|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |
D-Lib Magazine
January/February 2011
Volume 17, Number 1/2
The Dataverse Network®: An Open-Source Application for Sharing, Discovering and Preserving Data
Mercè Crosas
Institute for Quantitative Social Science, Harvard University
mcrosas@hmdc.harvard.edu
doi:10.1045/january2011-crosas
Abstract
The Dataverse Network is an open-source application for publishing, referencing, extracting and analyzing research data. The main goal of the Dataverse Network is to solve the problems of data sharing through building technologies that enable institutions to reduce the burden for researchers and data publishers, and incentivize them to share their data. By installing Dataverse Network software, an institution is able to host multiple individual virtual archives, called "dataverses" for scholars, research groups, or journals, providing a data publication framework that supports author recognition, persistent citation, data discovery and preservation. Dataverses require no hardware or software costs, nor maintenance or backups by the data owner, but still enable all web visibility and credit to devolve to the data owner.
Background
Traditional approaches to storing and sharing data sets in social science have been either inadequate or unattractive to researchers, resulting into only a few scientists sharing their research data. Most professional archives, although often considered the most reliable solution, do not usually facilitate control and ownership of the data by the author. Once the author submits the data, the archive becomes fully responsible for the data management, cataloging and future updates. While this can be advantageous for some researchers, many prefer to maintain control of their data and to receive increased recognition. Consequently, a researcher will often choose either to offer her data only through her own website, or, more commonly, to simply not share her data at all. Neither choice provides adequate provisions for future preservation or a persistent identificant and access mechanism. Journals and grant funding agencies are starting to require a data management and sharing plan for data authors. (See, for example, http://www.nsf.gov/news/news_summ.jsp?cntn_id=116928.) It is therefore becoming more important than ever to have a solution that satisfies these requirements while proving beneficial to data owners.
The Dataverse Network (DVN) project provides an open source solution to this data sharing problem through technology (King, 2007, http://thedata.org). It offers a central repository infrastructure with support for professional archival services, including backups, recovery, and standards-based persistent identifiers, data fixity, metadata, conversion and preservation. At the same time, it offers distributed ownership for data authors through virtual web archives named "dataverses." Each dataverse provides scholarly citation, custom branding, data discovery, control over updates, and terms of access and use, all through a user-friendly interface. This combination of open source, centralized standards-based archiving and distributed control and recognition makes the DVN unique across data sharing solutions.
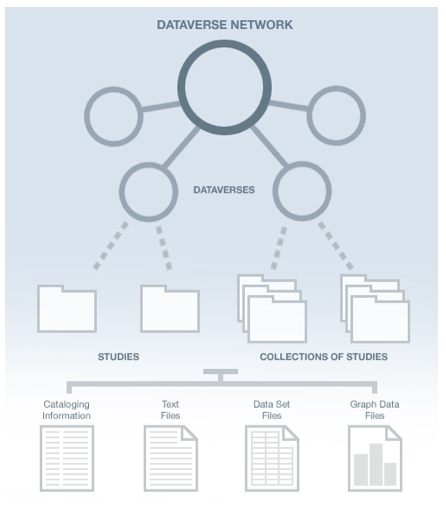
Figure 1. The Dataverse Network hosts multiple dataverses, each one being a virtual web archive for storing and sharing research data. The data are organized in studies, which contain cataloging information (metadata), data files and complementary files. The studies can in turn be grouped into collections.
The DVN software development started in 2006 at the Institute for Quantitative Social Science (IQSS) at Harvard University. It benefited considerably from its predecessor, the Virtual Data Center (Altman et al., 2001). Since its release in 2007, the DVN hosted at IQSS has hosted hundreds of virtual archives, and, in partnership with the Data-PASS alliance (Altman, et. al, 2009), provides access to more than 37,000 studies (each one a separate research unit with its own description, documentation and data sets) and all together constituting more than 600,000 files (on the order of 1 to 2 Tb in total) distributed across hundreds of dataverses. In addition, a growing number of institutions around the world host full DVN's federated with each other.
In the next sections, the solutions that DVN offers for a successful and comprehensive data sharing and preservation system are presented. From incentives for data sharing to interoperability with other systems, the features described below are important for supporting data authors, journals, archivists, researchers and students with the increasingly needed, highly desirable, research data sharing initiative.
