2010.501001
[5] V. Lyte, S. Jones, S. Ananiadou, and L. Kerr. 2009. UK institutional repository search: Innovation and discovery. Ariadne, 61, October.
[6] Paolo Manghi, Marko Mikulicic, Leonardo Candela, Michele Artini, and Alessia Bardi. 2010a. General-purpose digital library content laboratory systems. In Mounia Lalmas, Joemon M. Jose, Andreas Rauber, Fabrizio Sebastiani, and Ingo Frommholz, editors, ECDL, volume 6273 of Lecture Notes in Computer Science, pages 14-21. Springer. http://dx.doi.org/10.1007/978-3-642-15464-5_3
[7] Paolo Manghi, Marko Mikulicic, Leonardo Candela, Donatella Castelli, and Pasquale Pagano. 2010b. Realizing and maintaining aggregative digital library systems: D-net software toolkit and oaister system. D-Lib Magazine, 16(3/4). http://dx.doi.org/10.1045/march2010-manghi
[8] Diane McDonald and Ursula Kelly. 2012. Value and benefits of text mining. In JISC Report.
[9] Dirk Pieper and Friedrich Summann. 2006a. Bielefeld Academic Search Engine (BASE): an end-user oriented institutional repository search service. Library Hi Tech, 24(4):614-619. http://dx.doi.org/10.1108/07378830610715473
[10] Eloy Rodrigues and Abby Clobridge. 2011. The case for interoperability for open access repositories. Working Group 2: Repository Interoperability. Confederation of Open Access Repositories (COAR).
[11] Mikael Laakso and Bo-Christer Björk 2012. Anatomy of open access publishing: a study of longitudinal development and internal structure. BMC Medicine 2012. http://dx.doi.org/10.1186/1741-7015-10-124
[12] Gargouri, Y, Lariviere, V, Gingras, Y, Brody, T, Carr, L and Harnad, S. 2012. Testing the Finch Hypothesis on Green OA Mandate Ineffectiveness.. In Open Access Week 2012, Preprint, http://eprints.soton.ac.uk/344687/
[13] Stephen Curry. 2012. Sick of Impact Factors. Blog. http://occamstypewriter.org/scurry/2012/08/13/sick-of-impact-factors/
About the Authors
 |
Petr Knoth is a researcher in the Knowledge Media institute, The Open University focusing on various topics in digital libraries, natural language processing and information retrieval. Petr has been the founder of the CORE system and has been involved in four European Commission funded projects (KiWi, Eurogene, Tech-IT-EASY and DECIPHER) and four JISC funded projects (CORE, ServiceCORE, DiggiCORE and RETAIN). Petr has a number of publications at international conferences based on this work. |
 |
Zdenek Zdrahal is a Senior Research Fellow at Knowledge Media Institute of the Open University and Associate Professor at The Faculty of Electrical Engineering, Czech Technical University. He has been a project leader and principal investigator in a number of research projects in the UK, Czech Republic, and Mexico. His research interests include knowledge modelling and management, reasoning, KBS in engineering design, and Web technology. He is an Associate Editor of IEEE Transactions on Systems, Man and Cybernetics. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |