|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2012
Volume 18, Number 1/2
ARROW: Accessible Registries of Rights Information and Orphan Works Towards Europeana
Cinzia Caroli and Gabriella Scipione
CINECA, InterUniversity Computing Centre Information and Knowledge Management Services
Elda Rrapi and Giuseppe Trotta
mEDRA, multilingual European DOI Registration Agency
Point of contact for this article: Gabriella Scipione, g.scipione@cineca.it
doi:10.1045/january2012-caroli
Abstract
The European Union promotes programs of "mass digitization" in order to make the cultural and scientific resources in Europe accessible to all, and to preserve them for future generations. The Accessible Registries of Rights Information and Orphan Works Towards Europeana (ARROW) project began in September 2008 with the aim of facilitating the management of rights in digitization projects. Partial funding was provided by the European Commission under the programme "ICT Policy Support". The outcome of the project was an automated system for distributed management of rights information that meets the needs of digital libraries and is easily adaptable to other contexts of use. With the approval of the "ARROW Plus" project in April 2011, the system will be further improved, extending the number of covered countries, and integrating rights information about images contained in books.
Introduction
The "i2010 Digital Library Initiative" [1] is an initiative of the European Union's digital libraries that aims to make accessible to all, and preserve for future generations, the European cultural and scientific resources: books, periodicals, films, maps, photographs, music. A key element in digitization and access to digital content is to know clearly the rights status of the content. This is an important issue especially for libraries that intend to digitize their entire catalogues. In many cases, rights holders (or their agents) can be identified, traced and then contacted to request permission to digitize, but often these procedures are time consuming and have high costs. It can happen that rights holders cannot be identified or traced even after a "diligent search" [2] is performed. In that case the work is considered an "orphan" [2] and can neither be used nor digitized with legal certainty. Another problem regards the "out-of-print" works [2]; that is, works claimed by their rights holders as not commercially available. In this context, making this type of content available online can be in conflict with the use of recent versions of it, or can impact the economic interests of copyright holders.
In many countries there are good resources that provide rich bibliographical information on books in print (and out of print books on a smaller scale). However, such resources are not homogeneous at the European level (in particular, they are not present in certain countries recently included in the EU). The main limitation is the lack of interoperability between them, both at the metadata level and at the communication protocols level. Although the bibliographic databases can contain rich information about books in print, they do not contain metadata about rights and permissions of use. This information is instead maintained by publishers, authors and collecting societies in different formats, and is not readily available.
The ARROW project
The Accessible Registries of Rights Information and Orphan Works Towards Europeana [3] (ARROW) project started in September 2008 with the aim of facilitating the management of rights in digitization projects [4]. It was co-funded by the European Commission under the programme "ICT Policy Support" theme 2 Digital Library. The ARROW project involved the main European players in the value chain of the book (national libraries, bibliographic agencies, associations of authors/publishers, management companies of the copyright) in the following EU countries: Spain, France, UK and Germany. The Italian Publishers Association [5] was the coordinator of the project. Cineca [6] was the main technology provider.
The scope of the project focused on books in order to test the feasibility for this type of content. The main objectives were:
- to demonstrate in practice how to handle the problems of copyright in the digital world,
- to foster collaboration between authors, publishers and libraries,
- to use current technology to automate as much as possible the "diligent search" procedure
- to provide the contact information of the various rights holders.
ARROW system as interoperability facilitator
The system developed during the ARROW project is a distributed infrastructure made up of the following components:
- the ARROW Web Portal Services: the interface between the user and the system;
- the Rights Information Infrastructure (RII): the backbone of the ARROW system and the engine that enables ARROW to query and retrieve information from a network of databases, in order to process this information and take the appropriate action, and finally to exchange information according to a planned workflow;
- the ARROW Work Registry (AWR): storage for all the relevant pieces of information collected by the RII workflow in a structured way that allows the retrieval and use of that information in the framework of ARROW services;
- the Registry of Orphan Works (ROW): the subset of the AWR referring to works that have been declared as "probably orphan".