Incentives for Data Sharing: Recognition, Visibility, Ownership
The success of data sharing can be enhanced by incentivizing authors with increased scholarly recognition and visibility. Scholarly recognition is traditionally achieved through citations. However, referencing the original publication is insufficient in this case. The data themselves need a formal citation to allow a persistent reference from the original publication or other publications. Data citation facilitates replication of the original research findings while providing deserved credit to data collectors and authors1 . A dataverse fills this need by automatically generating a persistent data citation upon creation of a study. Details on the data citation standards are discussed in the next section.
A dataverse can also be branded like, or embedded within, the author's website. As a result, the data appear listed in the author's site, together with all the functionality offered by the dataverse. Authors instantly gain visibility for their work, without having to be concerned about the issues of preservation or archiving, both of which are quietly handled by the centralized DVN repository.
In addition to recognition and visibility, authors want to maintain a level of ownership of the data they have produced. With the dataverse, even though the data reside in a central repository, authors have wide control over updates, descriptive information and restrictions for their data sets.
Persistent Citation for Data
The data citation generated by a dataverse includes: author(s), distribution date, title, global persistent identifier and url, universal numerical fingerprint (UNF), and optional fields such as the distributor, data subsets, and versions. It follows the data citation standard as defined by Altman and King (2007):
Verba, Sidney; Lehman Schlozman, Kay; Brady, Henry E.; Nie, Norman, 1996, "American Citizen Participation Study, 1990", http://hdl.handle.net/1902.2/6635 UNF:3:aGYTy1ubiRXFTnPZBExcdA== Inter-university Consortium for Political and Social Research[Distributor] V1 [Version]
In this data citation, the main additions to traditional citations are the persistent identifier and the UNF. The persistent identifier is critical for citing a digital object. This is what makes the reference permanent and independent; even if the digital object moves from one web site to another, the reference will link to an active web site. The DVN uses the HANDLE.NET® services supported by CNRI, and its Global Handle Registry™ to register the identifiers under a given naming authority handle (prefix). In combination with the local handle service, the HANDLE.NET services ensure that the prefix and identifier assigned to each study always resolve to a working url for the study. The pricing structure for issuing handles is based on the prefix. Since all studies in a DVN are often assigned to one single prefix, an unlimited number of handles can be registered for fixed yearly fee associated with that given prefix.
Since Digital Object Identifiers (DOI® names) are based on handles, it is feasible to extend the DVN software to also support DOIs as the persistent identifiers in the data citation. Once the pricing structure issuing DOIs at a variety of scales has evolved, one can easily imagine supporting some collections using handles and some collections using DOIs within a DVN.
A dataverse assigns persistent identifiers to each study. Since a study might include one or more data sets, each persistent identifier does not necessarily correspond to a single data set. However, a unique UNF — the other part of the citation particular to a digital object — is generated for each data set in the study. The UNF in the study citation is an aggregation of all the UNFs for all the data sets in the given study. A data citation can also be provided to a subset of the data, and in that case, a new UNF is generated which represents only that part of the data. The UNF is generated based on the content of the data sets and not the format, and therefore does not change even if the format of the data changes. Thus, a UNF verifies that the data have not changed independent of the file format, guaranteeing that researchers are using the same data originally created by the data owner (Altman, 2008). UNFs are described further in the next section.
The main objectives of the data citation are to give credit to the data authors, as well as to the data distributors when applicable; to strengthen the link between published results and the evidence base supporting them; and to provide a way to reference the data in perpetuity. The cited data can correspond to a published article, to a pending publication or to a published data set on its own, without an associated article. By generating the data citation automatically when a study is created, even before it is released to the public, the author can already provide a persistent reference to the data in an article for publication, and then release or "publish" the data once the article is in circulation. This offers a convenient solution to journals for linking research findings in an article to the underlying data when the data is not yet made public or released.
Finally, if the research study is updated in the future, the version in the citation is increased automatically. A citation without any versioning will resolve to the most recent study version. However, it is always possible to track back to older versions within a study, and even to verify whether the data set has changed by comparing the UNF of a previous version to the latest UNF.
Format Conversion and Fixity
Data sets uploaded to a dataverse go through the following steps:
- The variable metadata (names, labels, data types) in the data set are separated from the primary data.
- Summary statistics are generated for each variable.
- The data file is reformatted to a preservation format independent of any specific software package.
- A cryptographic algorithm is applied to the canonical format to get an alphanumeric string (the UNF) based on semantic content of the data set.
This data processing is supported for SPSS, STATA and CSV (with control cards for the variable metadata) file formats. The original file is also saved unaltered, and the steps are repeatable if needed in the future.
The benefits of processing and reformatting the data files are obvious and critical to any data repository that guarantees permanence and replication. Statistical software packages used to create data sets today might be not available in the future. Data needs to be stored in a preservation format, and to be easily convertible to upgraded formats used by researchers now and in the future. The UNF helps verify permanently that the data are fixed and unchanged from the data originally used by the author.
Restricted Access
As a data sharing system, the DVN encourages authors and distributors to make their data public. The software, however, supports click-through terms of use and restrictions for those cases in which the author wants to limit the use or access of the data. There are three levels of access control:
- A public study with terms of use. In this case the descriptive information for the study can be viewed without any conditions, but the data files can only be accessed after the user agrees to the terms of use assigned to that study.
- A study with restricted file(s). In this case the descriptive information remains public, but one or more data files are restricted. Only password-authorized users are allowed to view and download the restricted files.
- A restricted study. When the entire study is restricted, the metadata are still searchable, making part of the description discoverable, but access is not allowed to either the full cataloging information or the data files.
Users may request access to a restricted file or a full study, which can subsequently be granted by the dataverse owner who is usually the author or distributor of the data. Authorization to a set of studies can also be given based on a range of IP addresses associated with a university or other institution. Ultimately, however, data authors have control over who can access their data. This is again a way to provide distributed ownership to the author, while the data are secured, preserved and accessible when needed through the DVN.
For restricted data files, there is an added advantage of using the UNF in the data citation. Users can validate that the study held by the archive contains the same data originally cited by the author, even in those cases when the data cannot be accessed.
Protection for Confidential Data
Even though authors can choose to restrict a data set, access control is not sufficient to protect some levels of high-risk confidential information. The DVN approach to this issue is to provide additional protection through click-through terms of use. Upon creation of a study in a dataverse, authors can be required to agree not to deposit data collected without Institutional Review Board (IRB) approval or not to deposit data containing confidential information. On the data user side, upon accessing a data set, a user can be required to agree not to link multiple data sets or additional information about the data that would risk identification of individuals or organizations. The language in the terms of use can be modified for the entire DVN or for each dataverse based on the requirements of the institution, data owners or publishers. For extremely sensitive studies, one can include the metadata of the study in the DVN with the full citation, including the UNF, while storing the data itself securely offline.
A more desirable future solution is to more explicitly support the storage and sharing of data sets with sensitive information since research data increasingly contain some form of confidential information, but would nonetheless be extremely useful for research and the advance of science. This can be achieved with tools that allow systematic analysis of disclosure on deposit; that allow selected files to be stored in separate repositories that provide security controls; and that support statistical disclosure limitation methods for data release and for online analysis. This problem is challenging and the subject of broad ongoing research and development.
Data Discovery
A data-sharing framework would not be complete without useful data discovery functionality. A dataverse provides the capability to browse and search studies within that dataverse or across the entire Dataverse Network. All metadata fields describing the study and the data are indexed allowing advanced field-based searches. The metadata include roughly one hundred fields including cataloging information, such as title, author(s), abstract, date, geospatial information, and metadata fields describing the variables in a data set, such as name and labels.
An application like the DVN not only allows researchers to find and access large data sets available in known archives, but more interestingly, it helps them find and easily access small data sets from other researchers that would otherwise sit in local computers with the risk of being lost.