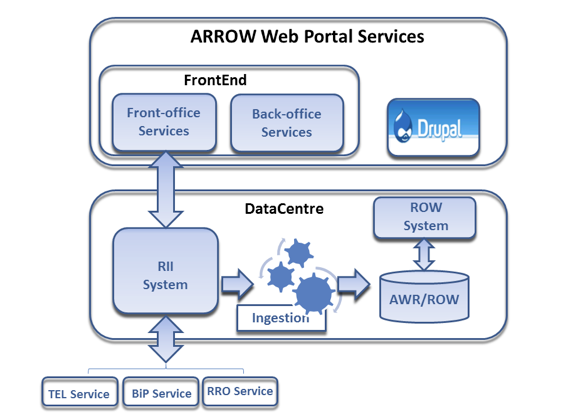
Figure 1: ARROW system overview
Creating a distributed network of data sources, ARROW acted as "interoperability facilitator", ensuring interoperability between all communities and successfully tackling the following issues:
- data were not interoperable at the transnational level; only the domain of libraries was characterized by a level of interoperability sufficient for the purposes of ARROW, thanks to the role played by The European Library (TEL) [7];
- catalogues of libraries were not interoperable with catalogues of books in print, and none of them were interoperable with the repertoires of the Reproduction Rights Organisations (RRO);
- data maintained in the various domains were created at the "book" level ("manifestation"), while the rights were defined in terms of "work" ("expression").
For the automatic exchange of metadata between the different sources involved in the project, the ARROW team, in collaboration with the specialist support of EDItEUR [8], experimented with a suite of messages designed ad hoc. This suite of messages is called "ONIX for Rights Information Services" (ONIX-RS) and its first formal version 1.0 was published in October 2011. ONIX-RS relies heavily on the original work of ARROW, but has been extended to accommodate other flows of information in the field of rights, so that it can be used by other organizations or associations working in this field. The ARROW system integrates into its workflow the VIAF service [9], in order to obtain additional information regarding authors and other contributors, like the date of death, nationality and all the possible variants of names.
The Rights Information Infrastructure (RII)
The Rights Information Infrastructure component of ARROW manages the complex workflow (see Figure 2 below) that retrieves information from data sources belonging to the different actors in the value chain of the book: libraries, databases of books in print (BiP) and repertoires of Reproduction Rights Organisations (RRO). The collected information is processed to obtain the copyright status and the publishing status of the work corresponding to the submitted manifestation (book) as well as of the related works . Other important results obtained at the end of the workflow include a set of information provided by the RRO concerning licensing conditions and reasons supporting the decisions, as well as the identification of works that are probably orphan.
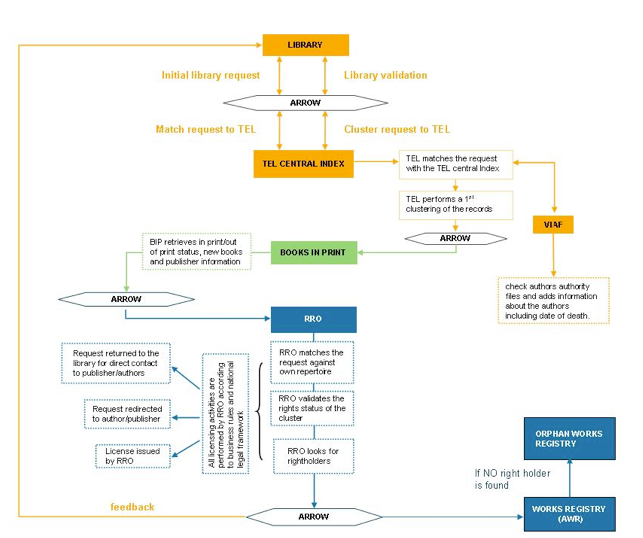
Figure 2: ARROW Workflow diagram
The RII receives the requests for permission to digitise and use the manifestation of a work (for instance a book) from the libraries. It queries the data providers included in the workflow of the country where the book was published (The European Library (TEL)/ Virtual International Authority File (VIAF), Books in Print, RRO) and compiles the gathered results, in order to provide the resulting information on the rights status.
The initial library request is performed at the manifestation level (to be more precise, the initial library request refers to a "resource" where the term resource identifies an instance of a manifestation, for example a particular copy of a printed edition of a book), whereas the response at the end of the workflow is provided at the work level. This means that the initial request passes through stages of identification and matching, work and manifestation clustering and the identification of related works and manifestations; each process adds a piece of relevant information towards the identification of the rights status of the work.