Subsetting and Analysis
Data subsets and analysis might not be critical to a data-sharing framework but they do likely facilitate data usage and give incentives to data owners by enriching their offerings when using a dataverse. By processing data sets, standardizing formats and extracting variable information, the DVN software makes it possible to offer additional data services to users. Processed data sets can be subset and analyzed on the fly through a dataverse interface. Currently there are two supported data types that offer these additional services: tabular data sets and social network data (Fung, et al., 2010)
1. Tabular Data Sets
Data files with rows and columns (uploaded in SPSS, STATA or CSV file formats, as mentioned above) can be subset so that a user can extract only some of the variables. Also, users can perform recodes, get summary statistics in a numerical or graphical form, and run statistical models for selected variables. The statistical models are powered by Zelig, (Imai, et al., 2008) an R-based framework that standardizes the development and use of almost any statistical method contributed to the popular R statistical language. The dataverse makes use of these methods and runs them in an R server to provide real time analysis of the data without having to download the entire data set.
2. Social Network Data
Social Network data (data that describes a network of entities and relationships) can be uploaded in GraphML (Brandes, et al. 2002, 2010) format to provide additional services available to data users. For example, one can download a subset of the graph and run network measures such as page rank and degree. Subsets can be based on either a manual query or a pre-defined query — such as extracting the neighborhood for a subset of data. The network data files are stored in a neo4j database which facilitates querying complex and large networks.
In the case of networks, it becomes more critical to provide this type of functionality given that large graph data sets are complex in nature and hard to understand without first applying minimal manipulation and extraction of a subset.
Extraction, analysis and (soon-to-be-provided) visualization tools enhance the use of shared data making them more understandable and manageable even when data users are not familiar with the line of research of the original data.
Easy to Use and Maintain
All the features and benefits discussed above would be for naught without a user-friendly, low-maintenance interface. With a dataverse, data owners can administer all the settings and manage studies through a web interface. Creating a personal web data archive does not require any software installation or special request since a dataverse can be created through a web form from a Dataverse Network. It is then hosted, maintained and upgraded by the Network. This model is becoming increasingly more common as applications are switching to services on the web. (Such applications are often referred to as one form of cloud applications or "software as service".)
Interoperability and Standards
Finally, although data owners and distributors should not be concerned about the system's architecture, a good data-sharing framework must interoperate with other systems and support standards used by other repositories. The DVN imports and exports its study metadata in various XML formats — Data Descriptive Initiative (DDI, version 2), Dublin Core, FGDC, and MARC. It supports the Open Archive Initiative (OAI-PMH) protocol to harvest metadata from one system to another, and interfaces with the LOCKSS (Lots of Copies Keep Stuff Saved) system (Reich and Rosenthal, 2001), which is used by many digital libraries, to preserve and back-up the data by copying them in multiple locations. An individual dataverse can be LOCKSS-enabled so all the owned records are also copied to additional specified locations.
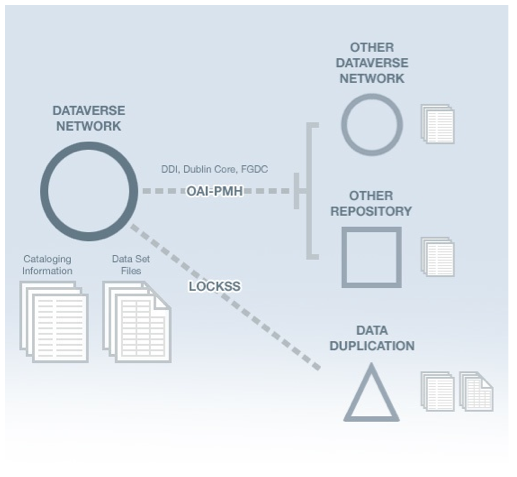
Figure 2. A DVN is federated with other DVNs or other repositories through OAI-PMH. Metadata are exchanged using metadata schema standards such as DDI, Dublin Core and FGDC. Data in a DVN are copied to other locations using LOCKSS preservation software and the OAI protocol.
Support of standards and broadly-used protocols allow a DVN not only to federate with other DVN installations, but also to share data with repositories that use a different technology.
This project is funded by a number of sources. Preservation of data deposited to the IQSS DVN is funded by the Murray Research Archive endowment. Continued development and support of the software are funded by the generosity of various universities, including Harvard University. Additional funding is achieved through grants to develop new features and expand the software to fully support data beyond social science. The DVN software is open source and therefore the project encourages contributions from the software development community and any interested organizations.
Summary
The data sharing initiative is evident and growing. With journals and grant funding agencies starting to require easy access to the data used in research studies, and with more data available for research every day, technology solutions for data sharing are critical. Yet authors need incentives to participate if we want to make data sharing successful. Through data citation, web visibility and ease of use, the Dataverse Network enables data authors to gain recognition and maintain ownership of their data while addressing their data archival concerns through management by a centralized standards-based repository. The features presented here make the dataverse an attractive solution for publishing data and satisfy the requirements for managing and sharing data set by funding agencies and journals.
Note
1 Studies show that data sharing can provide additional scholarly recognition by not only increasing citations to the data, but also increasing citation to the original publication for those research studies that make their data easily accessible (Piwowar et al. 2007).
References
[1] Altman, Micah. 2008. "A Fingerprint Method for Verification of Scientific Data", in Advances in Systems, Computing Sciences and Software Engineering (Proceedings of the International Conference on Systems, Computing Sciences and Software Engineering 2007), Springer Verlag.
[2] Altman, Micah; Andreev, Leonid; Diggory, Mark; Krot, Michael; King, Gary; Kiskis, Daniel ; Sone, Akio; and Verba, Sidney. 2001. "A Digital Library for the Dissemination and Replication of Quantitative Social Science Research", Social Science Computer Review 19(4):458-71.
[3] Altman, Micah and King, Gary. 2007. "A Proposed Standard for the Scholarly Citation of Quantitative Data", D-Lib Magazine 13(3/4). doi:10.1045/march2007-altman.
[4] Altman, M., Adams, M., Crabtree, J., Donakowski, D., Maynard, M., Pienta, A., & Young, C. 2009. "Digital preservation through archival collaboration: The Data Preservation Alliance for the Social Sciences." The American Archivist. 72(1): 169-182.
[5] Brandes, U., Eiglsperger, M., Herman, H., Himsolt, M., and Marshall, M.S. 2002. "GraphML Progress Report: Structural Layer Proposal", Proc. 9th Intl. Symp. Graph Drawing (GD '01), LNCS 2265, pp. 501-512. © Springer-Verlag.
[6] Brandes, M Eiglsperger, J. Lerner. GraphML Primer. 2010. http://graphml.graphdrawing.org/primer/graphml-primer.html.
[7] Fung, B., Wang, K., Chen, R., Yu, P. 2010 "Privacy-Preserving Data Publishing: A Surey of Recent Developments" ACM Computing Surveys, Volume 42, Issue 4, doi:10.1145/1749603.1749605.
[8] King, Gary. 2007. "An Introduction to the Dataverse Network as an Infrastructure for Data Sharing", Sociological Methods & Research, 36(2): 173-199.
[9] Imai, Kosuke, King, Gary and Lau, Olivia. 2008. "Toward A Common Framework for Statistical Analysis and Development", Journal of Computational and Graphical Statistics, Vol. 17, No. 4 (December), pp. 892-913.
[10] Piwowar HA, Day RS, Fridsma DB. 2007 "Sharing Detailed Research Data Is Associated with Increased Citation Rate" PLoS ONE 2(3): e308. doi:10.1371/journal.pone.0000308.
[11] Reich, Vicky and Rosenthal, David S.H. 2001 "LOCKSS: A Permanent Web Publishing and Access System", D-Lib Magazine, June 2001 Volume 7 Number 6. doi:10.1045/june2001-reich.
About the Author
 |
Mercè Crosas is the Director of Product Development at the Institute for Quantitative Social Science (IQSS) at Harvard University. Dr. Crosas first joined IQSS in 2004 (then referred to as the Harvard-MIT Data Center) as manager of the Dataverse Network project. The product development team at IQSS now includes the Dataverse Network project, the Murray Research Archive, and the statistical and web development projects (OpenScholar and Zelig). Before joining IQSS, she worked for about six years in the educational software and biotech industry, initially as a software developer, and later as manager and director of IT and software development. Prior to that, she was at the Harvard-Smithsonian Center for Astrophysics where she completed her doctoral thesis as a student fellow with the Atomic and Molecular Physics Institute, and afterwards she was a post-doctoral fellow, a researcher and a software engineer with the Radioastronomy division. Dr. Crosas holds a Ph.D. in Astrophysics from Rice University and graduated with a B.S. in Physics from the Universitat de Barcelona, Spain. |
|
|
|
| P R I N T E R - F R I E N D L Y F O R M A T | Return to Article |