As illustrated in Figure 2 above, the RII workflow can be partitioned in three main stages:
- The first stage (orange highlighted part of Figure 2) takes place in the library domain and involves TEL as main actor and VIAF as source for author's information. As output of this stage the following information is obtained:
- the work to which the original library manifestation belongs;
- a list of manifestations sharing the same work;
- any other related work and the list of respective manifestations;
- a set of authoritative information for each author and other contributor of each work, including preferred and alternative forms of their names, their dates of birth and death, their nationality;
- the copyright status of each work: whether the work is in the public domain or copyrighted, or that this information cannot be certainly asserted.
- The second stage (green highlighted part of Figure 2) takes place in the Books in Print domain and involves BiP organisations or databases in each of the countries included in the ARROW system. As output of this stage the following information is obtained:
- a list of additional manifestations belonging to the work and related works;
- the in print/out of print status and the commercial availability of each manifestation belonging to the work and related works;
- the Publishing Status of each work: whether the work is currently active (in print) or currently not active (out of print), or that this information cannot be certainly asserted.
- The third stage (blue highlighted part of Figure 2) takes place in the Reproduction Rights Organisation domain and involves RROs or databases in each of the countries included in the ARROW system and adds further information to the output obtained from the previous process in the library and BiP domains. The output of this stage includes the following information:
- a set of information provided by the RRO concerning licensing conditions and reasons supporting the decisions;
- the Orphan Status of the work: whether the work is to be considered probably orphan as the rights holders cannot be identified or traced, or not orphan, or that this information cannot be certainly asserted.
As a result of the above workflow, the following pieces of information have been retrieved:
- Work information
- Manifestation information
- Relationship between manifestations and the work they belong to
- Relationship between works
- Authors and other contributors information
- Relationship between identified authors and the work they have contributed to
- Relationship between each piece of information (work, manifestation, author) and the reference source that provided that information (TEL, VIAF, BIPs, RROs)
- A set of so called ARROW Assertions on each work: Copyright Status, Publishing Status and Orphan Status
ARROW Work Registry (AWR) stores and maintains all of these pieces of information for every request processed by the ARROW system.
RII Layered Architecture
In order to increase the flexibility, scalability, maintainability and reuse, the RII system is based on a layered architecture as shown in Figure 3 below.
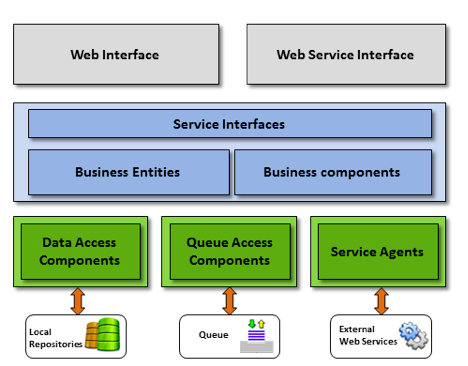
Figure 3: RII Layered Architecture
The Presentation Layer is the topmost level of the application. It consists of two components: the web interface that presents results to the end user and the web service interface that exposes machine-readable data to external services.
The Service layer is composed of the Business Entities and the Business Components. The former represents the application domain model. Each entity is modelled as a JavaBean which does not contain any service logic. The service logic instead is performed by the 'business components' that contain all the necessary logic and processes required by the system. The processes are carried out by appropriate managers. Each manager is responsible for operating on one or more Business Entities and performing complex elaboration on these entities. The Service Layer exposes the service logic to external users by means of well-defined interfaces.
The Data Layer provides access to either data maintained within the RII system or to data exposed by external services. The RII data layer has three main components:
- Data Access Component. This component provides abstract interfaces in order to access the underlying persistence storage. This way the persistent data is neutral and independent from the Service Layer.
- Queue Access Component. The RII architecture is an asynchronous one based on message queues. This component provides abstract interfaces in order to access the underlying queues.
- Service Agents. The Service Layer must use data exposed by external heterogeneous services, so it is necessary to implement different kinds of connectors in order to handle the communication semantics for each of them. The Service Agents isolate the communication peculiarities of all the external services in order to make such interaction transparent to the Service Layer.
The ARROW Work Registry (AWR) and the Registry of Orphan Works (ROW)
At the end of the ARROW workflow, the results produced by the RII populate both the RII repository and the ARROW Work Registry. The ARROW Work Registry (AWR), in turn, forms the foundation for the Registry of Orphan Works (ROW). In fact, the works stored in the AWR that are at any point in time marked as "ProbablyOrphan" are added to the ROW.
The starting point for the design of the Registry of Orphan Works within the ARROW system was provided by the High Level Expert Group (HLEG) Final Report on Digital Preservation, Orphan Works and Out of Print Works, which included recommendations and key principles for rights clearance centres and databases for orphan works [2]. In addition, in order to define the ROW requirements, the different stakeholder communities represented in the ARROW consortium and in the countries in the pilot system were consulted. The main stakeholders involved were the Collective Management Organisations and Reproduction Rights Organisations, identified by the HLEG as natural candidates to run Orphan Works databases and Rights Clearing Centres at this time.
The design of the ARROW Work Registry (AWR) also considered the ISTC [10] metadata for works, in order to guarantee interoperability with the services provided by the ISTC international agency for ISTC registrations. The information about works contained in the Registry of Orphan Works was made publicly searchable through a web interface, thus allowing the rights holders (individually or through a collective representative organisation or agent) to claim their rights.
ARROW pilot: ready to be used
The ARROW project was completed in February 2011. As of September 2011, the ARROW system can be used to search for works published in France, Germany, Spain and the United Kingdom.
- The pilot in France connects: Bibliothèque nationale de France (BNF) catalogue in The European Library; Virtual International Authority File database; Electre Books in Print database; the French RRO Centre Français d'Exploitation du Droit de Copie (CFC) repertoires.
- The pilot in Germany connects: Deutsche Nationalbiliothek (DNB) catalogue in The European Library; Virtual International Authority File database; Verzeichnis Lieferbarer Bücher (VLB) Books in Print database; the German RRO Verwertungsgesellshaft Wort (VG Wort) repertoires.
- The pilot in Spain connects: Biblioteca Nacional de España (BNE) catalogue in The European Library; Virtual International Authority File database; DILVE Books in Print database lookup via CEDRO; the Spanish RRO Centro Español de Derechos Reprográficos (CEDRO) repertoires.
- The pilot in the United Kingdom connects: British Library catalogue in The European Library (TEL); Nielsen Books in Print database lookup via RRO UK; the UK RRO Copyright Licensing Agency (CLA); the Publishers Licensing Society (PLS) and the Authors' Licensing & Collecting Society (ALCS) repertoires and databases.
System validation
The system validation was carried out for the pilot countries under the leadership of the University Library of Innsbruck [11] and showed (see Table 1 below) a substantial benefit to using ARROW to search for authors, publishers, works and rights status, compared to the traditional manual search: the time savings varied from 72% in the Spanish pilot to 97% in the UK pilot. In large digitisation projects, time savings at this level represent substantial cost reductions for libraries, as well as for others who need to retrieve copyright information on books.
Table 1: Time Saved Using ARROW; 63-102 Records
| Country | Manual Search Hours | ARROW Search Hours | Hours Saved |
| France | 34.0 | 4.0 | 30.0 (88%) |
| Germany | 52.0 | 3.0 | 49.0 (94%) |
| Spain | 12.7 | 3.5 | 9.2 (72%) |
| UK | 184.0 | 4.5 | 175.9 (97%) |
Further results regarding the ARROW system validation can be found in the study undertaken by the British Library [12] on a random selection of 140 books published between 1870 and 2010 from its own collection. The study sought to determine whether permission could be received to digitise the books and to compare the outputs of a "manual" diligent search for rights holders against the "automated" diligent search of the ARROW system.
Additionally, during 2011 the Wellcome Library began a pilot digitisation project [13] built around the theme "Modern Genetics and its Foundations", with 1,400 books published between 1850 and 1990. The initiative, funded by the Wellcome Trust, aimed to assess the feasibility of a large digitisation plan that included copyrighted works, in terms of time and costs to undertake the diligent search. The target was to seek permission from rights holders to digitise and make the works available for free through the web.
Wellcome Trust agreed to use the UK RRO services to identify right holders for the books in the pilot. And the UK RRO used the ARROW system themselves to help process the Wellcome Trust records and speed up the diligent search process. As of November 2011, the UK RRO is performing the diligent search for the pilot books, and will be able to provide the needed licensing in 2012.
Future developments
In April 2011, a continuation of the ARROW project was approved. The ARROW Plus project is now in full swing. Its main goals are to extend the number of covered countries, and to analyze and extend its services to the domain of images. The ARROW Plus project includes the main stakeholders in the following countries of the EU area: Spain, France, UK, Italy, Germany, Austria, Slovenia, the Netherlands, Norway, Finland, Denmark, Belgium and Sweden. The Italian Publishers Association will act as coordinator of the project, and CINECA as the technology partner.
Acknowledgements
The authors wish to acknowledge the work of the ARROW Project Team for both the technical and non-technical aspects of this paper.
Notes & References
[1] i2010 Digital Libraries Initiative.
[2] i2010: Digital Libraries High Level Expert Group — Copyright Subgroup (2008), The Final Report on Digital Preservation, Orphan Works and Out of Print Works.
[3] Europeana — the European Digital Library.
[5] AIE is the trade association for Italian publishers.
[6] CINECA is non-profit consortium of 50 Italian universities, the National Research Council (CNR), the National Institute of Oceanography and Experimental Geophysics (OGS) and the Ministry of University and Research (MIUR).
[7] The European Library (TEL).
[8] EDItEUR is the international group coordinating development of the ONIX suite.
[9] Virtual International Authority File (VIAF).
[10] International Standard Text Code (ISTC).
[11] University Library of Innsbruck (2011), "Arrow project results presentation".
[12] British Library (2011), "A rights clearance study in the context of mass digitisation of 140 books published between 1870 and 2010".
[13] Wellcome Trust (2011), "ALCS and PLS provide innovative rights identification service for Wellcome Library digitisation project".
About the Authors
 |
Cinzia Caroli works for Cineca (a non-profit Consortium of 50 Italian universities) where she is a member of the "e-Publishing and University Libraries" team. Her activity has been focused on the technologies for standard identifiers, metadata and rights management. She is also involved in mEDRA and OPOCE DOI Registration Agencies, ARROW and ARROW Plus projects. |
 |
Elda Rrapi is a software analyst at mEDRA (multilingual European DOI Registration Agency) where she is involved in several projects related to metadata management, rights management, and the use of persistent identifiers technologies. She is currently with the ARROW Plus Project, in charge of the software requirement analysis and system architecture design. She has been working for several years on the enhancement of both mEDRA and OPOCE (DOI Registration Agency held by the Office for Official Publications of the European Communities) services. Ms. Rrapi was involved in the original ARROW Project, performing software analysis and ARROW system development. For one year, she was in charge of the development of services for the Italian ISBN Agency. She joined mEDRA in 2006, after earning her degree in Computer Science at the University of Bologna. |
 |
Gabriella Scipione is a Technical Project Manager at CINECA, where she leads the e-Publishing and University Libraries Team. She has been involved in a number of significant EU-funded projects over the last 10 years. Her team focuses on persistent identifiers, metadata management, rights management, digital archive, open access. She is technical coordinator and development teams leader in the Arrow and ArrowPlus projects. Ms. Scipione is also involved in Scholarly Communications projects, including VOA3R, an integrated service for the retrieval of relevant open content from Italian Universities' Research Information Systems. Since 2002, she has been technical coordinator of the multilingual European DOI Registration Agency (mEDRA) project, following the evolution of mEDRA from a pilot project to a service company. |
 |
Giuseppe Trotta is a Software Engineer and a Research and Development Officer currently working at mEDRA, which he joined in 2008. He supervises the analysis, design and implementation phases of the ARROW Plus project, while coordinating and coaching his colleagues in innovative technologies. He graduated in Computer Science at the University of Bologna prior to joining mEDRA, where he will further develop and advance his optimized implementation of a federated protocol for metadata harvesting. Currently, he is the Software Engineer in charge of R&D, and system and performance enhancements. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |